从 ChatGPT Plus 发布第一天就开始重度使用,刚刚和新发布的 GPT-4 进行了 20 多轮对话,来简单介绍下这几个模型背后的技术,并且分享下感受。
GPT 在发展历程中,一共经历了 4 个阶段,分别是 1、2、3、4。这几个阶段分别进行了不同思考,就好像三体中提出的几个公理,都很有意思。
一切的起点
第一代模型 GPT-1,当时的论文叫做「通过生成式预训练模型,来提升对于语言本身的理解」Improving Language Understanding by Generative Pre-Training。其中的 Generative Pre-Training,便是现在 GPT 的来源。在传统机器学习中,学者们更喜欢用标注好的东西来进行机器学习。比如我心情真棒(正面情绪),括号中的就是一个标注。
在这篇论文中,OpenAI 在想,这个世界上有如此丰富的语料,但大部分都是没有被标注的数据。虽然不好用,但我们可以通过对其学习,只要学的足够多,我们就可以培养模型对于语言表达的理解能力。
多任务学习者
第二代模型 GPT-2, OpenAI 手头拿着学会了语言模型,但的确是没什么用。他们就在思考,现在是能理解文字了,但是这什么也不能干呀,这个模型到底能做什么呢?在大量试验后,他们发现,人们以往认为机器学习中的自然语言处理,也许不一定需要划分成很多很多的子任务。
如果语言本身包含了这些信息,那么各类任务,都应该可以被统一学习。比如,传统思路中,人们认为翻译,你必须要有中英文对应,来进行学习。但实际上,互联网上充斥着这样的提问,比如:有没有小伙伴知道香水有法语怎么表达最贴切,于是就有人回复 Parfum。
这段话既包含了中文原文,又包含了网友智慧所提出的法语翻译。既然我们学了这么多语料库,那么翻译,应该是自然而然就能学会的,不需要单独进行。同理,归类、找相似性、等等工作,都应该可以被大模型统一的表达。
因此提出了第二篇论文「大语言模型,是无需监督的多任务学习者」Language Models are Unsupervised Multitask Learners。即它可以自己学会做很多很多事,不用监督瞪大眼睛看它学对没,先学再说。学会的知识,应该是具备普适性的,能够处理很多任务。
举个例子就行
第三代模型 GPT-3,也就是大家熟悉的 ChatGPT 的前身。这个阶段,OpenAI 在冲着充分堆料,已经学会很多内容的模型陷入深深思考。既然它通过学习大量数据,掌握了人类语言,又理论上来说具备多任务的处理能力,怎么才能让它用出来呢?
