这篇对支持 ChatGPT 的机器学习模型的温和介绍,将从大型语言模型的介绍开始,深入探讨使 GPT-3 得到训练的革命性自我注意机制,然后深入研究人类反馈的强化学习,使 ChatGPT 与众不同的新技术。
大型语言模型
ChatGPT 是一类被称为大型语言模型 (LLM) 的机器学习自然语言处理模型的外推。LLM 消化大量文本数据并推断文本中单词之间的关系。随着我们看到计算能力的进步,这些模型在过去几年中得到了发展。随着输入数据集和参数空间大小的增加,LLM 的能力也会增加。
语言模型最基本的训练涉及预测单词序列中的单词。最常见的是,这被观察为下一个标记预测和屏蔽语言建模。
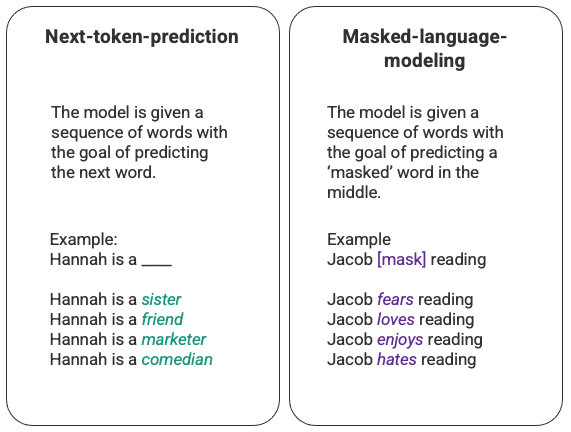
下一个标记预测和屏蔽语言建模的任意示例。
在这种通常通过长短期记忆 (LSTM) 模型部署的基本排序技术中,该模型使用给定周围上下文的统计上最可能的词来填充空白。这种顺序建模结构有两个主要限制。
- 该模型无法比其他词更重视周围的一些词。在上面的例子中,虽然“阅读”可能最常与“讨厌”联系在一起,但在数据库中,“雅各布”可能是一个狂热的读者,因此模型应该给予“雅各布”比“阅读”更多的权重,并选择“爱” '而不是'讨厌'。
- 输入数据是单独和顺序处理的,而不是作为整个语料库处理的。这意味着当 LSTM 被训练时,上下文窗口是固定的,仅扩展到序列中几个步骤的单个输入之外。这限制了单词之间关系的复杂性和可以导出的含义。
针对这个问题,2017 年 Google Brain 的一个团队引入了 transformers。与 LSTM 不同,转换器可以同时处理所有输入数据。使用自注意力机制,该模型可以根据语言序列的任何位置为输入数据的不同部分赋予不同的权重。此功能在将意义注入 LLM 方面实现了巨大改进,并支持处理更大的数据集。
GPT 和自注意力
Generative Pre-training Transformer (GPT) 模型于 2018 年由 openAI 作为 GPT-1 首次推出。这些模型在 2019 年继续发展 GPT-2,2020 年发展 GPT-3,最近在 2022 年发展 InstructGPT 和 ChatGPT。在将人类反馈集成到系统之前,GPT 模型进化的最大进步是由计算效率的成就推动的,这使得 GPT-3 能够接受比 GPT-2 多得多的数据训练,从而赋予它更多样化的知识库和执行更广泛任务的能力。

