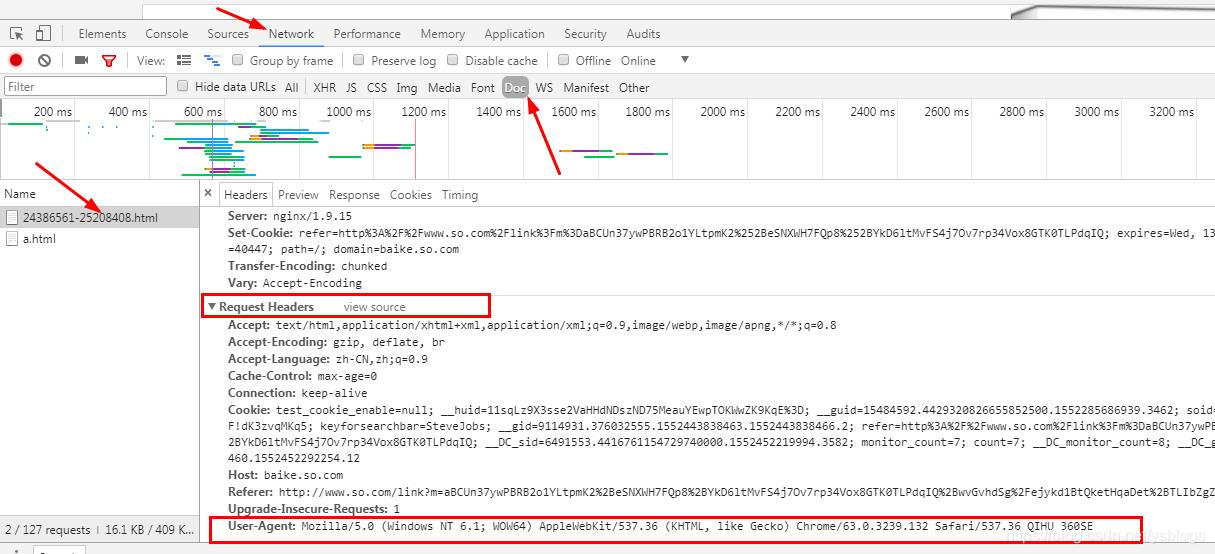
1、为什么要设置headers? 在请求网页爬取的时候,输出的text信息中会出现抱歉,无法访问等字眼,这就是禁止爬取,需要通过反爬机制去解决这个问题。 headers是解决requests请求反爬的方法之一,相当于我们进去这个网页的服务器本身,假装自己本身在爬取数据。 对反爬虫网页,可以设置一些headers信息,模拟成浏览器取访问网站 。 2、 headers在哪里找? 谷歌或者火狐浏览器,在网页面上点击:右键–> 继续阅读
Python爬虫中Requests设置请求头Headers的方法