传统思路中,机器学习模型需要进行针对性优化,来提升对于不同任务的表现。OpenAI 看了看已经被训练的巨大的模型,每次针对性优化,其实是不现实的,于是放弃了这条路。转而进行下一个重要思考。既然人类可以通过举例学习,语言模型应该也可以。
因此提出了第三篇论文「大语言模型,通过几个例子就能学会你要他做什么」Language Models are Few-Shot Learners。比如,如果你和一个智慧球举例,说从一数到一百,1,2,3... 它就应该能根据你的例子,去完成内容补全。甚至多学学,不用举例子也行。
这便是前三代模型的发展背景。截至目前为止,OpenAI 手头的这几个模型一个比一个大,但是最大的问题在于,它们擅长生成符合人类说话风格的胡言乱语,但是这不符合和人类和他们交流的习惯。
OpenAI 首先想到的就是服务程序员的代码,如果学会了世界上所有代码,应该能给人带来帮助。于是在此尝试下,推出了包含代码数据集的 OpenAI Codex,并且把这个包含了代码和新数据训练的模型叫做 GPT-3.5。这还是不好用,因为在人类世界中,我说上句你补充下句意义不大。
重点还是交流,交流涉及沟通,于是便训练了基于 GPT-3.5 的对话模型 InstructGPT。这个模型中用到了很多人工反馈,对问答方式和表述方式进行更符合人性的指导。而我们现在最熟悉,最出圈的 ChatGPT,就是 InstructGPT 的一个更适合大众的姊妹模型变种。
GPT 所开启的新时代
在我的工作中,ChatGPT 已经成为不可或缺的一部分,它带来的生产效率提升可以轻松达到 20 倍以上。从我个人角度出发,觉得这项技术,会深刻改变人类学习、教育、做事的方式。新的教育体系,若思维固步自封,同时学生不尽快地掌握 ChatGPT,那么从起点上就会落后非常多。
就像互联网时代前和后,新能源汽车时代前和后,时代已经被刻骨,全面,深刻的改变了。
它不会降低知识的门槛,也就是说,如果一个人并不熟悉某个领域,指望就靠 ChatGPT 用处不大。这就好像一个小朋友问围棋之神,我如何才能变成围棋大佬一样,帮助有限。但假如你已经是个业余棋手,有了 ChatGPT 会无限拉进你与世界上顶尖棋手的距离。
即便已经强如 ChatGPT,还是存在一些问题。比如,在复杂语句的推理能力,其实 ChatGPT 还有成长空间。比如倘若你的描述充满非常复杂的逻辑关系,那么 ChatGPT 有可能会遗漏其中的部分要求。这个问题,在我今晚测试的 GPT-4 中,就完全解决啦。