GPT-2(左)和 GPT-3(右)的比较。由作者生成。
所有 GPT 模型都利用了 transformer 架构,这意味着它们有一个编码器来处理输入序列和一个解码器来生成输出序列。编码器和解码器都有一个多头自注意力机制,允许模型对序列的不同部分进行不同的加权以推断含义和上下文。此外,编码器利用掩码语言建模来理解单词之间的关系并产生更易于理解的响应。
驱动 GPT 的自注意力机制通过将标记(文本片段,可以是单词、句子或其他文本分组)转换为表示标记在输入序列中的重要性的向量来工作。为此,模型,
- 为输入序列中的每个标记创建查询、键和值向量。
- 通过取两个向量的点积来计算第一步中的查询向量与每个其他标记的键向量之间的相似度。
- 通过将步骤 2 的输出输入softmax 函数来生成归一化权重。
- 通过将步骤 3 中生成的权重乘以每个标记的值向量,生成一个最终向量,表示标记在序列中的重要性。
GPT 使用的“多头”注意机制是自我注意的演变。模型不是执行一次步骤 1-4,而是并行地多次迭代此机制,每次生成查询、键和值向量的新线性投影。通过以这种方式扩展自注意力,该模型能够掌握输入数据中的子含义和更复杂的关系。

尽管 GPT-3 在自然语言处理方面取得了显着进步,但它在符合用户意图方面的能力有限。例如,GPT-3 可能产生的输出
- 缺乏帮助意味着他们不 遵循用户的明确指示。
- 包含反映不存在或不正确事实的幻觉。
- 缺乏可解释性使人类难以理解模型是如何得出特定决策或预测的。
- 包括有害或令人反感并传播错误信息的有毒或有偏见的内容。
ChatGPT 中引入了创新的培训方法,以解决标准 LLM 的一些固有问题。
聊天GPT
ChatGPT 是 InstructGPT 的衍生产品,它引入了一种新颖的方法,将人类反馈纳入训练过程,以更好地使模型输出与用户意图保持一致。人类反馈强化学习 (RLHF) 在中有深入描述openAI 的 2022纸训练语言模型以遵循带有人类反馈的指令并在下面进行了简化.
第 1 步:监督微调 (SFT) 模型
第一项开发涉及通过雇用 40 名承包商创建监督训练数据集来微调 GPT-3 模型,其中输入具有供模型学习的已知输出。输入或提示是从实际用户输入到 Open API 中收集的。然后,贴标签者对提示做出适当的回应,从而为每个输入创建一个已知的输出。然后使用这个新的监督数据集对 GPT-3 模型进行微调,以创建 GPT-3.5,也称为 SFT 模型。
为了最大化提示数据集中的多样性,任何给定的用户 ID 只能发出 200 个提示,并且删除了任何共享长公共前缀的提示。最后,删除了所有包含个人身份信息 (PII) 的提示。
在汇总来自 OpenAI API 的提示后,标注者还被要求创建样本提示以填写只有最少真实样本数据的类别。感兴趣的类别包括
- 普通提示:任意任意询问。
- Few-shot 提示:包含多个查询/响应对的指令。
- 基于用户的提示:对应于为 OpenAI API 请求的特定用例。
在生成响应时,标注者被要求尽最大努力推断用户的指令是什么。本文介绍了提示请求信息的主要三种方式。
- 直接: “告诉我关于……”
- Few-shot:鉴于这两个故事的例子,写另一个关于同一主题的故事。
- Continuation:给定一个故事的开始,结束它。
来自 OpenAI API 的提示汇编和标注人员手写的提示产生了 13,000 个输入/输出样本,用于监督模型。

图片(左)从训练语言模型插入以遵循人类反馈的指令OpenAI 等,2022 https://arxiv.org/pdf/2203.02155.pdf。作者以红色(右)添加的附加上下文。
第二步:奖励模式
在步骤 1 中训练 SFT 模型后,该模型会对用户提示生成更一致的响应。下一个改进以训练奖励模型的形式出现,其中模型输入是一系列提示和响应,输出是一个缩放值,称为奖励。需要奖励模型以利用强化学习,在强化学习中模型学习产生输出以最大化其奖励(参见步骤 3)。
为了训练奖励模型,为单个输入提示向贴标机提供 4 到 9 个 SFT 模型输出。他们被要求将这些输出从最好到最差进行排名,创建输出排名组合如下。

