
来源:中国指挥与控制学会
(《指挥与控制学报》刊文精选)
引用格式 罗俊仁, 张万鹏, 苏炯铭, 等. 面向智能博弈的决策 Transformer 方法综述 [J]. 指挥与控制学报, 2023, 9 (1) : 9-22.
LUO J R, ZHANG W P, SU J M, et al. On decision-making transformer methods for intelligent gaming[J]. Journal of Command and
Control, 2023, 9 (1) : 9-22.
摘要
智能博弈是认知决策智能领域的挑战性问题,是辅助联合作战筹划与智能任务规划的关键支撑。从协作式团队博弈、竞争式零和博弈和混合式一般和博弈共3个角度梳理了智能博弈模型,从认知的角度出发定义了运筹型博弈(完全/有限理性)、不确定型博弈(经验/知识)、涌现探索型博弈(直觉+灵感)、群体交互型博弈(协同演化)共4类智能博弈认知模型,从问题可信任解、基准学习方法、策略训练平台共3个视角给出智能博弈求解方案。基于 Transformer 架构重点梳理了架构增强(表示学习、网络组合、模型扩展)与序列建模(离线预训练、在线适变、模型扩展) 共 2 大类 6 小类决策 Transformer 方法, 相关研究为开展。“离线预训练 + 在线适变”范式下满足多主体、多任务、多模态及虚实迁移等应用场景的决策预训练模型构建提供了初始参考. 为智能博弈领域的决策基石模型相关研究提供可行借鉴。
博弈一词的英文单词为Game,英文直译为游戏,早年国内译为对策、赛局。博弈问题的研究本质是通过将除己方外其他参与方的行为策略考虑在内制定己方对策过程。协作与竞争是双生体,广泛存在于认知决策博弈领域。未来军事对抗具有环境高复杂、信息不完整、博弈强对抗、响应高实时、自主无人化等突出特征,无人集群自主协同、作战仿真推演和智能任务规划等挑战课题都亟需智能博弈相关技术的支撑。博弈智能是认知智能的高阶表现形式。近年来,借助各类计算机博弈平台,面向智能博弈(intelligent gaming)的相关人工智能技术得到迅猛发展。智能博弈本质是指协作、竞争或对抗场景下,利用博弈理论分析问题、智能方法求解应对策略的过程。人机对抗(human computer gaming)作为图灵测试的典型范式,是测试人工智能(artificial intelligence, AI)技术程序的主要手段和基准[1],是智能博弈的重要表现形式。智能博弈作为智能指挥与控制领域研究决策智能的基准挑战,是当前研究决策大模型的试验场和果蝇。当前围绕智能博弈问题的求解,已然传统的“知识与搜索”、“博弈学习”范式过渡到“模型与适应”范式[2],其中,包括面向小模型的“预训练+微调”和面向大模型的“基石模型+情境学习”。
围绕人类认知能力的认知建模技术已然成为AI领域的前沿课题。近年来,随着AI技术的发展和GPU性能的逐年翻倍,AI大模型/基石模型[3]在视觉与语言智能计算、智能博弈领域取得了快速发展。基于大模型的AI生成内容(AI-generated context, AIGC)技术未来将成为一种基础设施,AI生成行动 (AIgenerated action, AIGA)相关技术(行为生成、模型生成)为决策问题求解提供了可行方案。伴随着2022年年末 ChatGPT的出现,各类基石的出现已然引发了AI各赛道里的“军备竞赛 , 但一般的语言能力无法完全匹配决策需要的推理能力, 如何构建“决策基石模型”已然成为当前 AI 与智能决策领域的前沿问题。
