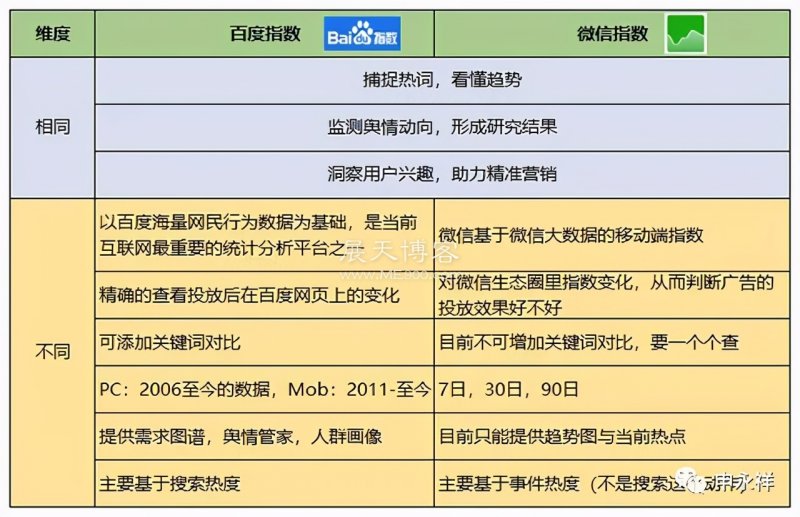
我们要做好微信SEO,不能单纯考虑微信指数分析或者只看百度指数高低,而要结合2种指数的不同性质,去综合分析研究,找到最理想的目标关键词和优化方面。 一、什么是百度指数 百度指数(Baidu Index)是以百度海量网民行为数据为基础的数据分析平台,是当前互联网乃至整个数据时代最重要的统计分析平台之一,自发布之日便成为众多企业营销决策的重要依据。 “世界很复杂,百度更懂你”,百度指数能够告诉用户:某个关键词在百度的搜索规模有多大,一段时间内 继续阅读
微信指数千牛帮,微信指数和百度指数哪个靠谱
查询到最新的12条
我们要做好微信SEO,不能单纯考虑微信指数分析或者只看百度指数高低,而要结合2种指数的不同性质,去综合分析研究,找到最理想的目标关键词和优化方面。 一、什么是百度指数 百度指数(Baidu Index)是以百度海量网民行为数据为基础的数据分析平台,是当前互联网乃至整个数据时代最重要的统计分析平台之一,自发布之日便成为众多企业营销决策的重要依据。 “世界很复杂,百度更懂你”,百度指数能够告诉用户:某个关键词在百度的搜索规模有多大,一段时间内 继续阅读
目录ChatGPT的技术路线基于 GPT-3.5,GPT-4 预计提升更明显GPT、Bert 均源自 Transformer 模型领先的 NLP 模型RLHF 与 TAMER 是重要架构支撑 ChatGPT的技术路线 基于 GPT-3.5,GPT-4 预计提升更明显 ChatGPT 是基于 GPT-3.5 的主力模型。在互联网开源数据集上进行训练,引入人工数据标注和强化学习两项功能,实现“从人类反馈中强化学习”。相比之前的模 继续阅读