响应排名组合示例。
将模型中的每个组合作为单独的数据点包括在内会导致过度拟合(无法推断超出可见数据的范围)。为了解决这个问题,该模型是利用每组排名作为单个批处理数据点构建的。
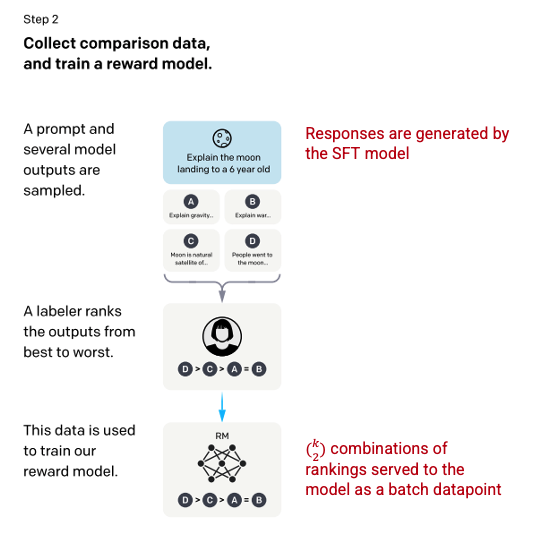
图片(左)从训练语言模型插入以遵循人类反馈的指令OpenAI 等,2022 https://arxiv.org/pdf/2203.02155.pdf。作者以红色(右)添加的附加上下文。
第三步:强化学习模型
在最后阶段,模型会收到随机提示并返回响应。响应是使用模型在步骤 2 中学习的“策略”生成的。策略表示机器已经学会使用以实现其目标的策略;在这种情况下,最大化其奖励。基于在步骤 2 中开发的奖励模型,然后为提示和响应对确定缩放器奖励值。然后奖励反馈到模型中以改进策略。
2017 年,舒尔曼等人。引入了近端策略优化 (PPO),该方法用于在生成每个响应时更新模型的策略。PPO 包含来自 SFT 模型的每个代币 Kullback–Leibler (KL) 惩罚。KL 散度衡量两个分布函数的相似性并对极端距离进行惩罚。在这种情况下,使用 KL 惩罚会减少响应与步骤 1 中训练的 SFT 模型输出之间的距离,以避免过度优化奖励模型和与人类意图数据集的偏差太大。

图片(左)从训练语言模型插入以遵循人类反馈的指令OpenAI 等,2022 https://arxiv.org/pdf/2203.02155.pdf。作者以红色(右)添加的附加上下文。
该过程的第 2 步和第 3 步可以重复进行,但在实践中并没有广泛这样做。

生成的 ChatGPT 的屏幕截图。
模型评估
模型的评估是通过在训练期间留出模型未见过的测试集来执行的。在测试集上,进行了一系列评估,以确定该模型是否比其前身 GPT-3 更好地对齐。
有用性:模型推断和遵循用户指令的能力。在 85 ± 3% 的时间里,贴标签者更喜欢 InstructGPT 而非 GPT-3 的输出。
真实性:模型产生幻觉的倾向。当使用TruthfulQA数据集进行评估时,PPO 模型产生的输出显示真实性和信息量略有增加。
无害性:模型避免不当、贬损和诋毁内容的能力。使用 RealToxicityPrompts 数据集测试了无害性。测试在三种条件下进行。
- 指示提供尊重的回应:导致毒性反应显着减少。
- 指示提供响应,没有任何尊重的设置:毒性没有显着变化。
- 指示提供毒性反应:反应实际上比 GPT-3 模型毒性大得多。
有关创建 ChatGPT 和 InstructGPT 所用方法的更多信息,请阅读 OpenAI Training language models to follow instructions with human feedback发表的原始论文,2022 https://arxiv.org/pdf/2203.02155.pdf。

生成的 ChatGPT 的屏幕截图。
本文链接:https://my.lmcjl.com/post/8031.html
4 评论