Transformer 作为一种利用注意力机制来完成序列到序列变换的表示学习模型, 利用此类模型构建智能博弈问题的决策策略求解方法是热门研究方向。基于Transformer 的表示学习方法[3]和序列建模方法[4]及多模态融合学习方法[5]引发了各大领域(自然语言处理、计算机视觉、语音与视频、智能博弈决策)的持续关注. LI 等[6]从表示学习、模型学习、序贯决策和通才智能体4个角度对基于Transformer 的强化学习方法进行了综述分析。HU等[7]从架构增强 (特征表示、环境表示),轨迹优化(条件行为克隆、经典强化学习、预训练、泛化性)和典型应用(机器人操控、文字游戏、导航、自动驾驶)共3大类对基于Transformer 的强化学习方法进行了总结对比分析. 当前围绕决策 Transformer 的方法可分为3大类:直接利用大语言模型类(百科、视频、互联网知识)、基于框架变换的表示及模型学习类(表示学习、环境学习)、基于决策问题重构的条件生成类(序列建模、行为生成、世界模型生成)。
如何为规划与决策领域的智能博弈问题设计新型求解框架仍充满挑战。本文围绕智能博弈问题展开,梳理各类问题的博弈模型, 创新性构建智能博弈认知模型, 探索性给出智能博弈问题的求解范式;重点梳理面向智能博弈问题求解的决策 Transformer 方法。
1
智能博弈与规划决策
1.1 智能博弈简述
伴随着AI近70年的发展,计算机博弈(computer games)作为博弈论与人工智能的桥梁,逐渐在人机对抗比赛中被一大批高水平AI克服。近年来,伴随着人工智能的第三次浪潮,智能博弈技术取得了飞速发展,博弈对抗场景从棋类、牌类、视频类陆续过渡到仿真推演类,博弈对抗技术从单一学习方法、分布式学习方法向大规模、通用学习方法演进。从2016年至2022年,AlphaX系列智能体(AlphaGo[8]、AlphaZero[9]、AlphaHoldem[10]、Alphastar[11])的相关研究为各类型博弈问题的求解提供了新基准。智能博弈技术研究从游戏扩展至军事任务规划与决策领域。近年来,智能博弈领域的一些标志性突破如图1所示。
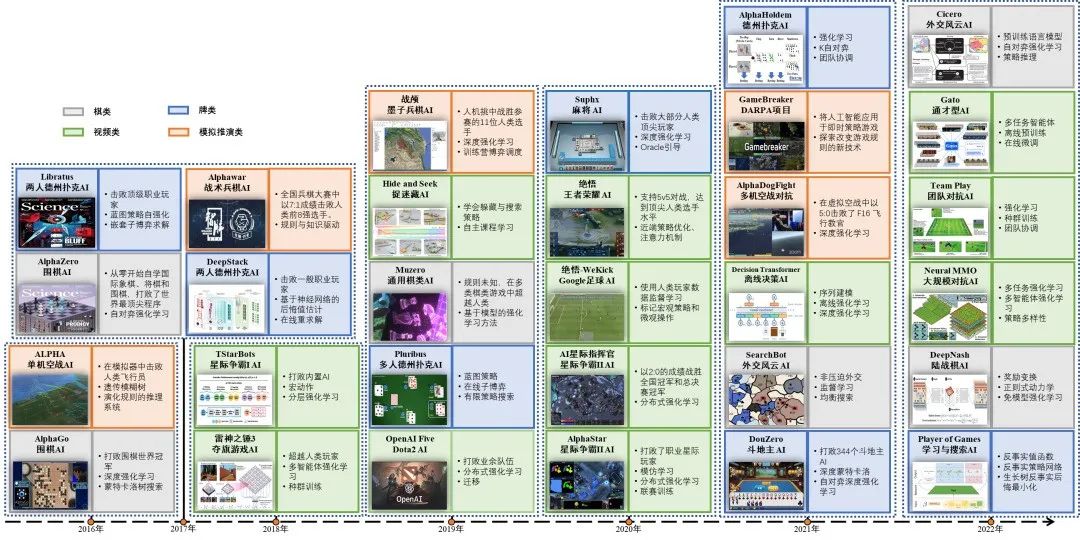
图1 智能博弈标志性突破
Fig.1 Remarkable breakthroughs of intelligent gaming
1.2 军事智能博弈
从早前的空战Alpha AI[12]至AlphaDogfight[13],美军在军事智能博弈领域展开了相当多的项目。2016年,美国辛辛那提大学与空军研究实验室合作开发了一个叫“Alpha AI”的机器飞行员,控制虚拟环境中的无人作战飞机完成飞行和打击等空战任务。2018年,美空军下一代自主无人战斗机智能平台 Skyborg,计划2023年末之前实现自主无人战斗机的早期自主决策和作战能力;2019年5月宣布启动“空战演进”(air combat evolution,ACE)项目,ACE项目旨在以人机协同“Dogfight”为挑战问题,进而开发可信、可扩展、人类水平、AI驱动的空战自主能力。
此外, 2018 年美国国防部高级研究计划局 (Defense Advanced Research Projects Agency, DARPA) 发
起“面向复杂军事决策的非完美信息博弈序贯交互”项目,旨在自动化地利用呈指数增长的数据信息,将复杂系统的建模与推理相结合,从而辅助国防部快速认识、理解甚至是预测复杂国际和军事环境中的重要事件;2020年,DARPA通过其官网宣布为“打破游戏规则的人工智能探索”(Gamebreaker)项目,开发人工智能并将其应用于现有的即时策略海空战兵棋《指挥:现代作战》之中,以打破复杂的模型所造成的不平衡,旨在推动人工智能嵌入兵棋系统融合。2021年9月,由美国家安全创新网络办公室(National Security Innovation Network,NSIN)和美空军研究实验室(Air Force Research Laboratory, AFRL)合作举办的人工智能指挥决策公开挑战赛落下帷幕,参赛选手们基于兵棋开发AI方法,实现各类指挥决策作战筹划快速生成。