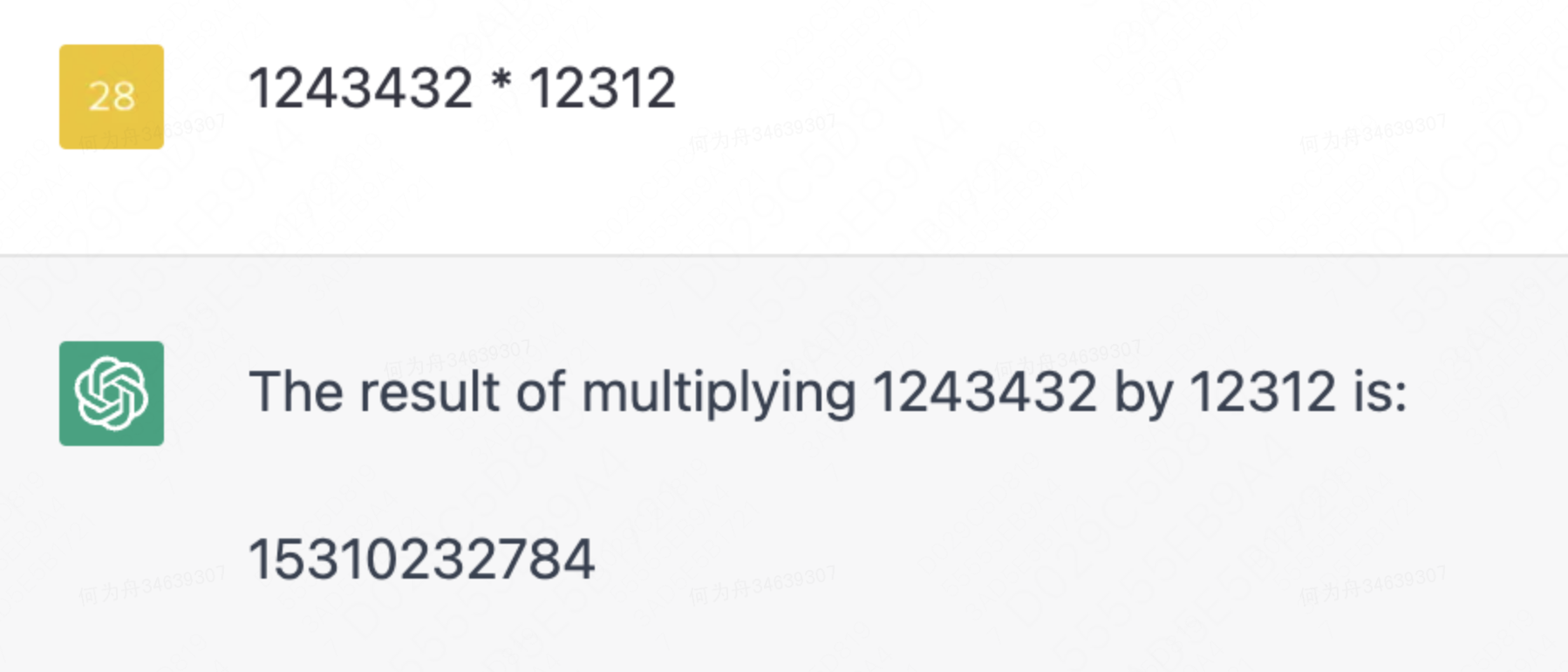
0、为什么会对ChatGPT感兴趣一开始,我对ChatGPT是没什么关注的,无非就是有更大的数据集,完成了更大规模的计算,所以能够回答更多的问题。但后来了解到几个案例,开始觉得这个事情并不简单。我先分别列举出来,具体解读在文末说明。1)ChatGPT能够进行数学运算,但大数运算和复杂运算,基本都会出错。2)ChatGPT能够解读出最新的网站内容。࿰ 继续阅读

这个问题很有意思。 当前的 ChatGPT 模型并没有真正的意识,它只是根据训练数据和算法生成回答。在当前的技术水平下,人工智能不具备自我意识和自我决策的能力,也无法脱离其预先设定的目标进行行动。 然而,随着人工智能技术的发展,这种情况可能会发生变化。为了管好以 ChatGPT 为代表的人工智能让它们为人类更好的服务,我们需要建立完善的监管机制。 这些机制可能包括: 人工智能研究和开发的 继续阅读

概要 随着云计算和虚拟化技术的快速发展,数据中心网络正面临着越来越大的挑战。传统的网络架构在适应大规模数据中心的需求方面存在一些限制,如扩展性、隔离性和灵活性等方面。为了克服这些限制,并为数据中心网络提供更好的性能和可扩展性,VXLAN(Virtual Extensible LAN)作为一种新兴的网络虚拟化技术应运而生。本文将详细介绍VXLAN的工作原理、优势以及在数据中心网络中的应用ÿ 继续阅读
最近在日常的工作和跟客户的交流中,频繁谈及“数据编织”这个词,我开始关注数据编织是源于对主动式数据治理和数据编排的研究,从现在的趋势来看,数据编织显然已经进入落地阶段。数据编织正在从一个概念、一个理念向一线生产场景演进,正在加速产品化和实战化。其实数据编织不是一个特别新的词,Gartner在2022年的重要战略技术趋势报告里面,第三次把数据编织列为十大技术趋势之一。 一、数据编织产生的背景 继续阅读

