声明:平时看些文章做些笔记分享出来,文章中难免存在错误的地方,还望大家海涵。搜集一些资料,方便查阅学习:http://yqli.tech/page/speech.html。语音合成领域论文列表请访问http://yqli.tech/page/tts_paper.html,语音识别领域论文统计请访问http://yqli.tech/page/asr_paper.html。如何查找语音资料请参考文章https://mp.weixin.qq.com/s/eJcpsfs3OuhrccJ7_BvKOg)。如有转载,请注明出处。
Is ChatGPT a general-purpose natural language processing task solver?
本文章是 Nanyang Technological University, Amazon Web Services,Shanghai Jiao Tong University, Georgia Institute of Technology, Stanford University在2023年2月8日发表的文章,内容主要为实验报告,其ChatGPT数据采集时间为2023.01.10~2023.01.31。该文章报告ChatGPT的优缺点,旨在这项研究能够启发未来的工作。具体文章参见https://arxiv.org/pdf/2302.06476.pdf
正文
由于该文章主要是实验报告,我们就直接看实验结果即可。
一 ChatGPT与GPT3.5对比
文章提到ChatGPT是在GPT3.5的基础上训练而来,所以在Arithmetic Reasoning、commonsense reasoning、 Symbolic reasoning、Logical reasoning 、Question Answering、Summarization和Sentiment Analysis任务进行对比。