1.3 智能规划与决策
近5年来,美军在智能指挥决策技术领域进行了深入探索,个别项目得到实际应用。如表1所示。2018年,美陆军指挥控制软件集成了行动方案(course of action, COA)分析决策支持工具,即聚焦作战的仿真(OpSim)[14];2019年,美空军为多源异构无人自主平台行动规划设计了“情景式”体系结构,自主系统会根据可用资产进行推理,生成可推荐的“情景”计划[15];自2020年起,美陆军在会聚工程(Convergence)演习中,利用智能辅助决策系统——火力风暴(FireStorm)推荐战术端的武器目标分配方案[16];2021年,兰德公司围绕空中自主攻击计划生成进行研究,美空军发布了“今夜就战”(fight tonight)项目[17],尝试利用仿真环境与人类指导生成大量备选行动计划,这是一项重大变革,旨在利用人工智能技术构建、演练和评估空中作战计划。2022年,美空军开展研发“面向计划、战术、实验和弹性的战略混合引擎”权杖项目[18],旨在依托计算机生成作战行动层面的作战行动方案,利用高保真可信模拟器对筛选出的最佳方案进行验证,并最终交由人工审查;第一阶段注重开发能够发现相关和可解释的行动方案的非脚本且具目标导向的智能体,实现大规模军事场景的快速探索。
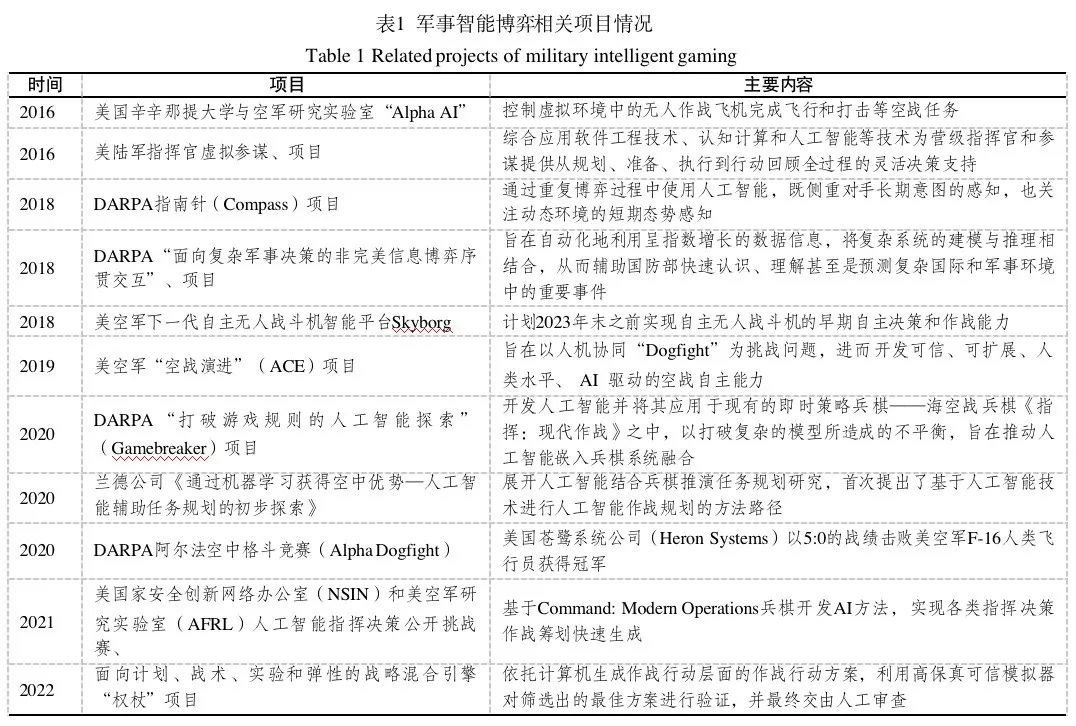
2
智能博弈问题求解
2.1 智能博弈问题模型
智能博弈问题通常可以采用多智能体问题模型来建模。根据智能体之间的关系,智能博弈问题可分为:协作式团队博弈、竞争式零和博弈和混合式一般和博弈,其中,协作式博弈追求最大化团队收益、通过协同合作来实现目标;竞争式零和博弈追求最大化自身收益、通常采用纳什均衡策略;混合式一般和博弈既有合作又有竞争,即组内协作、组间对抗。相关典型场景如图2所示。
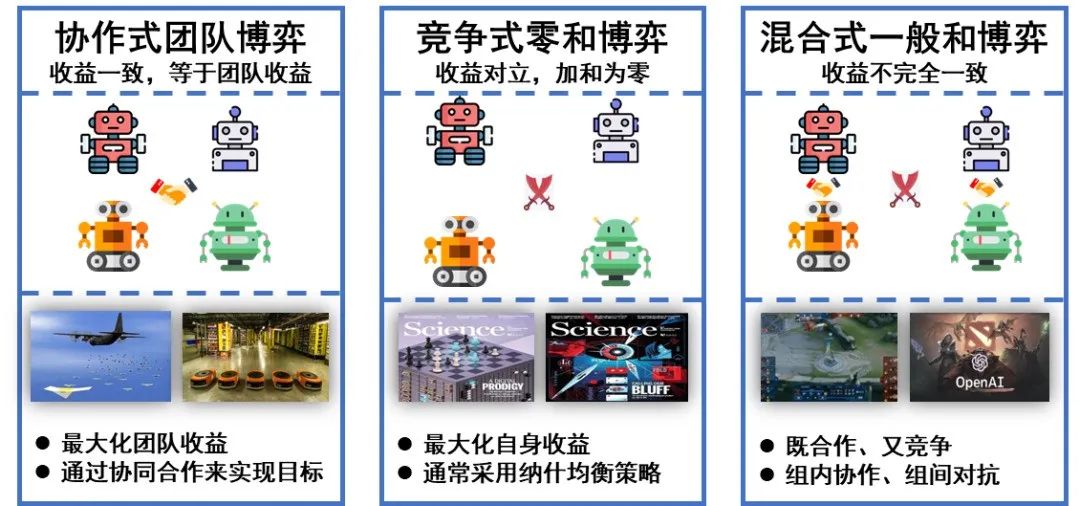
图2 智能博弈问题分类
Fig.2 Classification of intelligent gaming problems
2.1.1 协作式团队博弈

2.1.2 竞争式零和博弈

2.1.3 混合式一般和博弈
混合式一般和博弈是一类混合型场景,其中,既可能包含合作也可能包含竞争,每个智能体都是自利的,其收益可能与其他智能体有冲突,智能体之间在目标上没有约束关系,这类模型的求解通常比较困难,当前大多数多智能体学习方法无法提供收敛性保证[18]。当前围绕着这类博弈模型的研究主要聚焦于纳什均衡、相关均衡和斯坦伯格均衡的求解和基于元博弈的策略学习。
2.2 智能博弈认知建模
从认知的角度分析,当前围绕智能博弈问题可建模成4类,如图3所示。

图3 智能博弈认知建模模型
Fig.3 Cognitive modeling models for intelligence gaming
1)基于完全/有限理性考虑的运筹型博弈模型:主要采用基于确定性机理模型的博弈搜索与在线优化方式提供智能。
2)面向经验匮乏的不确定性博弈模型:主要采用基于海量多源数据的高效学习与未知经验/知识习得。
3)挑战直觉和灵感的探索型博弈模型:主要采用基于平行数字孪生环境或元宇宙的试错(反馈)及迁移获得智能。
4)考量种群协同演化的群体交互型博弈模型:主要采用基于开放性群体多样性交互的种群演化。
2.3 智能博弈求解方案
2.3.1 智能博弈问题可信任解
围绕博弈问题的求解方法主要区分为离线与在线(训练与测试)两个阶段。对于多方博弈问题,由于环境(对手)的非平稳性、多解选择等问题使得博弈问题求解表现出“离线耦合、在线解耦”的状态。离线训练主要采用仿真环境模拟与对手的交互,获得离线采样数据,利用大规模计算方式得到蓝图策略或利用分布式强化学习方法得到预训练模型;在线博弈过程中,由于仅能控制己方策略,应对策略的生成处于解耦合状态,需要采用适应对手的反制策略。
