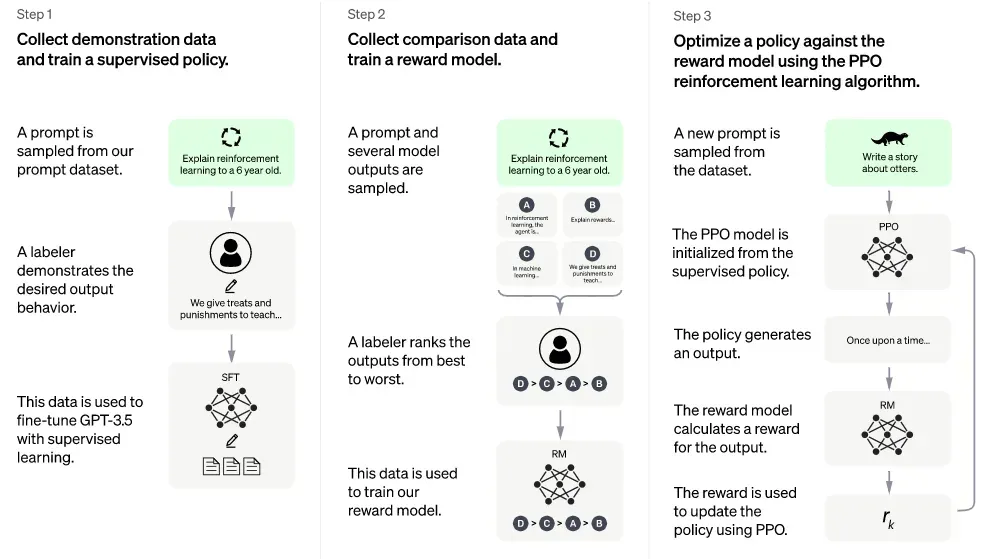
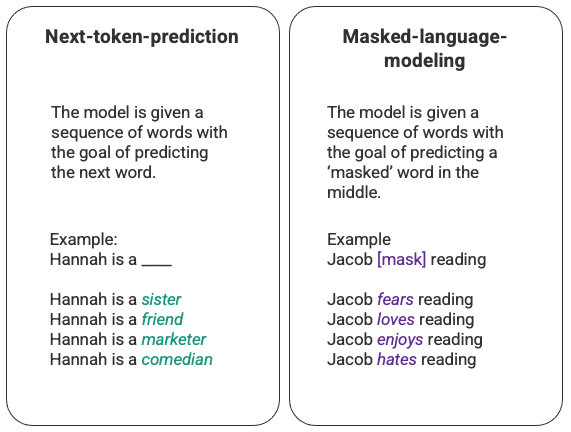
ChatGPT基础知识系列之大型语言模型(LLM)初识 ChatGPT本质是一个对话模型,它可以回答日常问题、挑战不正确的前提,甚至会拒绝不适当的请求,在去除偏见和安全性上不同于以往的语言模型。ChatGPT从闲聊、回答日常问题,到文本改写、诗歌小说生成、视频脚本生成,以及编写和调试代码均展示了其令人惊叹的能力。在OpenAI公布博文和试用接口后,ChatGPT很快以令人惊叹的对话能力“引爆”网络,本文主要从技术角度,梳理ChatGPT背后涉及的技术工作LLM,来阐述其如此强大的原因;同时思考 继续阅读
ChatGPT基础知识系列之大型语言模型(LLM)初识