文章目录1.RLHF方法2.ChatGPT中的RLHF方法2.1 微调模型GPT-32.2 训练奖励模型2.3 利用强化学习进一步微调语言模型3.效果4.面临挑战5.参考 InstructGPT语言模型,是一个比 GPT-3 更善于遵循用户意图,同时使用通过我们的对齐研究开发的技术使它们更真实、毒性更小。InstructGPT 模型循环迭代的过程当中,加入了人类反馈进行训练。 比如下面的例子:几句话向6岁的孩子解析登月 可以看 继续阅读

一、学习目标 二、选择&填空&判断(基础知识 数据库安全性概述 -数据库的安全性是指保护数据库以防止不合法使用所造成的数据泄露、更改或破坏。 -威胁数据库安全的因素:非授权用户对数据库的恶意存取和破坏、数据库中重要或敏感的数据被泄露、安全环境的脆弱性 –DBMS提供的安全措施主要包括用户身份鉴别、存取控制和视图等技术。 -DBMS提供的主要技术有强制存取控制、数据加密存储和加密传输等审计日志 -TCSEC标准 C2 B1 要重点看一下 - 继续阅读

©PaperWeekly 原创 · 作者 | 愁云引言随着 ChatGPT 的横空出世,智能对话大模型俨然已成为 AI 发展的焦点,更是在整个自然语言处理 (NLP) 领域掀起了一阵海啸。自去年席卷全球以来便引起各行各业空前的热度,数亿用户纷纷惊叹于 ChatGPT 的强大功能,思考其背后关键技术革新,也关注当前 ChatGPT 仍存在哪些缺陷,除了巨量数据资源的耗费需求,无法与时俱进关联最新信息等 继续阅读
