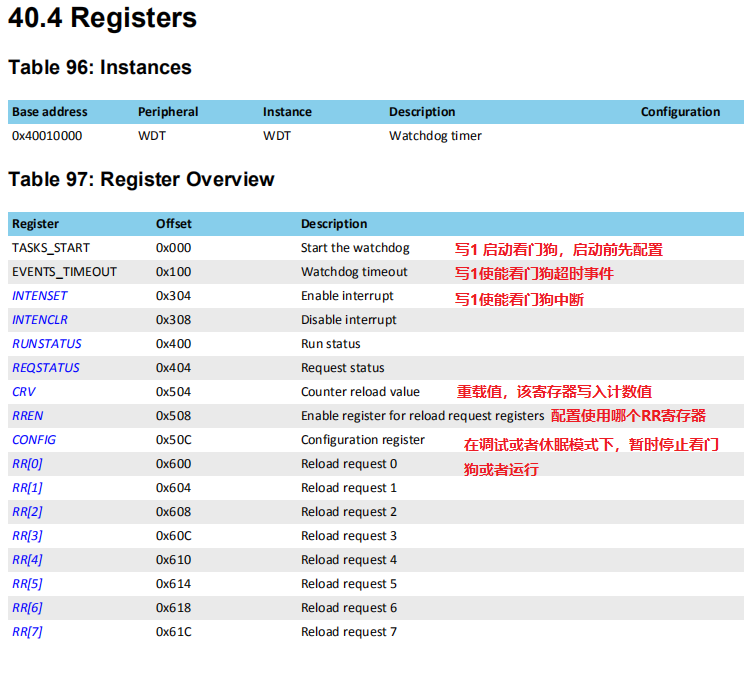
nRF52832 看门狗 使用 低频时钟源(LFCLK)提供时钟,是向下计数的定时器。 启动后,看门狗加载 CRV 寄存器中的指定值。然后开始计数,当计数到0后,会溢出产生 TIMEOUT 事件。看门狗 TIMEOUT 事件会导致系统复位 或者 TIMEOUT 中断。 看门狗的超时时间: timeout [s] = ( CRV + 1 ) / 32768 看门狗喂狗的方式࿱ 继续阅读
nRF52832学习记录(八、WDT看门狗 )