因为之前的 ChatGPT 已经过于强大,从我们的专业场景使用中,出现问它不知道的情况已经是极小概率事件,可靠性已经达到或高于大部分极优秀的人类。所以我不认为大家会发现 GPT 4 突然如何颠覆。主要还是因为 ChatGPT,几乎已经能做到很多专业场合中 99%+ 场景的高度可用性。
这次更新,除了如下图所示,让 GPT 通过无比困难的美国司法考试外。也几乎做到了一个知识球的本分,当称职的智慧本身。
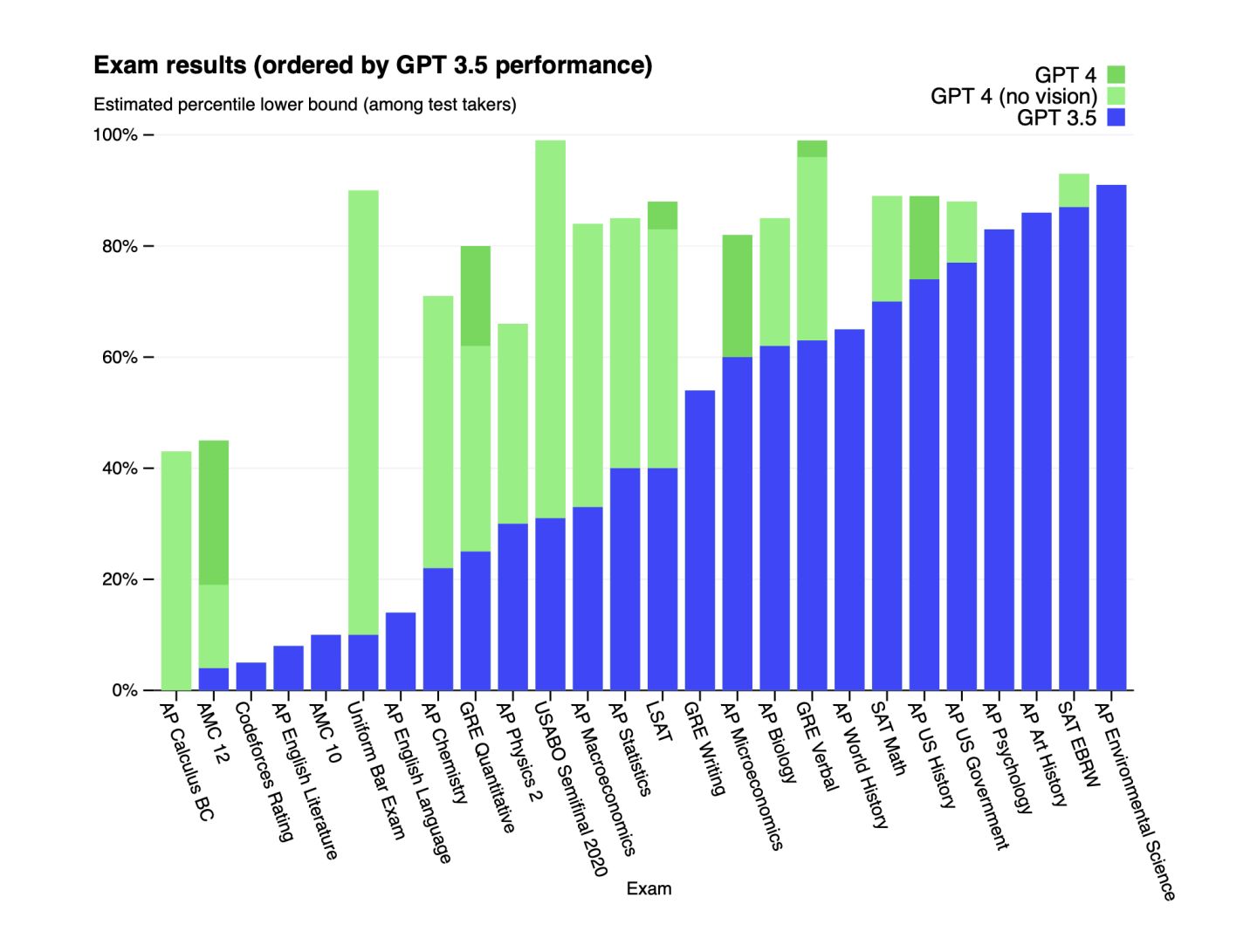
第 4 代 GPT 及使用建议
第四代模型 GPT-4,重点强化了创作能力,如作曲,写小说等;增加了对于长文本的处理能力。最重要的,还是多了一种新的交互方式,就是对于图片的理解。也就是本次新论文的标题「多模模型」 Large Multimodal Model。
在之前 ChatGPT 的使用中,因为没法插入图片,所以有些需要表述的内容,需要靠文字描述给它。现在不需要了,直接一丢就行,让它自己理解去。GPT-4 除本身带了对于图片 OCR 外,还有对位置和细节的理解能力,比如下图中 GPT-4 的回复,是对于一张截图的描述。

从目前体验来看,GPT-4 的答复效果和 ChatGPT-3.5 Turbo 相比稍微提升,对于语义逻辑性的把握比老版本显著较好。但有个很大的问题,就是新模型的答复非常慢。我个人猜测有两个可能:
1. GPT-4 类似于 1750 亿参数的 GPT-3,目前是个未经充分优化的版本,而不是百亿参数级别的 ChatGPT 3.5 Turbo。这个模型从 OpenAI 限制访问次数也可以看出,实际上做答复也非常消耗 OpenAI 那边跑模型的算力。
2. GPT-4 因为是个多模模型,所以流程要比纯文本的 ChatGPT-3.5 Turbo 显著复杂。大概率包含了图片向量理解的类似 CLIP 文本和图片向量对齐的中间模型等操作,整体运作也更为复杂。
目前我的建议:
如果你的工作中:ChatGPT-3.5 Turbo 能满足你,用那个就行,完全够用。免费版本的 ChatGPT 3.5 英文版本没问题,中文使用不建议,它的中文的语料库和 ChatGPT-3.5 Turbo 相比差距比较大。GPT-4 除非你的问题比较复杂,你需要比较发散思维有创造力的回答,或者需要图片插入,否则目前的响应速度,除非特别有耐心,大部分时候没必要着急用这个新模型。
总结
我还是非常喜欢这次的 GPT 更新,也很欣喜人类在被推着进步,已经开始期待能可能能够输出图片甚至视频 GPT-5 了。能活在这个时代,感觉很幸运。
本文链接:https://my.lmcjl.com/post/10973.html
4 评论