1、为什么要设置headers?
在请求网页爬取的时候,输出的text信息中会出现抱歉,无法访问等字眼,这就是禁止爬取,需要通过反爬机制去解决这个问题。
headers是解决requests请求反爬的方法之一,相当于我们进去这个网页的服务器本身,假装自己本身在爬取数据。
对反爬虫网页,可以设置一些headers信息,模拟成浏览器取访问网站 。
2、 headers在哪里找?
谷歌或者火狐浏览器,在网页面上点击:右键–>检查–>剩余按照图中显示操作,需要按Fn+F5刷新出网页来
有的浏览器是点击:右键->查看元素,刷新
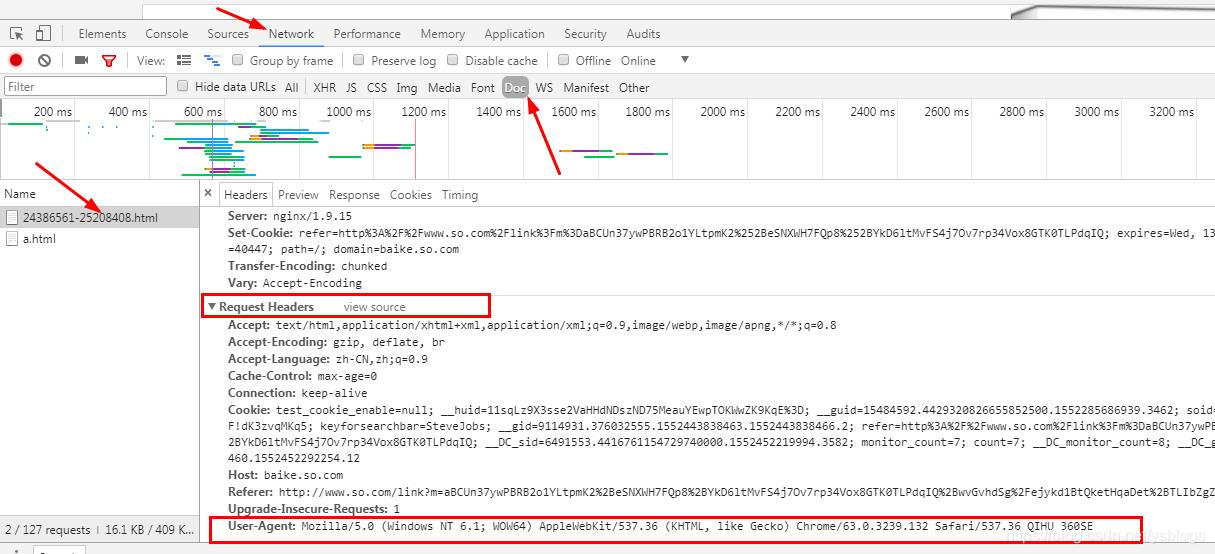
注意:headers中有很多内容,主要常用的就是user-agent 和 host,他们是以键对的形式展现出来,如果user-agent 以字典键对形式作为headers的内容,就可以反爬成功,就不需要其他键对;否则,需要加入headers下的更多键对形式。
用Python下载一个网页保存为本地的HTML文件实例1-中文网页
?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
|
用Python下载一个网页保存为本地的HTML文件实例2-英文网页
?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
到此这篇关于Python爬虫中Requests设置请求头Headers的方法的文章就介绍到这了,更多相关Python Requests设置请求头Headers内容请搜索服务器之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持服务器之家!
原文链接:https://blog.csdn.net/ysblogs/article/details/88530124
本文链接:https://my.lmcjl.com/post/2853.html
4 评论