ChatGPT 拓展资料:ChatGPT 和预训练模型实战课 继续阅读
ChatGPT 拓展资料:ChatGPT 和预训练模型实战课

查询到最新的12条
ChatGPT 拓展资料:ChatGPT 和预训练模型实战课 继续阅读

GPT1:Imporoving Language Understanding By Generative Pre-training GPT2:Lanuage Models Are Unsupervised Multitask Learners GPT3:Language Models Are Few-shot Learners GitHub:https://github.com/openai/gpt-3 从GPT三个版本的论文名也能看出各版本模型的重点: GPT1:强调预训 继续阅读
简介 随着数据科学领域的深入发展,大型语言模型—这种能够处理和生成复杂自然语言的精密人工智能系统—逐渐引发了更大的关注。 LLMs是自然语言处理(NLP)中最令人瞩目的突破之一。这些模型有潜力彻底改变从客服到科学研究等各种行业,但是人们对其能力和局限性的理解尚未全面。 LLMs依赖海量的文本数据进行训练,从而能够生成极其准确的预测和回应。像GPT-3和T5这样的LLMs在诸如语言翻译、问答、以及摘要等多个NLP任务中已经 继续阅读

本文尝试用现在最火的chatGPT在工作中提高生产力。 具体背景如下:在训练模型过程中,为了避免资源抢占,我指定了其他的gpu来提高模型训练效率,但是发现训练的时候模型正常,但是在模型预测的时候一直报错,尝试gpu=1,2,3都报错。gpu=0,或者是不设置都不会出错。 预测的时候具体报错内容如下: XGBoostError: b' 继续阅读
Part1动态 「国内要闻」 其中提到利用AI生成内容应当真实准确,采取措施防止生成虚假信息;提供者应当对生成式人工智能产品的预训练数据、优化训练数据来源的合法性负责等。 知乎发布"知海图 AI" 中文大模 知乎和面壁科技合作的中文大模型“知海图AI”正式开启内测。同时,基于人工智能的“热榜摘要”开启内测,对知乎热榜上的问题回答进行抓取、整理和聚合,并把回答梗概展现给用户。 阿里所有产品将接入大模型全面升级 阿里 继续阅读

国内如何用chatGPT4.0 在国内,目前可以通过以下途径使用 OpenAI 的 ChatGPT 4.0: 自己搭建模型:如果您具备一定的技术能力,可以通过下载预训练模型和相关的开发工具包,自行搭建 ChatGPT 4.0 模型。OpenAI提供了相关的软件开发工具,包括Python API,也有为一些主流应用框架提供可用的API接口。 使用在线应用程序:目前许多国内公司和平 继续阅读

Codex 是 OpenAI 公司推出的 GPT-3(Generative Pre-trained Transformer – 3)的多个派生模型之一。它是基于GPT语言模型,使用代码数据进行 Fine-Tune(微调)而训练出的专门用于代码生成/文档生成的模型。Codex 模型参数从12M到12B不等,是目前最强的编程语言预训练模型。Codex 能够帮助程序员根据函数名和注释自动补全代码、直接生成代码、自动 继续阅读

1. 引言 作者首先阐述了此项研究的目的,那就是开发一个可提示的(promptable)模型,在大型数据集上通过特定的任务对其进行预训练,使之具有很强的泛化性,即能够通过提示(prompt)解决新数据集上的一系列下游分割任务。 实现此目的需要解决的问题包括: 什么样的任务可以具有zero-shot的泛化性?对应的网络结构是怎样的?什么 继续阅读

目录 一.前言 二.下载数据文件 三.导包并设置使用GPU 四.加载和预处理数据 五.为模型准备数据 一.前言 在本教程中,我们探索一个好玩有趣的循环的序列到序列(sequence-to-sequence)的模型用例。我们将用Cornell Movie-Dialogs Corpus 处的电影剧本来训练一个简单的聊天机器人。 在人工智能研究领域中,对话模型是一个非常热门的话题。聊天机器人可以在各种设置中找到ÿ 继续阅读