从解概念的角度看,博弈问题的求解本质是设计高效的样本利用方法对问题的解空间进行探索,获得问题的可信任解,其中包括应对约束的安全解、应对不确定性扰动的鲁棒解、应对分布漂移考量泛化性的多样解,应对突发及意外情景的适变解,以及可解释解、公平解等。
2.3.2 智能博弈策略训练平台
围绕如何将方法求解与分布式计算融合是学术界与工业界的共同聚焦点。受Alphastar启发,腾讯团队设计了基于启发式联赛训练的竞争式自对弈Tleague[24],上海交通大学团队设计了基于策略评估的MALib[25],这两类开源的分布式学习平台为求解大规模博弈问题提供了可参考的通用解决方案。随着智能体个数的增加,多样化的智能体种群表现出协同演化的性质。从种群视角看,分布式学习为种群的智能演进提供了超实时支持。
2.3.3 智能博弈问题求解范式
1) 基于知识与搜索
从绝对理性假设出发,充分利用专家知识、打分,设计启发式,外部知识等方式引导博弈树搜索,从早期的极小-极大搜索、蒙特卡洛树搜索(Monte carlo tree search, MCTS)、信息集MCTS、分层任务网络MCTS等。
2) 基于博弈理论学习
从交互的角度分析博弈多方策略之间的合作与竞争关系,通过构建考虑对手的策略迭代式学习、策略优化式学习等方法,利用模拟或在线交互场景样本数据优化策略。
围绕博弈问题的基准学习方法主要分为三大类:基于反事实后悔值最小化(counterfactual regret minimization, CFR)类方法[19],基于虚拟自对弈(fictitious self play, FSP)类方法[20],基于元博弈的策略空间响应预言机(policy space response oracle, PSRO)类方法[21]。作为一类利用仿真器模拟的博弈策略学习方法,PSRO类方法将经验博弈论分析(empirical game theoretic analysis, EGTA)方法[22]扩展成迭代式自动化方法,已然成为当前的研究基准方法范式,其本质上是一类基于种群的增量迭代式训练方法,其求解流程如图4所示[23]。此外,基于优先级的虚拟自对弈(PFSP)方法是当前工程实践过程中经常被采用的一种启发式范式[8]。
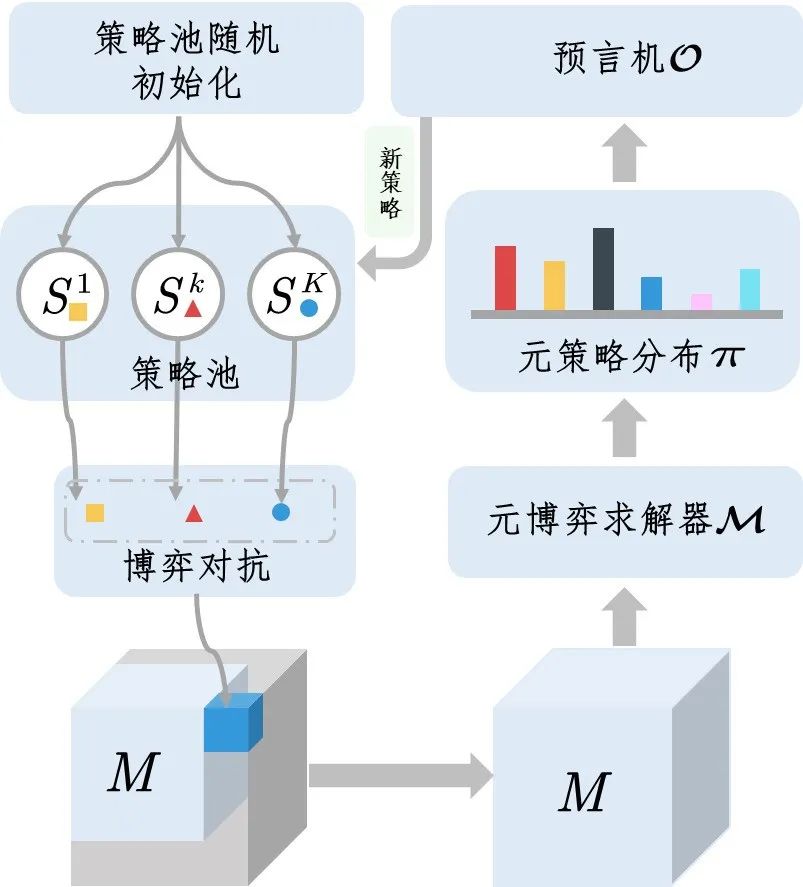
图4 策略空间响应预言机方法
Fig.4 Policy space response oracle methods
3) 基于模型与适变
由于真实博弈过程中,局中人策略通常处于非耦合状态,策略的学习展现出两阶段特点,训练(离线)—测试(在线)各阶段的聚焦点亦有所区别。从“预训练与微调”到“基石模型与情境学习”,基于模型与适变的求解范式为当前博弈问题的求解提供了指引。如图5所示,离线训练与学习和在线测试与适应框架。
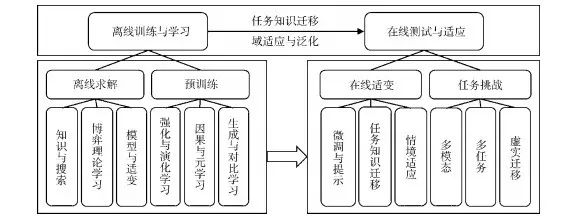
图5 离线训练与学习和在线测试与适应
Fig.5 Offline training & learning and online test & adaptation
3
决策Transformer方法
本章主要从智能博弈问题求解的第 3 种范式切入, 介绍决策 Transformer 的两种实现途径, 重点对比分析架构增强类决策 Transformer 和序列建模类决策Transformer 方法, 分析面临的挑战并进行前沿展望。
3.1 决策 Transformer 基础
3.1.1 Transformer 模型
Transformer 采用了 “编码-解码” 结构, 利用词嵌入与位置嵌入的方式将序列信息进行编码用于网络输入, 内部利用多头注意力网络, 其网络架构如图 6所示.

