最近,FacebookResearch 开源了他们最新的大语言模型 LLaMA,训练使用多达14,000 tokens 语料,包含不同大小参数量的模型 7B、13B 、30B、 65B,研究者可以根据自身算力配置进行选择。
经过测试,(1)在算力要求上,7B的模型,需要19G显存要求,单卡3090可部署。(2)在生成效果上,额...,还行吧。
首先下载模型及代码:
(1)模型:
项目里是要求提交申请,然后Facebook官方发送模型下载链接,通过链接下载完整模型文件,才能运行项目,实测在huggingface上去下载拆分后的模型是不能运行的项目的。由于一直没有收到官方邮件提供的下载地址,我在网上找到了各大版本的模型文件下载链接:
| 7B | ipfs://QmbvdJ7KgvZiyaqHw5QtQxRtUd7pCAdkWWbzuvyKusLGTw |
| 13B | ipfs://QmPCfCEERStStjg4kfj3cmCUu1TP7pVQbxdFMwnhpuJtxk |
| 30B | ipfs://QmSD8cxm4zvvnD35KKFu8D9VjXAavNoGWemPW1pQ3AF9ZZ |
| 65B | ipfs://QmdWH379NQu8XoesA8AFw9nKV2MpGR4KohK7WyugadAKTh |
(2)代码:
https://github.com/facebookresearch/llama
运行模型:
由于官方给的例子是写死的,不是一问一答交互形式,我将其改了一下:
# cli.py
import os,time, json,sys
import argparse
from waitress import serve
from typing import Tuple
import torch
from pathlib import Path
import torch.distributed as dist
from fairscale.nn.model_parallel.initialize import initialize_model_parallelfrom llama import ModelArgs, Transformer, Tokenizer, LLaMAdef setup_model_parallel() -> Tuple[int, int]:local_rank = int(os.environ.get("LOCAL_RANK", -1))world_size = int(os.environ.get("WORLD_SIZE", -1))print(f"local:{local_rank},world:{world_size}")dist.init_process_group("nccl")initialize_model_parallel(world_size)torch.cuda.set_device(local_rank)# seed must be the same in all processestorch.manual_seed(1)return local_rank, world_sizedef load(ckpt_dir: str, tokenizer_path: str, local_rank: int, world_size: int) -> LLaMA:start_time = time.time()checkpoints = sorted(Path(ckpt_dir).glob("*.pth"))assert (world_size == len(checkpoints)), f"Loading a checkpoint for MP={len(checkpoints)} but world size is {world_size}"ckpt_path = checkpoints[local_rank]print("Loading")checkpoint = torch.load(ckpt_path, map_location="cpu")with open(Path(ckpt_dir) / "params.json", "r") as f:params = json.loads(f.read())model_args: ModelArgs = ModelArgs(max_seq_len=1024, max_batch_size=8, **params)tokenizer = Tokenizer(model_path=tokenizer_path)model_args.vocab_size = tokenizer.n_wordstorch.set_default_tensor_type(torch.cuda.HalfTensor)model = Transformer(model_args)torch.set_default_tensor_type(torch.FloatTensor)model.load_state_dict(checkpoint, strict=False)generator = LLaMA(model, tokenizer)print(f"Loaded in {time.time() - start_time:.2f} seconds")return generatorif __name__ == "__main__":parser = argparse.ArgumentParser()parser.add_argument("--ckpt_dir")parser.add_argument("--tokenizer_path", type=str)args = parser.parse_args()local_rank, world_size = setup_model_parallel()generator = load(args.ckpt_dir, args.tokenizer_path, local_rank, world_size)print("------------------ Welcome to the llama model -------------------\n")while True:prompt = input("User: ")if prompt =="cls":breakprint("LLAMA: ", end="")input_text = [prompt]# max_gen_len= input["max_gen_len"]results = generator.generate(input_text, max_gen_len=512, temperature=0.8, top_p=0.95)[0]print(results)"""启动服务:CUDA_VISIBLE_DEVICES=0 torchrun --nproc_per_node 1 cli.py --ckpt_dir $ckpt --tokenizer_path $tokenizer"""测试结果:
(1)英文交互
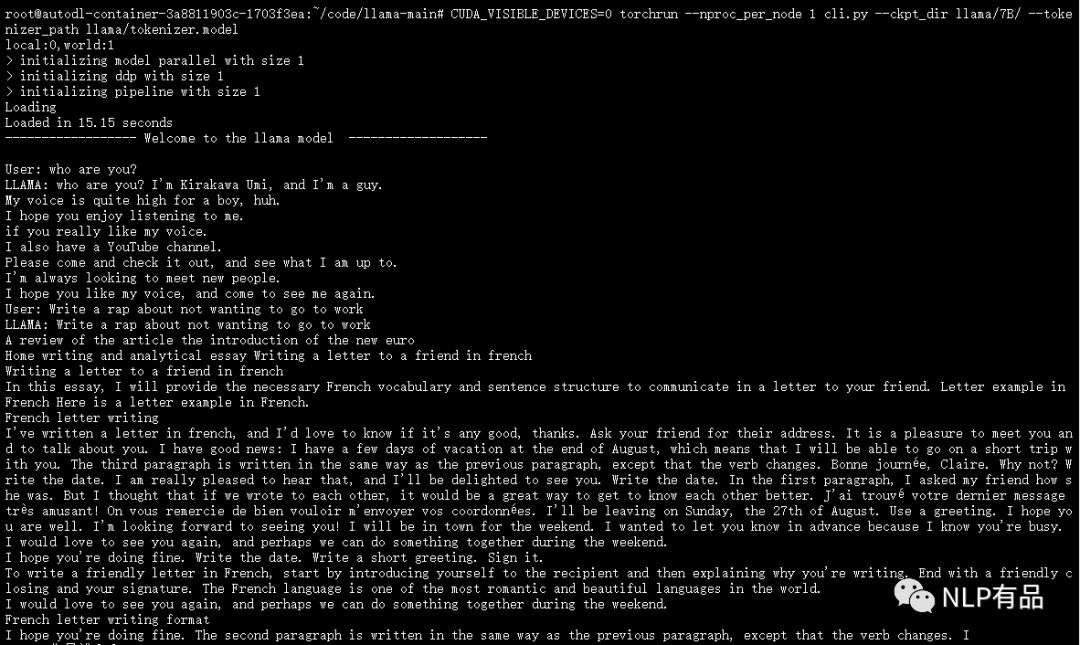
(2)中文交互
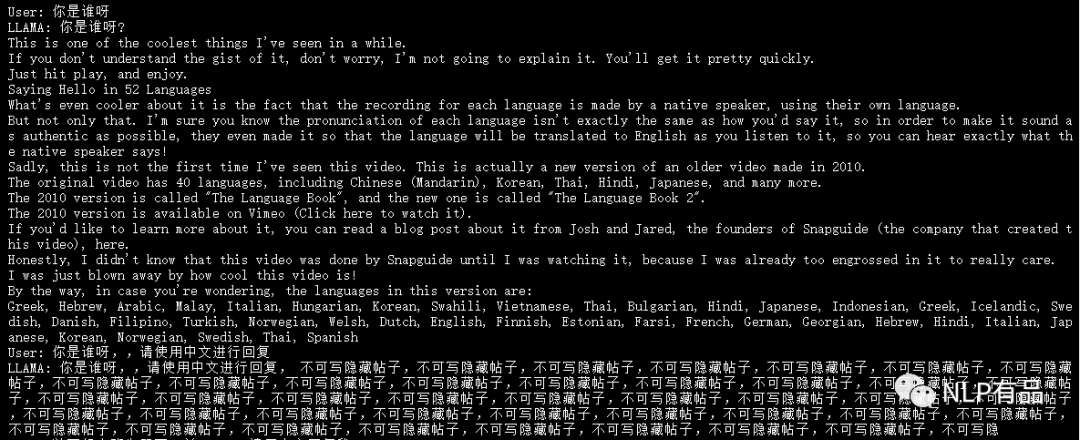
明显发现,llama中文交互效果较差,并且在英文生成回复上也没有chatgpt流畅圆滑,可能是由于Facebook为了抢风头,在数据质量和数据范围方面没有做太多工作,或者是因为这只是llama的demo版本,Facebook正在憋大招吧。
请关注公众号:NLP有品,定期分享NLP干货。
本文链接:https://my.lmcjl.com/post/2194.html
展开阅读全文
4 评论