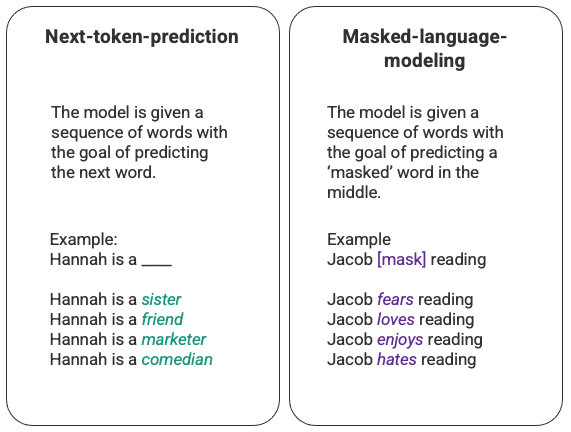
这篇对支持 ChatGPT 的机器学习模型的温和介绍,将从大型语言模型的介绍开始,深入探讨使 GPT-3 得到训练的革命性自我注意机制,然后深入研究人类反馈的强化学习,使 ChatGPT 与众不同的新技术。 大型语言模型 ChatGPT 是一类被称为大型语言模型 (LLM) 的机器学习自然语言处理模型的外推。LLM 消化大量文本数据并推断文本中单词之间的关系。随着我们看到计算能力的进步,这些模型在过去几年中得到了发展。随 继续阅读

这个网赚博客自建立以来,前面几个月的时间基本上都是日更状态,高峰的时候一天大概可以更新5-6篇文章。 所以网站运营的数据相对来说还是非常不错,网站始终保持在一个比较好的状态,没有什么竞争难度的关键词基本上只要写出来,都是当天或隔天收录,收录即参与排名,所以网站数据看起来还是比较可以的。 而网站达到当天收录,小时级收录这个过程大概花了三个月的时间养出来的,当然其中也遇到了比较多的糟心事,网站短时间降权,原创文章被人采集,导致搜索引擎重 继续阅读
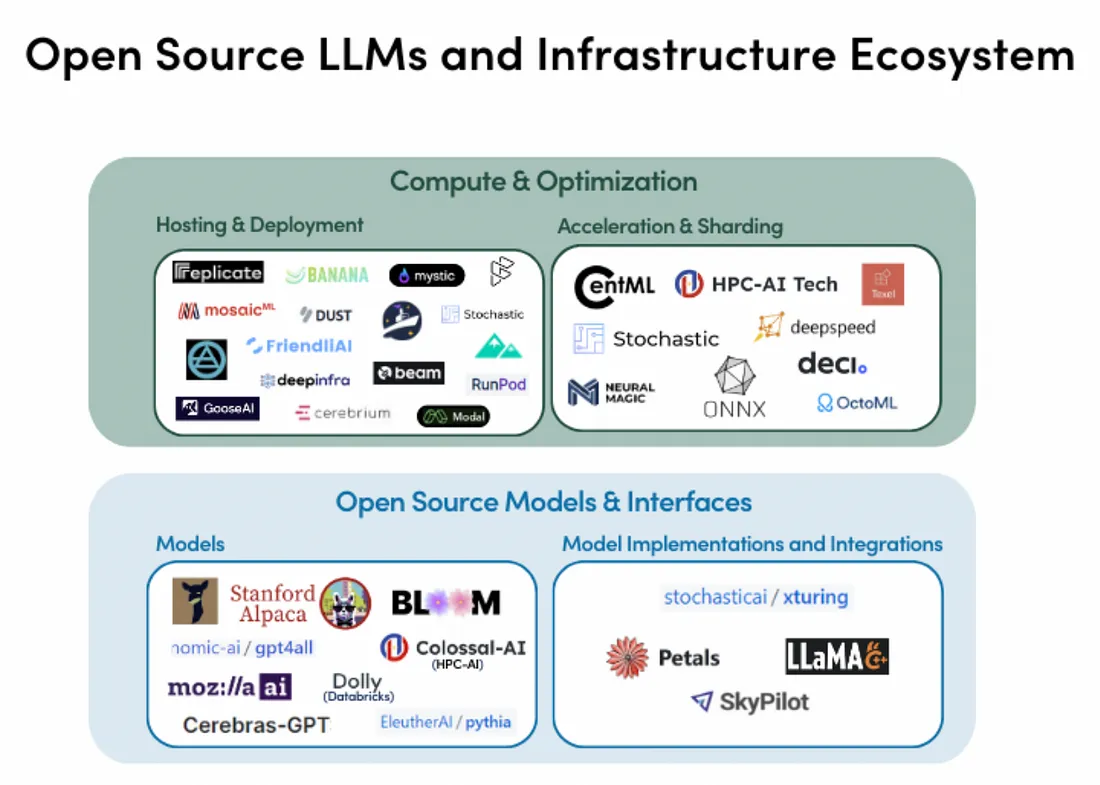
简介 随着数据科学领域的深入发展,大型语言模型—这种能够处理和生成复杂自然语言的精密人工智能系统—逐渐引发了更大的关注。 LLMs是自然语言处理(NLP)中最令人瞩目的突破之一。这些模型有潜力彻底改变从客服到科学研究等各种行业,但是人们对其能力和局限性的理解尚未全面。 LLMs依赖海量的文本数据进行训练,从而能够生成极其准确的预测和回应。像GPT-3和T5这样的LLMs在诸如语言翻译、问答、以及摘要等多个NLP任务中已经 继续阅读