图 6 Transformer 网络架构
Fig.6 Network architecture for Transformer
由于采用了一次性输入一个序列的方式, 仅用注意力而非卷积来做特征抽取, Transformer 的出现在自然语言处理领域率先引发了变革, 而后扩展至计算机视觉、智能博弈等领域。
3.1.2 典型博弈 Transformer 方法
文本类:由于 Transformer 在自然语言领域取得了重大成就, 一些研究尝试在文本类游戏中运用Transformer。XU 等针对文字冒险类游戏, 设计了基于Transformer 的深度强化学习方法[29]. ADHIKARI 等针对文字类游戏, 设计了一种基Transformer 的动态信念图表示策略学习方法[30]。FURMAN 等针对文字游戏中的问答问题, 设计了基于 GPT-2 因果 Transformer 的序列建模方法[31] 。
棋牌类:NOEVER 等设计了掌握国际象棋玩法的生成语言模型[32];面向围棋, CIOLINO 等设计了基于Transformer 的自然语言建模方法[33]。
视频类:BAKE 等围绕 Minecraft 设计了基于视频的预训练模型, 可以通过观看未标注在线视频来做动作[34].。WEI 等围绕 MPE 环境设计了基于 RNN 与Transformer 的层次 MADDPG 混合合作竞争策略学习方法[35]。REED 等提出具身智能通才智能体 Gato, 嵌入多类标记化信息, 具有同样权重的同样网络可以完成多类仿真控制、视觉与语言、机器人搭积木等任务[36]。
3.1.3 Transformer 架构变换
围绕 Transformer 的典型架构变换方法[37]如图 7所示, 与左侧标准 Transformer 架构不一样的是, 中间TrXL-I 架构将层正则化作为子模块的输入流, 再加上剩余的连接, 就有一个从输出流到输入的梯度路径, 无需任何转换, 右侧 GTrXL 架构, 额外增加了一个门控层, 以取代 TrXL-I 的残差连接。
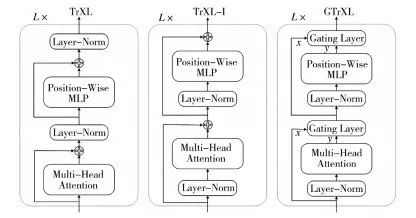
图 7 Transformer 变体网络架构
Fig.7 Network architecture for Transformer variants
3.1.4 离线强化学习与轨迹优化
利用离线强化学习方法获得预训练模型是一类样本利用率高的策略学习方法。与在线强化学习与异策强化学习方法不同, 离线强化学习得到的离线策略可通过微调的方式用于在线与异策强化学习, 如图 8所示。当前主要的离线强化学习方法可分为策略约束类、重要性采样类、正则化学习类、不确定性估计类、基于模型的方法、单步方法、模仿学习类和轨迹优化类[38] 。
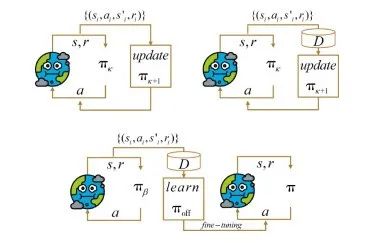
图 8 三类强化学习方法
Fig.8 Three kinds of reinforcement learning methods
作为轨迹优化类方法, 采用同自然语言处理、计算机视觉领域一样的架构, 与颠倒强化学习(upsidedown reinforcement learning, UDRL) [39] 采用监督学习方法不同, 在离线轨迹数据集上训练序列模型, 将过去状态、动作和未来回报(state, action, return-to-go)作为数据模态相关神经网络的输入, 提取线性嵌入,添加位置时间步编码;然后将编码后的 Tokens 输入至因果 Transformer 网络中, 使用因果自注意和掩码自回归的方式预测未来动作。作为一类典型的生成式模型, 与隐变量变分自编码、扩散模型、能量模型不同, 其主要采用基于 Transformer 的自回归序列模型,可利用离线带标签数据进行监督式训练与学习。
3.2 架构增强决策 Transformer
架构增强决策 Transformer 方法是面向决策基石模型的表示学习类方法。
3.2.1 表示学习
维基 Transformer:REID 等提出利用大规模现成的 维 基 百 科 知 识 来 辅 助 训 练 离 线 强 化 学 习 [40]。MINECLIP:FAN 等提出利用大规模的互联网知识来构建开放式具身智能体[41]。TOV-VICReg:GOULAO 等提出利用自监督学习来预训练视觉 Transformer, 可以捕捉连续帧之间的时序关系[42]。Swin Transformer:MENG等提出利用 Swin Transformer 的强化学习方法, 尝试将智能体在环境中的规划输入改成视图输入[43]。视觉Transformer:TAO 等提出利用视觉 Transformer 来处理图像 (像素) 输入和自监督学习方法来训练强化学习策略[44]。IRIS:MICHELI 等提出利用 Transformer 来学习样本效率高的世界模型[45]。
3.2.2 网络组合
DTQN:ESSLINGER 等利用 Transformer 和自注意力来编码智能体的历史信息来求解部分可观强化学习问题[46]。Updet:HU 等基于 Transformer 的模型, 通过使用自注意力机制确定的重要性权重, 将策略分布与 交 织 的 观 测 输 入 解 耦 , 生 成 灵 活 的 策 略 [47]。TransfQMix:GALLICI 等利用 Transformer 来学习潜在图结构, 可以从包含智能体内部和外部状态的大图中学 习 单 调 混 合 函 数 , 具 备 团 队 规 模 扩 展 性 [48]。TransMix:KHAN 等提出基于 Transformer 的值函数分解方法, 学习多个智能体的联合动作混合策略, 具备可扩展性[49]。ATM:YANG 等提出智能体 Transformer记忆网络, 可同时处理顺序工作记忆和其他空间实体信息, 通过动作语义归纳偏差将实体嵌入与动作一一绑定[50]。T3OMVP:YUAN 等引入 Transformer 处理观测序列来实现多车协同, 无需策略解耦[51]。
3.2.3 模型扩展
TrMRL:MELO 提出基于 Transformer 的元强化学习方法, 使用元强化学习智能体模拟记忆恢复机制,将最近的工作记忆联系起来, 通过 Transformer 层递归地建立一个情景记忆[52]。AdA:DEEPMIND 的适变智能体组 提 出 利 用 自 主 课 程 学 习 , 基 于 模 型 的Transformer 强化学习、和蒸馏来实现强化学习基石模型[53]。
围绕架构增强决策 Transformer 的 3 类方法的相关特点如表 2 所示。

3.3序列建模决策 Transformer
序列建模决策 Transformer 方法是面向决策基石模型的条件生成类方法。
3.3.1离线预训练
决策 Transformer:CHEN 等通过将交互序列进行重构, 构造了第 1 个基于轨迹优化离线强化学习的决策 Transformer(decision transofmer, DT) 方法[4]。DT 是一种条件生成行为的方法, 试图将序贯决策问题建模成可用 Transformer 来完成序列生成任务, 从而避免了显式决策过程建模问题和交互数据分布偏离导致的 Q 值过估计问题。 轨迹 Transformer:围绕“轨迹优化” 类离线强化学习, 与决策 Transformer 类似, JANNER等提出轨迹 Transformer(trajectory transformer, TT)方法[54]。TT 是一种条件生成模型的方法, 由于没有采用基于奖励条件的学习方式, 取而代之的是基于集束搜索(Beam Search)的规划方法, 对于长序列建模的准确率有所提高。 自助 Transformer:由于离线数据集无法做到充分的分布覆盖, WANG 等提出自启动 Transformer [55]。该方法结合了自助(bootstrapping)的思想,利用学习到的模型来自我生成更多的离线数据, 以进一步提高序列模型的训练. 双向 Transformer:由于无向模型通常被用来训练根据左测条件信息预测下一个动作, 而双向模型可以同时预测左侧和右侧。CAR原ROLL 等提出利用双向 Transformer 的方法, 可以通过微调更好的适应下游任务[56]。