pytorch会自动求导,但是当遇到无法自动求导的时候,需要自己认为定义求导过程,这个时候就涉及到要定义自己的forward和backward函数。
举例如下:
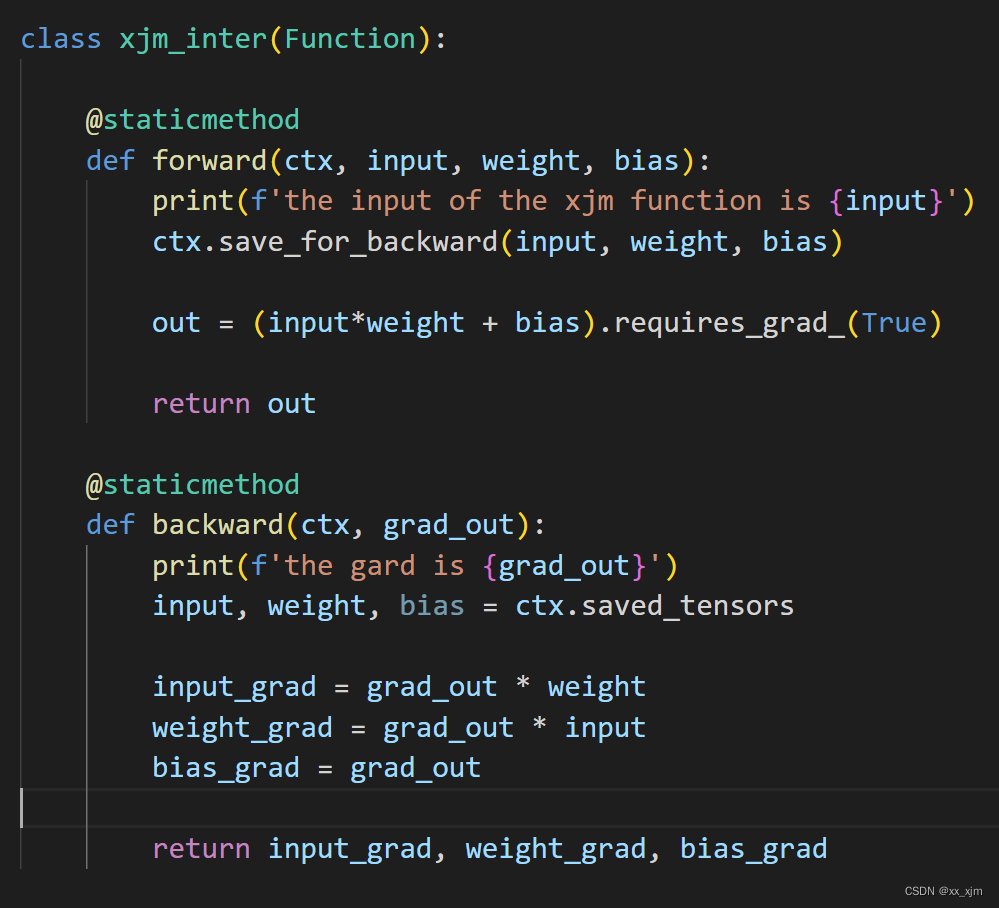
看到这里,大家应该会有很多疑问,比如:
1:ctx.save_for_backward和ctx.saved_tensors的含义
2:backward中各个计算函数的意义,以及backward的输入参数grad_out是什么,以及grad_out包含哪些数据。
针对以上问题,我们一个个解答:
第一个问题:百度吧,答案很多!!!!
第二个问题:拿上面这个例子来看,我们定义了一个类似于线性层的东西,但注意这不是线性层,因为我们是直接把输入和weight用*来做点对点的乘法的,所以这不是我们通常情况下的线性层。
但是这么看也费劲,我们写一个网络,把这个函数加到网络中去,再完整的跑一遍看吧!
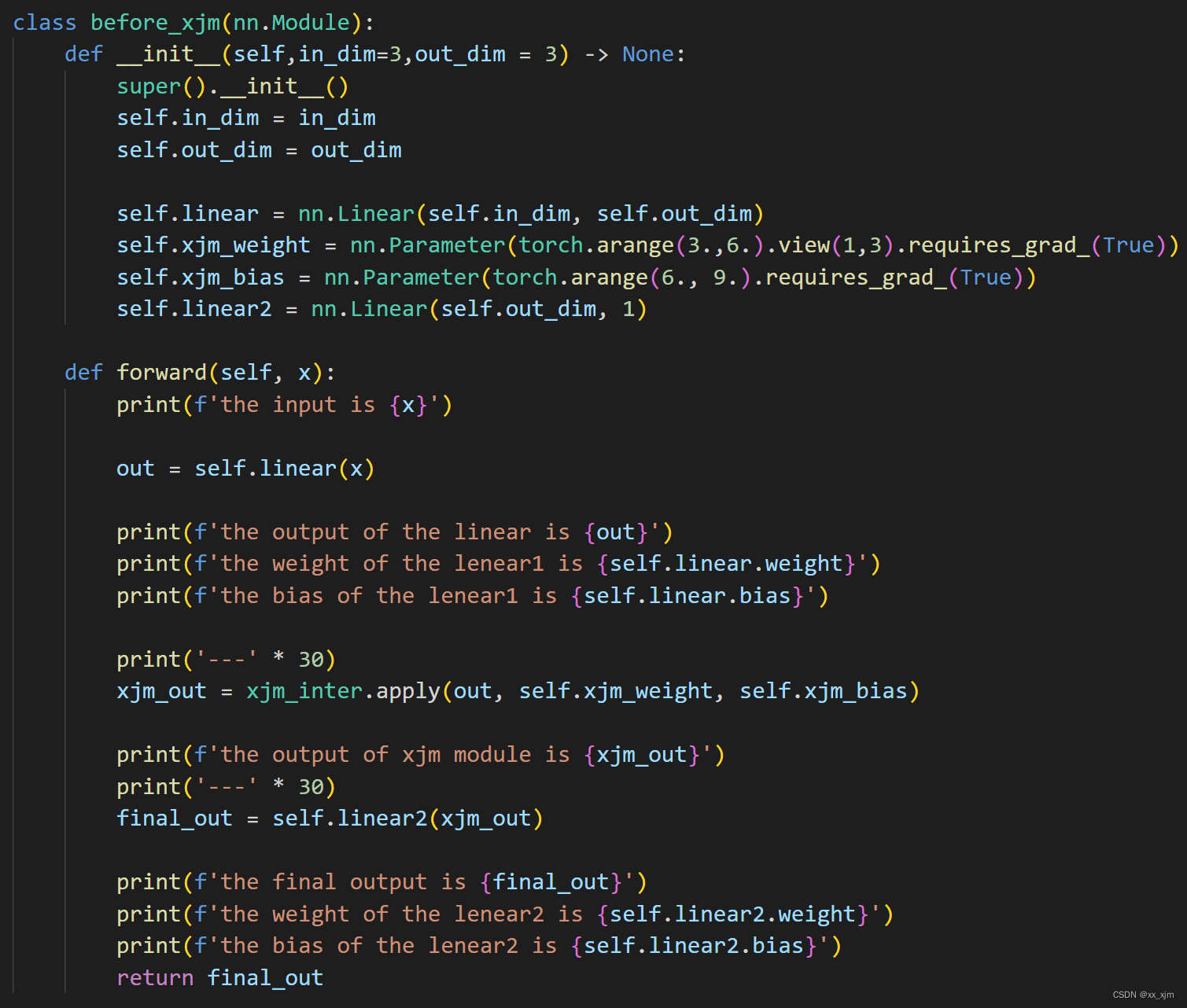
测试代码:

结果如下:
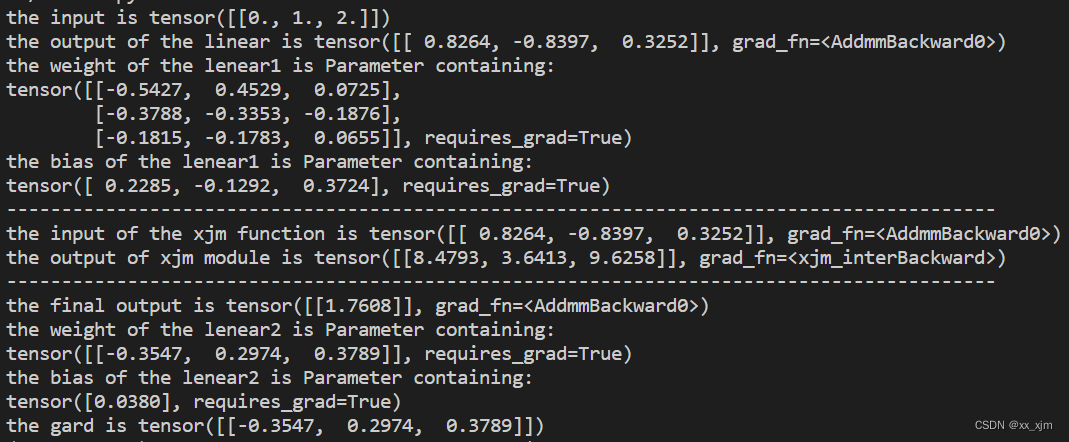
现在,来进行解答:
首先,backward函数的返回值,就是对应着forward里面的参数的梯度,也就是说,forward函数里面有几个输入参数,那么backward函数的输出就要有几个!为什么是这样?
我们首先要理解backward的输入grad_out,为什么backward的参数就是一个,因为这是根据链式法则来的