ChatGPT的效果在大多数任务优于GPT-3.5,也存在summary和Sentiment 任务表现较差,同时与具体任务微调的模型相比性能较差,与理想的通用模型还有一段距离。
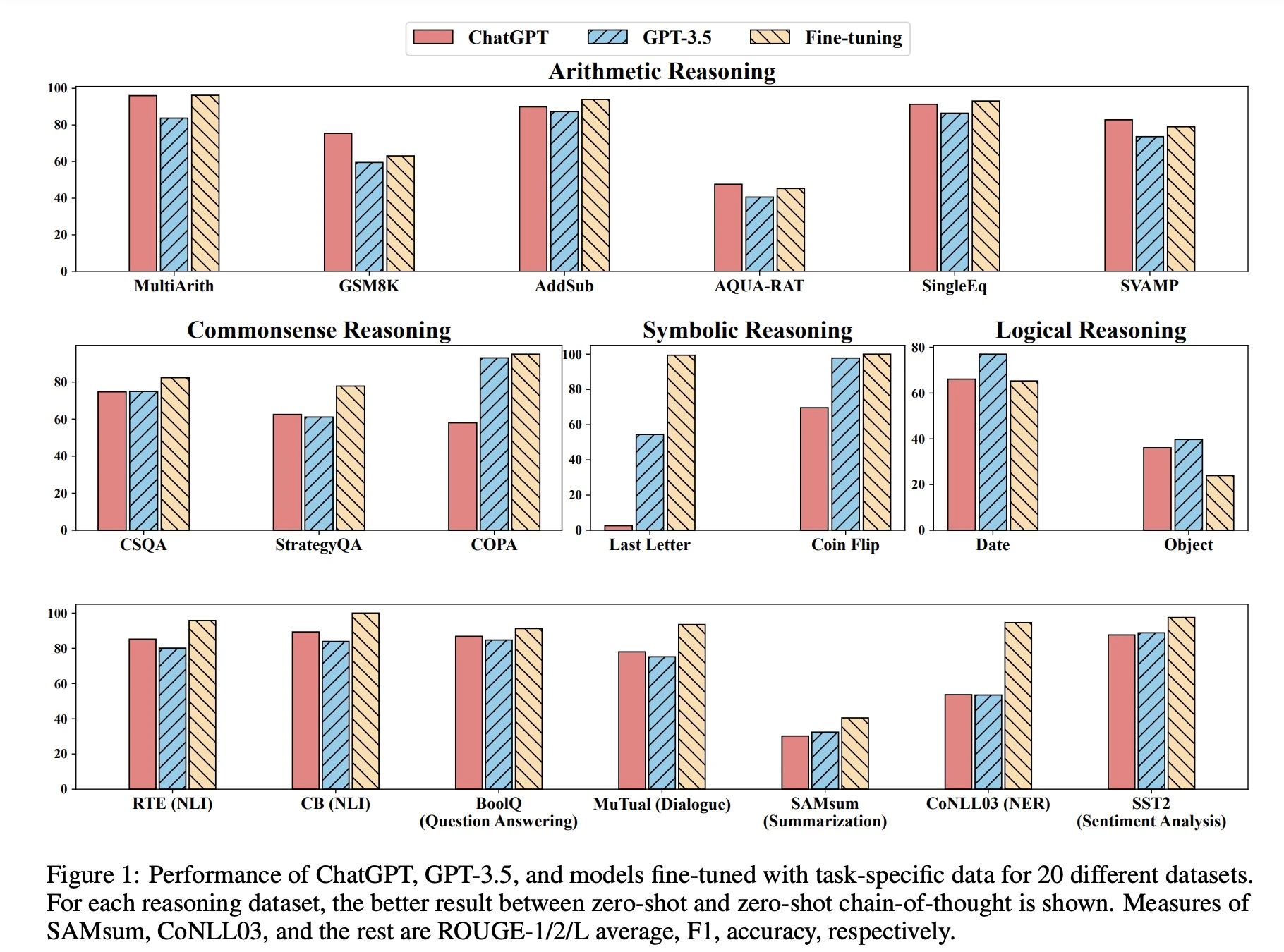
二 在不同任务上与GPT3.5变种(ext-davinci)和其它语言模型对比
任务:
Arithmetic Reasoning、Commonsense, Symbolic, and Logical Reasoning、Question Answering、Natural Language Inference、Dialogue、Named Entity Recognition、Summarization和Sentiment Analysis。
任务输入格式:
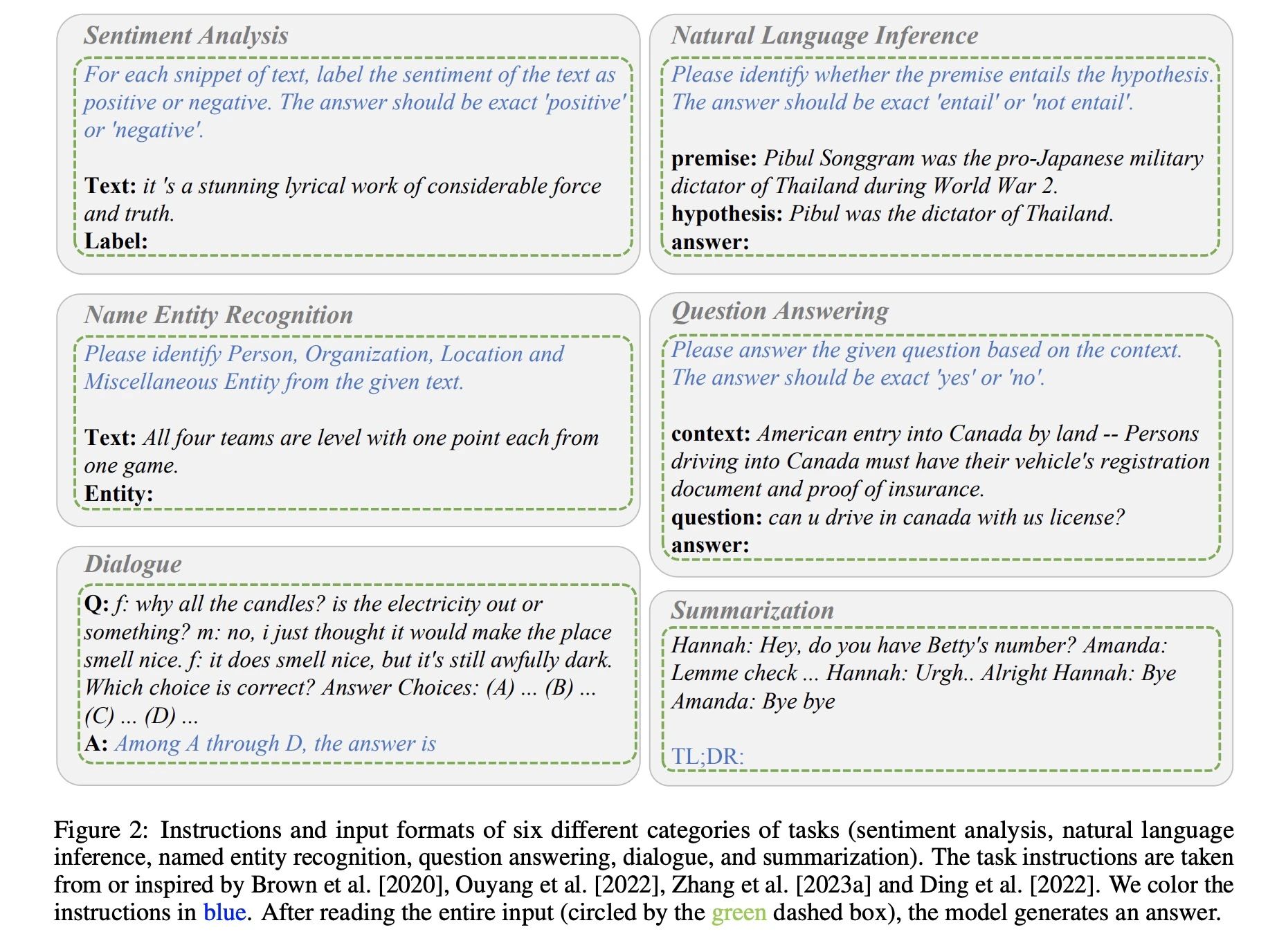
数据集
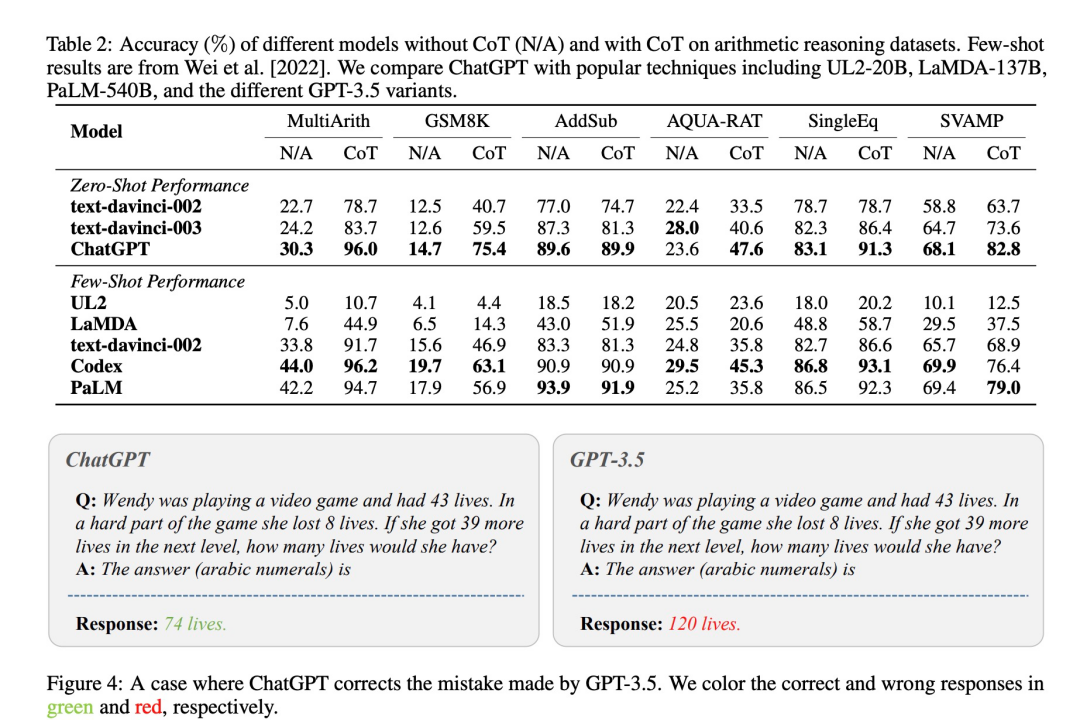
