Spring Boot中大文件分片上传—支持本地文件和AWS S3
前言
本篇主要整理了大文件分片上传客户端和服务端的实现,其中客户端是通过Java代码来模拟的文件分片上传的逻辑(我不太会写前端,核心逻辑都是一样的,这边前端可以参考开源组件:vue-uploader),服务端实现包含本地文件系统和AWS S3对象存储两种文件存储类型。
分片上传实现原理
实现原理其实很简单,网上也有很多资料,核心就是客户端把大文件按照一定规则进行拆分,比如20MB为一个小块,分解成一个一个的文件块,然后把这些文件块单独上传到服务端,等到所有的文件块都上传完毕之后,客户端再通知服务端进行文件合并的操作,合并完成之后整个任务结束。
主要能力
提供下面几个能力:
| 方法 | URL | 功能 |
|---|---|---|
| POST | /chunk | 分片上传 |
| GET | /merge?filename={filename} | 文件合并 |
| GET | /files/{filename} | 下载文件 |
| GET | /files | 获取文件列表 |
具体实现
代码结构
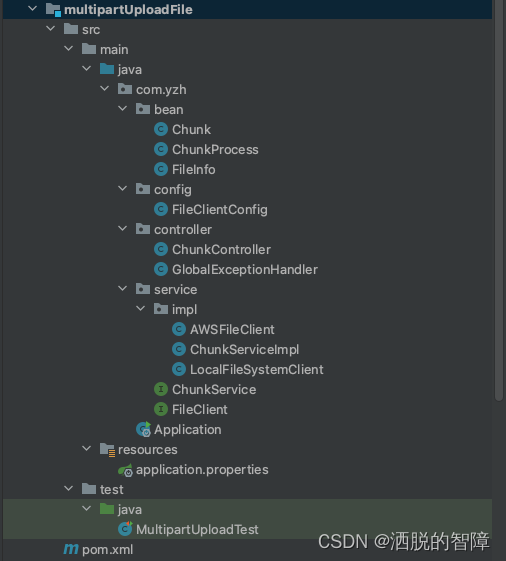
主要功能实现
服务端
这边直接贴一下代码
首先是Chunk类,这个类主要包含了分块的信息:
/*** 文件块** @author yuanzhihao* @since 2023/4/10*/
@Data
public class Chunk {/*** 当前文件块,从1开始*/private Integer chunkNumber;/*** 分块大小*/private Long chunkSize;/*** 当前分块大小*/private Long currentChunkSize;/*** 总大小*/private Long totalSize;/*** 文件名*/private String filename;/*** 总块数*/private Integer totalChunks;/*** 分块文件内容*/private MultipartFile file;
}
controller,提供四个接口:
/*** 分片上传** @author yuanzhihao* @since 2023/4/10*/
@RestController
@RequestMapping
public class ChunkController {@Autowiredprivate ChunkService chunkService;/*** 分块上传文件** @param chunk 文件块信息* @return 响应*/@PostMapping(value = "chunk")public ResponseEntity<String> chunk(Chunk chunk) {chunkService.chunk(chunk);return ResponseEntity.ok("File Chunk Upload Success");}/*** 文件合并** @param filename 文件名* @return 响应*/@GetMapping(value = "merge")public ResponseEntity<Void> merge(@RequestParam("filename") String filename) {chunkService.merge(filename);return ResponseEntity.ok().build();}/*** 获取文件列表** @return 文件列表*/@GetMapping("/files")public ResponseEntity<List<FileInfo>> list() {return ResponseEntity.ok(chunkService.list());}/*** 获取指定文件** @param filename 文件名称* @return 文件*/@GetMapping("/files/{filename:.+}")public ResponseEntity<Resource> getFile(@PathVariable("filename") String filename) {return ResponseEntity.ok().header(HttpHeaders.CONTENT_DISPOSITION,"attachment; filename=\"" + filename + "\"").body(chunkService.getFile(filename));}
}
service中,是分块的一些业务逻辑,这边存储的信息我都是写在内存中的,比如文件信息,分片信息等等:
/*** 文件分块上传** @author yuanzhihao* @since 2023/4/10*/
public interface ChunkService {/*** 分块上传文件** @param chunk 文件块信息*/void chunk(Chunk chunk);/*** 文件合并** @param filename 文件名*/void merge(String filename);/*** 获取文件列表** @return 文件列表*/List<FileInfo> list();/*** 获取指定文件** @param filename 文件名称* @return 文件*/Resource getFile(String filename);
}
/*** 分片上传** @author yuanzhihao* @since 2023/4/10*/
@Service
@Slf4j
public class ChunkServiceImpl implements ChunkService {// 分片进度private static final Map<String, ChunkProcess> CHUNK_PROCESS_STORAGE = new ConcurrentHashMap<>();// 文件列表private static final List<FileInfo> FILE_STORAGE = new CopyOnWriteArrayList<>();@Autowiredprivate FileClient fileClient;@Overridepublic void chunk(Chunk chunk) {String filename = chunk.getFilename();boolean match = FILE_STORAGE.stream().anyMatch(fileInfo -> fileInfo.getFilename().equals(filename));if (match) {throw new RuntimeException("File [ " + filename + " ] already exist");}ChunkProcess chunkProcess;String uploadId;if (CHUNK_PROCESS_STORAGE.containsKey(filename)) {chunkProcess = CHUNK_PROCESS_STORAGE.get(filename);uploadId = chunkProcess.getUploadId();AtomicBoolean isUploaded = new