深度学习笔记(6)全连接层的实现:全连接层的每一个结点都与上一层的所有结点相连,用来把前边提取到的特征综合起来。由于其全相连的特性,一般全连接层的参数也是最多的。
全连接层的前向计算
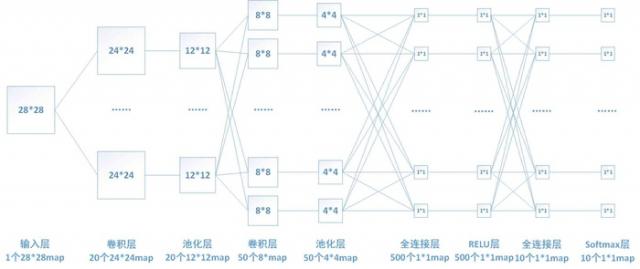
下图中连线最密集的2个地方就是全连接层,这很明显的可以看出全连接层的参数的确很多。在前向计算过程,也就是一个线性的加权求和的过程,全连接层的每一个输出都可以看成前一层的每一个结点乘以一个权重系数W,最后加上一个偏置值b得到,即 。如下图中第一个全连接层,输入有50*4*4个神经元结点,输出有500个结点,则一共需要50*4*4*500=400000个权值参数W和500个偏置参数b。

下面用一个简单的网络具体介绍一下推导过程
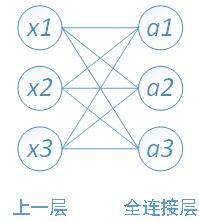
其中,x1、x2、x3为全连接层的输入,a1、a2、a3为输出,根据我前边在笔记1中的推导,有
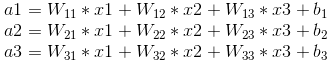
可以写成如下矩阵形式:
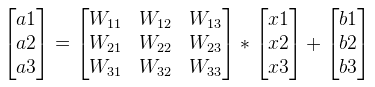
全连接层的反向传播
以我们的第一个全连接层为例,该层有50*4*4=800个输入结点和500个输出结点。
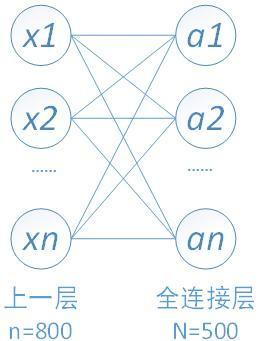
由于需要对W和b进行更新,还要向前传递梯度,所以我们需要计算如下三个偏导数。
1、对上一层的输出(即当前层的输入)求导
若我们已知转递到该层的梯度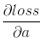 ,则我们可以通过链式法则求得loss对x的偏导数。
,则我们可以通过链式法则求得loss对x的偏导数。
首先需要求得该层的输出ai对输入xj的偏导数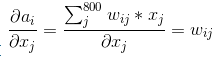
再通过链式法则求得loss对x的偏导数: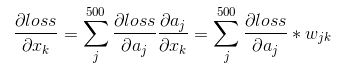
上边求导的结果也印证了我前边那句话:在反向传播过程中,若第x层的a节点通过权值W对x+1层的b节点有贡献,则在反向传播过程中,梯度通过权值W从b节点传播回a节点。
若我们的一次训练16张图片,即batch_size=16,则我们可以把计算转化为如下矩阵形式。
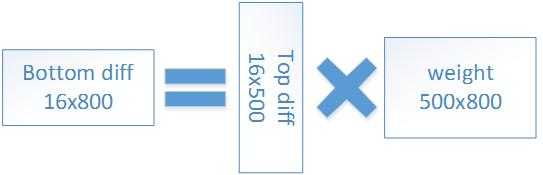
2、对权重系数W求导
我们前向计算的公式如下图,
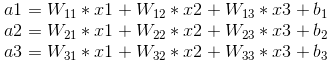
由图可知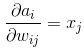 ,所以:。
,所以:。
当batch_size=16时,写成矩阵形式:

3、对偏置系数b求导
由上面前向推导公式可知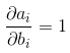 ,
,
即loss对偏置系数的偏导数等于对上一层输出的偏导数。
当batch_size=16时,将不同batch对应的相同b的偏导相加即可,写成矩阵形式即为乘以一个全1的矩阵:

本文链接:https://my.lmcjl.com/post/16668.html
4 评论