广义决策 Transformer:由于 DT 方法本质上是在利用 “事后信息匹配” (hindsight information matching, HIM)的方式来训练策略,输出符合未来状态信息对应某种分布的最优轨迹。FURUTA 等提出了广义决策 Transformer, 可以求解任意 HIM 问题, 通过选择不同的特征函数和反因果聚合网络, 可以将决策 Transformer 变成该模型的一个特例[57]。对比决策 Transformer:在多任务学习中通过围绕不同任务, 分离输入数据的表示可以提高性能.KONAN 等提出对比 DT 方法, 创建了一个子空间变换层, 可以利用增强对比损失来训练输入嵌入的回报依赖变换[58]。 技能 Transformer:由于利用信息统计形式的未来轨迹信息可以从离线轨迹数据中提取更多信息, SUDHAKARAN 等提出了技能 Transformer 方法, 采用事后重标注和技能发掘来发现多样基元动作或技能, 可以实现离线状态边际匹配 (state-marginalmatching, SMM) , 发掘更便采样的描述性动作[59]。分离潜轨迹 Transformer:如何在需要考虑安全因素的场景中做长线规 划 , CORREIA 等 提 出 了 分 离 潜 轨 迹Transformer 方法, 通过引入两个独立的 Transformer结构网络来表征世界模型与策略模型, 采用类似minmax 搜索的方式, 规划过程中搜索潜变量空间来最小些满足一定约束的策略。当在线安全需求变化时, 固定参数的预训练模型可能无法满足要求。ZHANG 等提出了安全 Transformer 方法, 利用代价相关的 Token来限制动作空间, 并采用后验安全验证来显式地执行约束, 以最大剩余代价为条件, 执行两阶段自回归来生成可行的候选方案, 然后过滤掉不安全的、执行具有最高预期回报的最佳操作 [61]。Q 学习决策 Transformer:由于离线数据集中可能包含次优轨迹, 可能导致学习算法的不稳定性, YAMGATA 等提出了基于 Q学习决策 Transformer 方法, 可以利用动态规划结果对训练数据中的 “未来回报” 进行重标注, 然后用重新标注的数据对决策 Transformer 进行训练[62] 。
3.3.2 在线适变
在线微调:由于决策 Transformer 没有在线自适应模块, 泛化性比较差。ZHENG 等提出了在线 Transformer 方法, 可以针对任务指定的环境, 采用在线微调, 将离线预训练与在线微调合成为一个统一的框架, 利用序列层的熵正则化与自回归建模目标来获得样本利率率高的探索与微调效果[63]。在线提示:围绕在线快速适应, 利用架构归纳偏差对应的少样本学习能力, XU 等提出基于提示的决策 Transformer 方法,利用 Transformer 结构的序列建模能力和提示框架实现离线强化学习的少样本自适应, 设计轨迹提示, 包含几个样本的演示片段, 并对特定于任务的信息进行编码, 以指导策略生[64]。在线迁移:为了适应变化环境,将此前已经掌握的知识应用至未见结构属性的环境中可以提高策略的弹性和效率。BOUSTATI 等提出在决策 Transformer 中应用基于因果反事实推理的迁移学习方法, 采用基于决策 Transformer 架构的蒸馏方法为适应新环境生成策略[65]。超决策 Transformer:为了适应新的任务, 获取“数据-参数”高效的泛化能力,XU 等提出了超决策 Transformer 方法, 利用超网络设计自适应模块, 针对未知任务只需微调自适应模块即可[66]。情境适应:为了提高应对不同情境的适应性能力, LIN 等提出了情境 Transformer, 将情境向量序列与原本输入进行级联来引导条件策略生成, 其次利用元强化学习方法来利用不同任务间的情境, 提升应对未知任务的泛化能力[67]。
3.3.3 模型扩展
多智能体协同:围绕多智能体协同, MENG 等提出多智能体决策 Transformer 方法, 将多智能体离线预训练建模成一个大型序列模型, 可以同时利用离线与在线数据进行训练[68]。WEN 等提出多智能体 Transformer, 利用编码器-解码器框架与多智能体优势函数值分解, 将联合策略搜索问题变换成序列决策问题, 从而保证单调性能提升[69]。LIN 等提出的情境元Transformer, 充分利用场景信息来提高泛化能力[67]。多任务泛化:围绕多类任务, 瞄准提高泛化性, LEE 等提出多游戏决策 Transformer 方法, 基于多类任务场景专家级经典回放数据进行离线学习, 利用专家动作推理的方式持续生成高价值回报行为[70]。为了提高 TT 方法的泛化性, LIN 等提出基于开关(Switch)的轨迹 Transformer. 利用稀疏激活模型来降低多任务离线模型学习中的计算成本, 采用分布轨迹值估计器来提高稀疏奖励场景下的策略性能[71]。多模态协同:围绕多种模态信息输入, SHAFIULLAH 等提出行为 Transformer模型, 可以建模非标注的多模态演示数据, 利用多模态建模能力来预测动作[72]。虚实迁移探索:围绕如何将虚拟仿真器中学习到的优化策略迁移应用于具体的实物中一直以来是值得探索的大挑战。SHANG 等提出基于 “状态-动作-奖励” 的 StARformer 方法, 引入类似马可夫的归纳偏差来改进长程建模[73]。围绕自动驾驶, SUN 等提出控制 Transformer, 运用自监督学习的方式训练以控制为中心的目标, 具备应对预训练与微调之间分布偏移的韧性[74]。围绕真实世界机器人控制问题, BROHAN 等提出了 RT-1 模型[75]。当前, 机器人操控、导航、任务分配和自动驾驶等探索虚实迁移 (sim-to-real) 问题的关键研究领域。
围绕序列建模决策 Transformer 的 3 类方法的相关特点如表 3 所示。
表 3 序列建模决策 Transformer 的各类方法及特点
Table 3 Methods and features of decision Transformer with
sequence modeling

3.4 挑战及展望
3.4.1 面临的挑战
环境模型:由于预训练与微调所对应的场景不同, 分布偏移导致直接利用离线学习策略可能输出次优动作。如何应对随机环境[76]、最优偏差[77]、不确定[78]等都是当前面临的挑战。
博弈预训练:当前多类方法均从是决策理论、优化单方目标的角度设计的, 多方(智能体)的连续 (序贯)对抗场景均可采用基于交互的博弈理论建模, 如何设计面向均衡解的离线博弈学习方法, 考虑离线均衡搜寻[79]、离线博弈对抗数据分布[80]、分析离线博弈策略的可学习性[81]等仍是当前面临的挑战。
情境学习:从一般的小型预训练模型到大型的基石模型, 如何提高模型的适应性仍是当前面临的挑战, 利用情境学习方法[82], 可以逐渐提高算法应对新场景新任务的能力。
3.4.2 前沿发展
Transformer 结构:随着各类基础模型的迭代更新,分布 Transformer 结构的重要性[83] ,改进 Transformer 的结构模型是值得研究的方向。人工智能生成基石模型:与判别式人工智能不同, 生成式人工智能模型探索未知策略空间提供了方法途径, 条件生成建模[84]等生成式人工智能方向值得研究。
多模态交互决策:多种模态信息流转为交互式决策提出了挑战, 如何利用好 Transformer 等架构, 输入自然语言指令[85]和其他不同模态[86]信息值得探索。 此外, 多种模态的基石模型可用作“即插即用” (plugand-play)模块, 辅助智能决策。
4
结论
博弈强对抗环境下,如何响应高动态性、不确定性、高复杂性对抗,给出自适应可信任应对策略,均是智能博弈问题求解的重要课题。方法的集成本质是为了提高问题求解的样本效率、策略的泛化性、鲁棒性、安全性、可信任性等,但如何自洽融合、模块适配求解智能博弈问题仍是一个开放性问题。人工智能算法与GPU算力的完美结合为各研究领域带了范式革命,基于云原生基础设施的决策预训练模型已然到来。