AtomicBoolean(false);Optional.ofNullable(chunkProcess.getChunkList()).ifPresent(chunkPartList ->isUploaded.set(chunkPartList.stream().anyMatch(chunkPart -> chunkPart.getChunkNumber() == chunk.getChunkNumber())));if (isUploaded.get()) {log.info("文件【{}】分块【{}】已经上传,跳过", chunk.getFilename(), chunk.getChunkNumber());return;}} else {uploadId = fileClient.initTask(filename);chunkProcess = new ChunkProcess().setFilename(filename).setUploadId(uploadId);CHUNK_PROCESS_STORAGE.put(filename, chunkProcess);}List<ChunkProcess.ChunkPart> chunkList = chunkProcess.getChunkList();String chunkId = fileClient.chunk(chunk, uploadId);chunkList.add(new ChunkProcess.ChunkPart(chunkId, chunk.getChunkNumber()));CHUNK_PROCESS_STORAGE.put(filename, chunkProcess.setChunkList(chunkList));}@Overridepublic void merge(String filename) {ChunkProcess chunkProcess = CHUNK_PROCESS_STORAGE.get(filename);fileClient.merge(chunkProcess);SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");String currentTime = simpleDateFormat.format(new Date());FILE_STORAGE.add(new FileInfo().setUploadTime(currentTime).setFilename(filename));CHUNK_PROCESS_STORAGE.remove(filename);}@Overridepublic List<FileInfo> list() {return FILE_STORAGE;}@Overridepublic Resource getFile(String filename) {return fileClient.getFile(filename);}
}
具体文件上传的实现是在FileClient中,我抽象了一个具体的接口:
/*** 文件客户端** @author yuanzhihao* @since 2023/4/10*/
public interface FileClient {/*** 初始化文件客户端*/void initFileClient();/*** 初始化任务** @param filename 文件名称* @return 任务id*/String initTask(String filename);/*** 上传文件块** @param chunk 文件块* @param uploadId 任务ID* @return 对于S3返回eTag地址 对于本地文件返回文件块地址*/String chunk(Chunk chunk, String uploadId);/*** 文件合并** @param chunkProcess 分片详情*/void merge(ChunkProcess chunkProcess);/*** 根据文件名称获取文件** @param filename 文件名称* @return 文件资源*/Resource getFile(String filename);
}
这个接口有两个实现类,一个是LocalFileSystemClient本地文件系统,还有一个是AWSFileClient对象存储,这块我是通过配置文件来指定加载哪一个文件客户端,类似懒加载的方式,具体加载类FileClientConfig:
/*** 文件上传客户端 通过配置文件指定加载哪个客户端* 目前支持本地文件和AWS S3对象存储** @author yuanzhihao* @since 2023/4/10*/
@Configuration
public class FileClientConfig {@Value("${file.client.type:local-file}")private String fileClientType;private static final Map<String, Supplier<FileClient>> FILE_CLIENT_SUPPLY = new HashMap<String, Supplier<FileClient>>() {{put("local-file", LocalFileSystemClient::new);put("aws-s3", AWSFileClient::new);}};/*** 注入文件客户端对象** @return 文件客户端*/@Beanpublic FileClient fileClient() {return FILE_CLIENT_SUPPLY.get(fileClientType).get();}
}
下面讲一下两种文件服务器的实现
本地文件存储
本地文件是把所有的分块上传到一个指定的目录,等上传完成之后,将所有的文件块排序,按照分片顺序一块一块的写到指定的合并文件中,之后清理所有的文件块,完成上传。
具体实现LocalFileSystemClient:
/*** 本地文件系统** @author yuanzhihao* @since 2023/4/10*/
@Slf4j
public class LocalFileSystemClient implements FileClient {private static final String DEFAULT_UPLOAD_PATH = "/data/upload/";public LocalFileSystemClient() {// 初始化this.initFileClient();}@Overridepublic void initFileClient() {FileUtil.mkdir(DEFAULT_UPLOAD_PATH);}@Overridepublic String initTask(String filename) {// 分块文件存储路径String tempFilePath = DEFAULT_UPLOAD_PATH + filename + UUID.randomUUID();FileUtil.mkdir(tempFilePath);return tempFilePath;}@Overridepublic String chunk(Chunk chunk, String uploadId) {String filename = chunk.getFilename();String chunkFilePath = uploadId + "/" + chunk.getChunkNumber();try (InputStream in = chunk.getFile().getInputStream();OutputStream out = Files.newOutputStream(Paths.get(chunkFilePath))) {FileCopyUtils.copy(in, out);} catch (IOException e) {log.error("File [{}] upload failed", filename, e);throw new RuntimeException(e);}return chunkFilePath;}@Overridepublic void merge(ChunkProcess chunkProcess) {String filename = chunkProcess.getFilename();// 需要合并的文件所在的文件夹File chunkFolder = new File(chunkProcess.getUploadId());// 合并后的文件File mergeFile = new File(DEFAULT_UPLOAD_PATH + filename);try (BufferedOutputStream outputStream = new BufferedOutputStream(Files.newOutputStream(mergeFile.toPath()))) {byte[] bytes = new byte[1024];File[] fileArray = Optional.ofNullable(chunkFolder.listFiles()).orElseThrow(() -> new IllegalArgumentException("Folder is empty"));List<File> fileList = Arrays.stream(fileArray).sorted(Comparator.comparing(File::getName)).collect(Collectors.toList());fileList.forEach(file -> {try (BufferedInputStream inputStream = new BufferedInputStream(Files.newInputStream(file.toPath()))) {int len;while ((len = inputStream.read(bytes)) != -1) {outputStream.write(bytes, 0, len);}} catch (IOException e) {log.info("File [{}] chunk [{}] write failed", filename, file.getName(), e);throw new RuntimeException(e);}});} catch (IOException e) {log.info("File [{}] merge failed", filename, e);throw new RuntimeException(e);} finally {FileUtil.del(chunkProcess.getUploadId());}}@Overridepublic Resource getFile(String filename) {File file = new File(DEFAULT_UPLOAD_PATH + filename);return new FileSystemResource(file);}
}
AWS S3对象存储
对象存储中,首先是需要调用initiateMultipartUpload方法,初始化生成一个任务标识uploadId,然后每个分块任务上传都需要携带这个uploadId,分块任务上传是调用uploadPart方法,这个方法会返回一个eTag标识,最后等所有文件块上传完成之后,需要使用这个eTag标识和uploadId去调用completeMultipartUpload方法完成文件合并。
具体实现:
/*** AWS S3对象存储** @author yuanzhihao* @since 2023/4/10*/
@Slf4j
public class AWSFileClient implements FileClient {// 默认桶private static final String DEFAULT_BUCKET = "";private static final String AK = "";private static final String SK = "";private static final String ENDPOINT = "";private AmazonS3 s3Client;public AWSFileClient() {// 初始化文件客户端this.initFileClient();}@Overridepublic void initFileClient() {this.s3Client = AmazonS3ClientBuilder.standard().withCredentials(new AWSStaticCredentialsProvider(new BasicAWSCredentials(AK, SK))).withEndpointConfiguration(new AwsClientBuilder.EndpointConfiguration(ENDPOINT, "cn-north-1")).build();}@Overridepublic String initTask(String filename) {// 初始化分片上传任务InitiateMultipartUploadRequest initRequest = new InitiateMultipartUploadRequest(DEFAULT_BUCKET, filename);InitiateMultipartUploadResult initResponse = s3Client.initiateMultipartUpload(initRequest);return initResponse.getUploadId();}@Overridepublic String chunk(Chunk chunk, String uploadId) {try (InputStream in = chunk.getFile().getInputStream()) {// 上传UploadPartRequest uploadRequest = new UploadPartRequest().withBucketName(DEFAULT_BUCKET).withKey(chunk.getFilename()).withUploadId(uploadId).withInputStream(in).withPartNumber(chunk.getChunkNumber()).withPartSize(chunk.getCurrentChunkSize());UploadPartResult uploadResult = s3Client.uploadPart(uploadRequest);return uploadResult.getETag();} catch (IOException