比如,我们定义三个函数H(对应上面网络中linear1),F(自定义函数xjm_inter),D(对应上面网络中linear2),定义一个输入x(对应上面输入a),定义一个输出y(对应上面输出b):
y = D(F(H(X)))
现在,我们求y对x的偏导,那么:
dy/dx = dy/dD * dD/dF * dF/dH * dH/dx
好吧看到这里你可能还是不懂,为什么backward的参数就是一个grad_out!!
我们韩式以上面则个函数为例子,但是,我们现在不求y对x的导数,我们假设F函数有一个叶子节点(或者说requires_grad=True)的参数w1,现在我们要求y对w1的导数:
所以dy/dw1 = dy/dD *dD/dF * dF/dw1。
那么此时,F就是我们上面代码中自定义的xjm_inter函数,则 grad_out = dy/dD *dD/dF。
怎么理解呢,根据链式法则,我们呢所定义的网络中的每一层都是一个单独的函数,所以函数中的变量的最终求导其实只取决于该函数本身,链式法则求导传递过来的其实永远都知识一个值,这就是为什么backward函数的输出只有一个。
那么我们的backward要实现什么样的功能呢?说到这里,大家应该大概能明白了,就是实现当前层那的梯度计算,并进行返回,所以,这也是为什么backward的返回值要和forward的输入值一一对应,否则会报错。
本文链接:https://my.lmcjl.com/post/11358.html
4 评论