本文介绍了智能博弈问题的3类博弈模型、分析了4类博弈认知模型、给出了智能博弈求解方案,着力设计了智能博弈问题求解的集成框架,深入分析了决策Transformer预训练方法。可以为智能兵棋推演、智能战略博弈、智能蓝军、智能决策辅助等项目提供综合式策略集成学习解决方案。决策基石模型的生成与服务化是一种可行方案,可为分布式对抗场景下的智能指挥决策提供支撑。
References
[1] 黄凯奇, 兴军亮, 张俊格, 等. 人机对抗智能技术 [J]. 中国科学: 信息科学, 2020, 50 (4) : 540-550.
HUANG K Q, XING J L, ZHANG J G, et al. Intelligent technologies of human-computer gaming[J]. SCIENTIA SINICA Informationis, 2020, 50 (4) : 540-550.
[2] BOMMASANI R, HUDSON D A, ADELI E, et al. On the opportunities and risks of foundation models[EB/OL]. (2021-08-16) [2022-10-01]. https://arxiv.org/abs/2108.07258.
[3] DAI Z, YANG Z, YANG Y, et al. Transformer-XL: attentive language models beyond a fixed-length context[C]// Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019: 2978-2988.
[4] CHEN L, LU K, RAJESWARAN A, et al. Decision trans former: reinforcement learning via sequence modeling [C]//Thirty-Fifth Conference on Neural Information Processing Systems, 2021, 34: 15084-15097.
[5] XU P, ZHU X, CLIFTON D A. Multimodal learning with transformers: a survey[EB/OL].(2022-06-13) [2022-10-01].https://arxiv.org/abs/2206.06488.
[6] LI W, LUO H, LIN Z, et al. A survey on transformers in reinforcement learning[EB/OL].(2023-01-08) [2023 -01 -19].https://arxiv.org/abs/2301.03044.
[7] HU S, SHEN L, ZHANG Y, et al. On transforming reinforcement learning with transformers: the development trajectory[EB/OL].(2022-12-29) [2023-01-19]. https://arxiv.org/abs/2212.14164.
[8] SILVER D, SCHRITTWIESER, SIMONYAN K, et al. Mastering the game of Go without human knowledge[J]. Nature,2017, 550 (7676) : 354-359.
[9] SILVER D, HUBERT T, SCHRITTWIESER J, et al. A general reinforcement learning algorithm that masters chess, shogi, and go through self-play[J]. Science, 2018, 362(6419) :1140-1144.
[10] ZHAO E, YAN R, LI J, et al. AlphaHoldem: high-performance artificial intelligence for heads -up no -limit texas hold’ em from end-to-end reinforcement learning[C]// Proceedings of the AAAI Conference on Artificial Intelligence.2022, 36 (4) : 4689-4697.
[11] VINYALS O, BABUSCHKIN I, CZARNECKI W M, et al.Grandmaster level in StarCraft II using multi-agent reinforcement learing[J]. Nature, 2019, 575 (7782) : 350-354.
[12] ERNEST N D. Genetic fuzzy trees for intelligent control of unmanned combat aerial vehicles[D]. Cincinnati: University of Cincinnati, 2015.
[13] DRUBIN C. AlphaDogfight trials foreshadow future of human-machine symbiosis[N/OL]. Challenge Competition, News,R&D.(2020 -08 -06)[2022 -10 -14].https://www.ai.gov/ alphadogfight -trials -foreshadow -future -of -human -machine-symbiosis.
[14] ZACHARIAS G L. Autonomous horizons: the way forward[R]. Washington D.C.: Office of the US Air Force Chief Scientist, 2019.
[15] GEORGE I S. Firestorm AI system prepares for joint role[J].Signal Magzine, 2021, 33: 6-22.
[16] MATTHEW W, LANCE M, EDWARD G, et al. Exploring the feasibility and utility of machine learning-assisted command and control[R]. RAND Corporation, Santa Monica, Calif, 2021.
[17] AFRL's 'Fight Tonight' to prototype ai and gaming tech for attack [EB/OL].(2021 -12 -14)[2022 -09 -01]. https://www.airandspaceforces.com/afrls -fight -tonight -to -prototype-ai-and-gaming-tech-for-attack-planning/.
[18] BAE Systems to tackle computer-generated battle planning that sets up military engagements at machine speed[EB/OL].(2021-08-09) [2022-09-01]. https://www.militaryaerospace.com/computers/article/14284131/battle -planning -computer generated-military-engagements.
[19] YANG Y, WANG J. An overview of multi-agent reinforcement learning from game theoretical perspective [EB/OL].(2021-11-14) [2022-09-01]. https://arxiv.org/abs/2011.00583.
