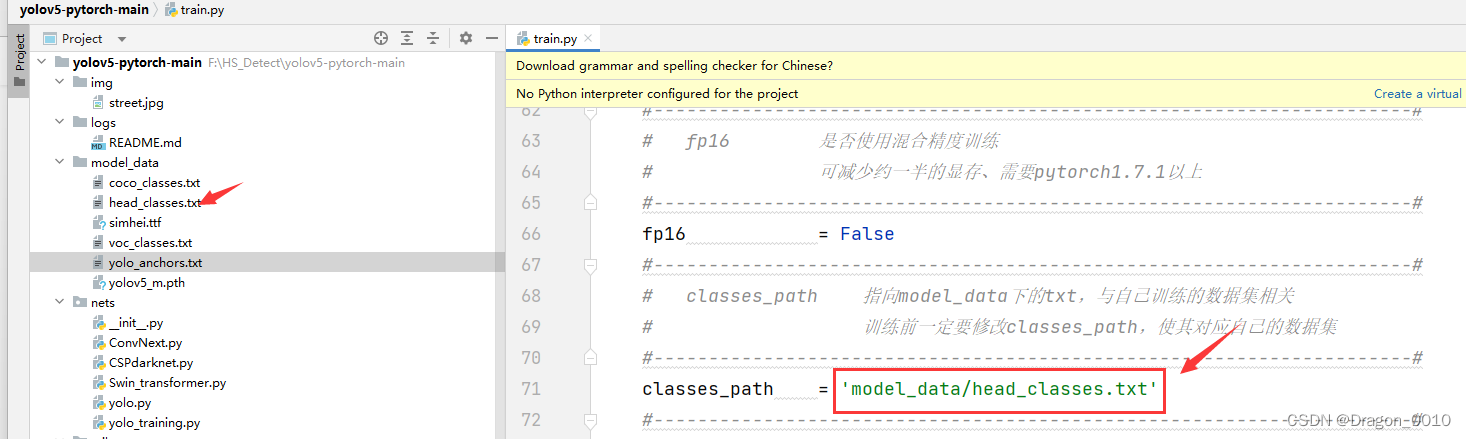
1.源码下载链接 1.yolov5原模型以及权重文件 链接:https://pan.baidu.com/s/1XlvHIxlzJEqp2wlRx5Fb1w 提取码:xtkj 2.训练自己数据集的完整代码 链接:https://pan.baidu.com/s/1xdnah8ZLoT7E1YDm-RiGzQ 提取码:9261 2.训练过程 1.修改class_path为自己数据集的分类结果 2.修改权重文件的路径 继续阅读
使用yolov5训练自己的数据集并测试效果