e) {log.error("文件【{}】上传分片【{}】失败", chunk.getFilename(), chunk.getChunkNumber(), e);throw new RuntimeException(e);}}@Overridepublic void merge(ChunkProcess chunkProcess) {List<PartETag> partETagList = chunkProcess.getChunkList().stream().map(chunkPart -> new PartETag(chunkPart.getChunkNumber(), chunkPart.getLocation())).collect(Collectors.toList());CompleteMultipartUploadRequest compRequest = new CompleteMultipartUploadRequest(DEFAULT_BUCKET, chunkProcess.getFilename(),chunkProcess.getUploadId(), partETagList);s3Client.completeMultipartUpload(compRequest);}@Overridepublic Resource getFile(String filename) {GetObjectRequest request = new GetObjectRequest(DEFAULT_BUCKET, filename);S3Object s3Object = s3Client.getObject(request);return new InputStreamResource(s3Object.getObjectContent());}
}
客户端
客户端是通过Java代码模拟的前端逻辑,具体代码:
/*** 模拟前端逻辑 在代码中实现大文件分片上传 使用restTemplate客户端** @author yuanzhihao* @since 2023/4/10*/
public class MultipartUploadTest {@Testpublic void testUpload() throws Exception {String chunkFileFolder = "/data/bucket/";java.io.File file = new java.io.File("/Users/yuanzhihao/Downloads/ideaIU-2022.2.2.exe");long contentLength = file.length();// 每块大小设置为20MBlong partSize = 20 * 1024 * 1024;// 文件分片块数 最后一块大小可能小于 20MBlong chunkFileNum = (long) Math.ceil(contentLength * 1.0 / partSize);RestTemplate restTemplate = new RestTemplate();try (RandomAccessFile raf_read = new RandomAccessFile(file, "r")) {// 缓冲区byte[] b = new byte[1024];for (int i = 1; i <= chunkFileNum; i++) {// 块文件java.io.File chunkFile = new java.io.File(chunkFileFolder + i);// 创建向块文件的写对象try (RandomAccessFile raf_write = new RandomAccessFile(chunkFile, "rw")) {int len;while ((len = raf_read.read(b)) != -1) {raf_write.write(b, 0, len);// 如果块文件的大小达到20M 开始写下一块儿 或者已经到了最后一块if (chunkFile.length() >= partSize) {break;}}// 上传MultiValueMap<String, Object> body = new LinkedMultiValueMap<>();body.add("file", new FileSystemResource(chunkFile));body.add("chunkNumber", i);body.add("chunkSize", partSize);body.add("currentChunkSize", chunkFile.length());body.add("totalSize", contentLength);body.add("filename", file.getName());body.add("totalChunks", chunkFileNum);HttpHeaders headers = new HttpHeaders();headers.setContentType(MediaType.MULTIPART_FORM_DATA);HttpEntity<MultiValueMap<String, Object>> requestEntity = new HttpEntity<>(body, headers);String serverUrl = "http://localhost:8080/chunk";ResponseEntity<String> response = restTemplate.postForEntity(serverUrl, requestEntity, String.class);System.out.println("Response code: " + response.getStatusCode() + " Response body: " + response.getBody());} finally {FileUtil.del(chunkFile);}}}// 合并文件String mergeUrl = "http://localhost:8080/merge?filename=" + file.getName();ResponseEntity<String> response = restTemplate.getForEntity(mergeUrl, String.class);System.out.println("Response code: " + response.getStatusCode() + " Response body: " + response.getBody());}
}
测试验证
启动服务,调用客户端上传文件:
上传成功

获取文件列表:

下载文件:

结语
代码地址:https://github.com/yzh19961031/blogDemo/tree/master/multipartUploadFile
参考:
https://docs.aws.amazon.com/AmazonS3/latest/userguide/mpu-upload-object.html
https://lliujg.blog.csdn.net/article/details/125136122
https://blog.csdn.net/oppo5630/article/details/80880224
本文链接:https://my.lmcjl.com/post/3977.html
4 评论