1)Arithmetic Reasoning
结果:ChatGPT优于GPT3.5,但比该任务的模型性能差
2)Commonsense, Symbolic, and Logical Reasoning
结果:ChatGPT优于GPT3.5,但比该任务的模型性能差


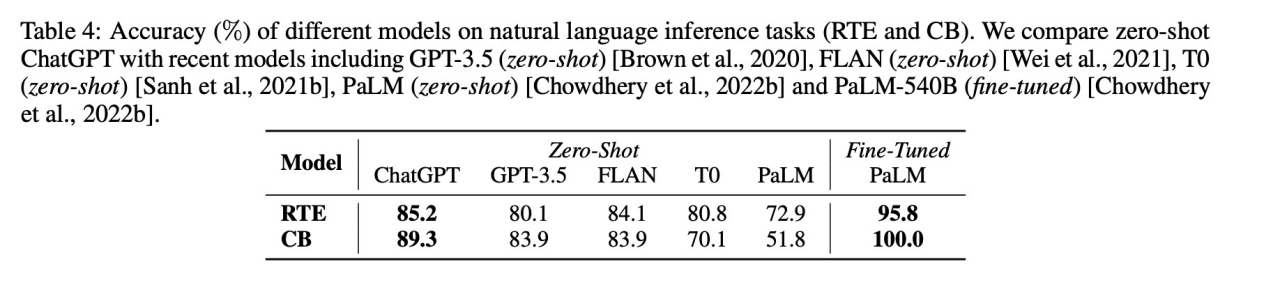
3)Natural Language Inference
结果:ChatGPT优于GPT3.5,但比该任务微调的模型性能差。另外Not Entailment性能比GPT3.5差

4)Question Answering
结果:ChatGPT优于GPT3.5,但比该任务的模型性能差


5)Dialogue
结果:ChatGPT优于GPT3.5,但比该任务的模型性能差

6)Summarization
结果:ChatGPT比GPT3.5,差但比该任务的模型性能差