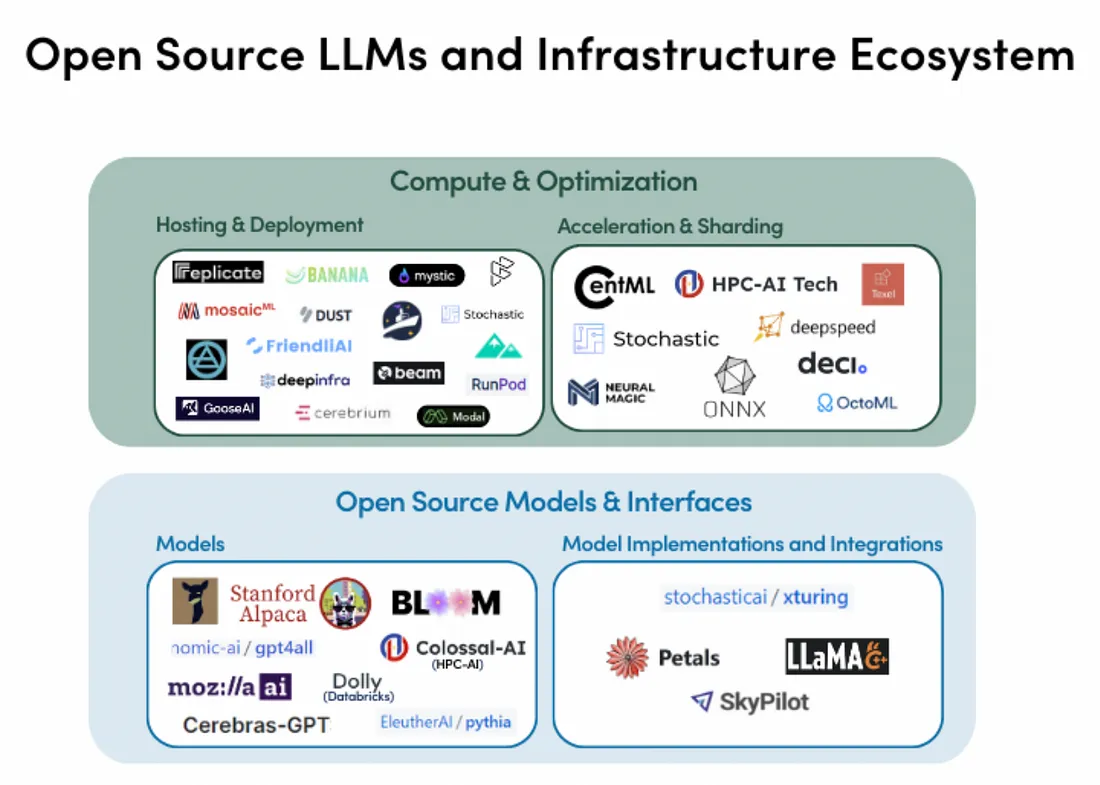
自从ChatGPT出现之后,各种大语言模型是彻底被解封了,每天见到的模型都能不重样,几乎分不清这些模型是哪个机构发布的、有什么功能特点、以及这些模型的关系。比如 GPT-3.0 和 GPT 3.5 就有一系列的模型版本和索引,还有羊驼、小羊驼、骆驼 ...... 于是浅浅的调研了一下比较有名的大语言模型,主要是想混个脸熟,整理完之后就感觉清晰多了,又可以轻松逛知乎学习了。 一. Basic Language Model 基础语言模型是指只在大规模文本语料中进行了预训练的 继续阅读
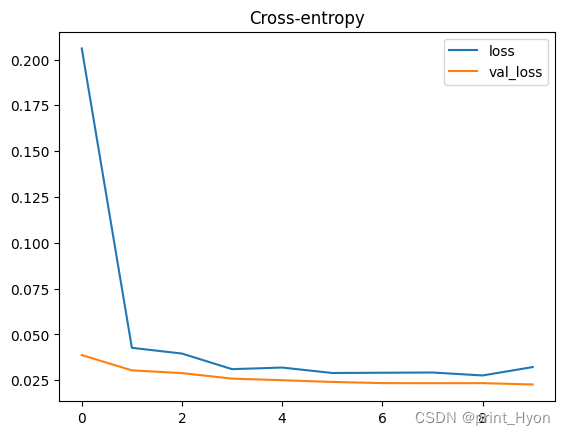
竞赛介绍 数据集描述 本次竞赛的数据集(训练和测试)是从根据机器故障预测训练的深度学习模型生成的。特征分布与原始分布接近,但不完全相同。随意使用原始数据集作为本次竞赛的一部分,既可以探索差异,也可以了解在训练中合并原始数据集是否可以提高模型性能。 文件 训练.csv - 训练数据集; 是(二进制)目标(为了与原始数据集的顺序保持一致,它不在最后一列位置࿰ 继续阅读

前言 ChatGPT基本信息&原理 ChatGPT基本信息 研发公司:OpenAI 创立年份:2015年 创立人:马斯克、Sam Altman及其他投资者 目标:造福全人类的AI技术 GPT(Generative Pre-trained Transformer):生成式预训练语言模型 GPT作用:问答,生成文章等 模型发展史 参数量(单位:亿) 预训练数据量( 继续阅读