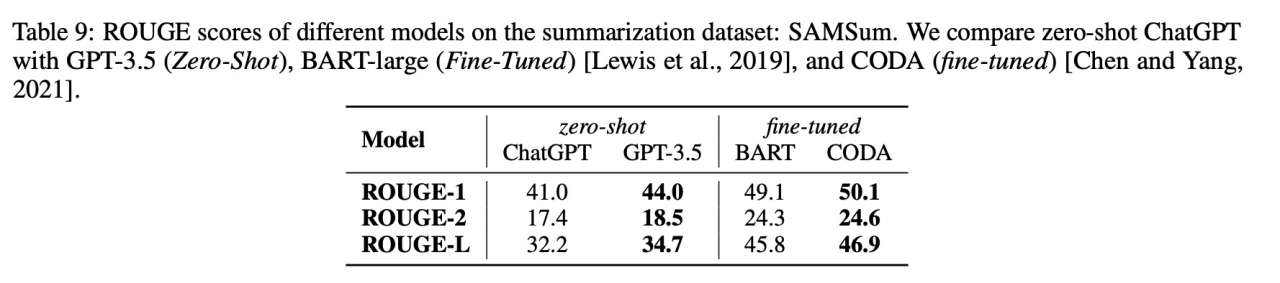

7)Named Entity Recognition
结果:ChatGPT与GPT3.5对不同实体词性能表现不一
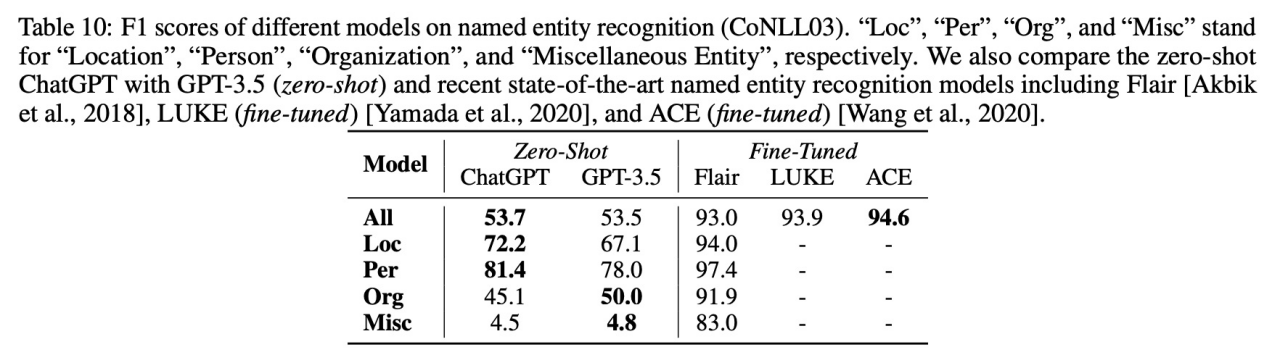

8)Sentiment Analysis
结果:ChatGPT差于GPT3.5
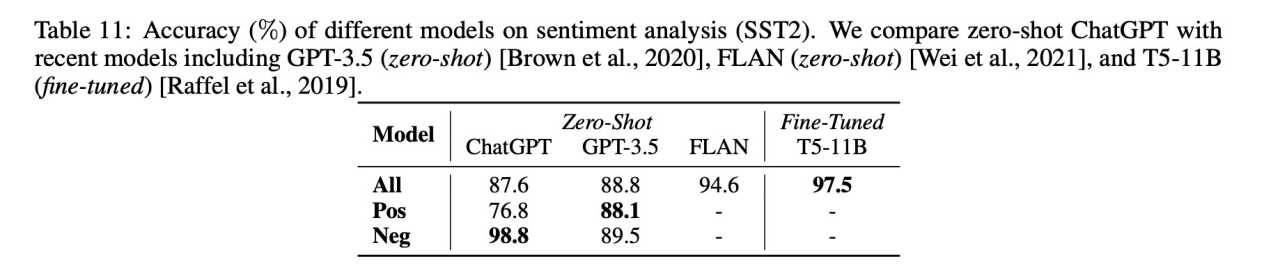
9)ChatGPT v.s. Full-Set or Few-Shot Fine-Tuning
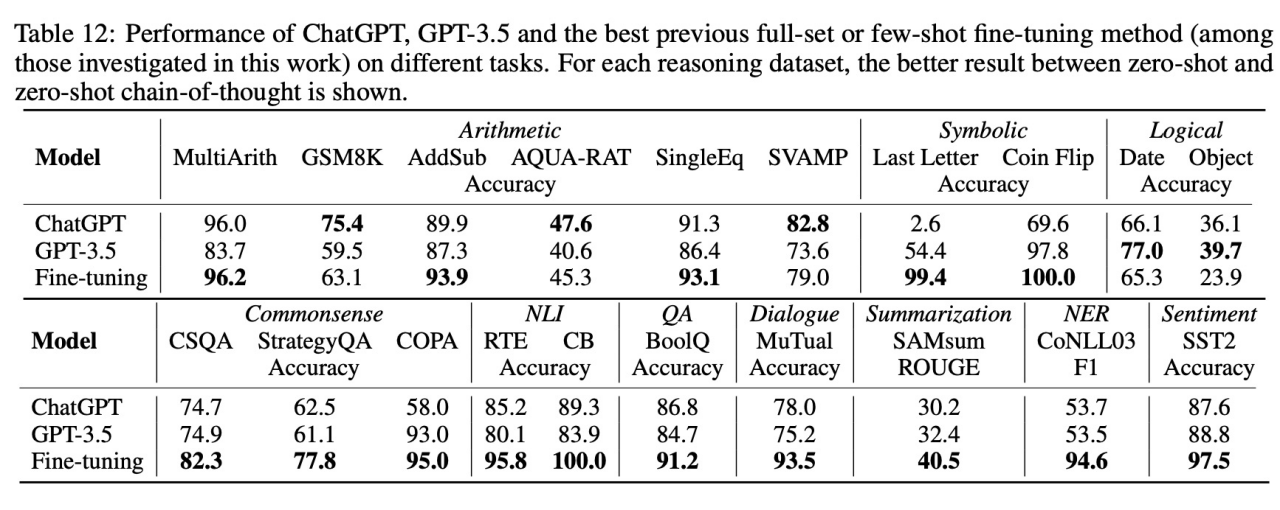
总结
作为一个强大的通用模型,ChatGPT 一方面擅长推理和对话任务;另一方面,ChatGPT 在总结和情感分析还不够强大。该研究希望能够启发未来的工作,产出强大的通用语言模型。
本文链接:https://my.lmcjl.com/post/9138.html
4 评论