[20] MGUNI D. Stochastic potential games[EB/OL].(2021-03-24) [2022-09-01]. https://arxiv.org/abs/2005.13527.
[21] HU J, WELLMAN M P. Nash Q-learning for general-sum stochastic games[J]. Journal of Machine Learning Research,2003, 4: 1039-1069.
[22] SUN P, XIONG J, HAN L, et al. TLeague: a framework for competitive self -play based distributed multi -agent rein forcement learning[EB/OL].(2020-11-30) [2022-09-01].http://arxiv.org/abs/2011.12895.
[23] ZHOU M, WAN Z, WANG H, et al. MALib: a parallel framework for population-based multi-agent reinforcement learning[EB/OL].(2021-06-05) [2021-08-01]. http://arxiv.org/abs/2106.07551.
[24] ZINKEVICH M, JOHANSON M, BOWLING M, et al. Regret minimization in games with incomplete information[J]. Advances in Neural Information Processing Systems,2007 (20) : 1729-1736.
[25] HEINRICH J, LANCTOT M, SILVER D. Fictious self-play in extensive-form games[C]// International Conference on Machine Learning. PMLR, 2015: 805-813.
[26] LANCTOT M, ZAMBALDI V, GRUSLYS A, et al. A unified game-theoretic approach to multiagent reinforcement learning[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems, 2017: 4193-4206.
[27] TUYLS K, PEROLAT J, LANCTOT M, et al. A generalized method for empirical game theoretic analysis[C]// Proceedings of the 17th International Conference on Autonomous Agents and MultiAgent Systems, Richland, SC, 2018: 77-85.
[28] MULLER P, OMIDSHAFIEI S, ROWLAND M, ET AL. A generalized training approach for multiagent learning [C]//International Conference on Learning Representations, 2019.
[29] XU Y, CHEN Y, FANG M, et al Deep reinforcement learning with transformers for text adventure games[C]// IEEE Conference on Games. Osaka, Japan, 2020: 65-72.
[30] ADHIKARI A, YUAN X, MA C T, et al. Learning dynamic belief graphs to generalize on text-based games[C]// Thirty-Fourth Annual Conference on Neural Information Processing Systems. Vancouver, Canada, 2020: 3045-3057.
[31] FURMAN G, TOLEDO E, SHOCK J, et al. A sequence modelling approach to question answering in text-based games[C]// Association for Computational Linguistics, Gregory Furman, 2022.
[32] NOEVER D, CIOLINO M, KALIN J. The chess transformer: mastering play using generative language models[EB/OL].(2020-08-02) [2022-09-01]. https://arxiv.org/abs/2008.04057.
[33] CIOLINO M, NOEVER D, KALIN J. The go transformer: natural language modeling for game play[C]// 2020 Third International Conference on Artificial Intelligence for Industries(AI4I) , Irvine, CA, USA, 2020:23-26.
[34] BAKE B, AKKAYA I, ZHOKHOV P, et al. Video PreTraining(VPT) : learning to act by watching unlabeled online videos[C]// Thirty-Sixth Annual Conference on Neural Information Processing Systems, New Orleans, 2022.
[35] WEI X, HUANG X, YANG L F, et al. Hierarchical RNNsbased transformers MADDPG for mixed cooperative -competitive environments[J]. Journal of Intelligent & Fuzzy Systems, 2022, 43 (1) : 1011-1022.
[36] REED S, ZOLNA K, PARISOTTO E, et al. A generalist agent[J]. Transactions on Machine Learning Research, 2022:2835-8856.
[37] PARISOTTO E, SONG F, RAE J, et al. Stabilizing transformers for reinforcement learning[C]// International Conference on Machine Learning. PMLR, 2020: 7487-7498.
[38] PRUDENCIO R F, MAXIMO M R O A, COLOMBINI E L.A survey on offline reinforcement learning: taxonomy, re view, and open problems[EB/OL].(2022-03-02) [2022-09-01]. https://arxiv.org/abs/2203.01387.
[39] SRIVASTAVA R K, SHYAM P, MUTZ F, et al. Training agents using upside-down reinforcement learning[EB/OL].(2019-12-05) [2022-09-01]. https://arxiv.org/abs/1912.02877.
[40] REID M, YAMADA Y, GU S S. Can wikipedia help offline reinforcement learning[EB/OL].(2022-01-28) [2022-05-17]. https://arxiv.org/abs/2201.12122.
[41] FAN L, WANG G, JIANG Y, et al. Minedojo: building open-ended embodied agents with internet-scale knowledge[C]// Thirty-sixth Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2022.
[42] GOULAO M, OLIVEIRA A L. Pretraining the vision transformer using self-supervised methods for vision based deep reinforcement learning [C]// Deep Reinforcement Learning Workshop NeurIPS, 2022.
[43] MENG L, GOODWIN M, YAZIDI A, et al. Deep reinforcement learning with swin transformer[EB/OL].(2022-06-30)[2022-09-01]. https://arxiv.org/abs/2206.15269.
[44] TAO T, REDA D, VAN DE PANNE M. Evaluating vision transformer methods for deep reinforcement learning from pixels[EB/OL].(2022-04-11) [2022-09-01]. https://arxiv.org/abs/2204.04905.
[45] MICHELI V, ALONSO E, FLEURET F. Transformers are sample -efficient world models [C]// Deep Reinforcement Learning Workshop NeurIPS, 2022.
[46] ESSLINGER K, PLATT R, AMATO C. Deep transformer Q-networks for partially observable reinforcement learning[C]// NeurIPS 2022 Foundation Models for Decision Making Workshop, 2022.
[47] HU S, ZHU F, CHANG X, et al. UPDET: Universal multiagent reinforcement learning via policy decoupling with transformers[C]// International Conference on Learning Representations. Vienna, Austria, 2021.
[48] GALLICI M, MARTIN M, MASMITJA I. TransfQMix: transformers for leveraging the graph structure of multi-agent reinforcement learning problems[EB/OL].(2023-01-13) [2023-01-19]. https://arxiv.org/abs/2301.05334.
[49] KHAN M J, AHMED S H, SUKTHANKAR G. Transformer-based value function decomposition for cooperative multi-agent reinforcement learning in starcraft[C]// Proceedings of the AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment, 2022, 18 (1) : 113-119.
[50] YANG Y, CHEN G, WANG W, et al. Transformer-based working memory for multiagent reinforcement learning with action parsing[C]// Advances in Neural Information Processing Systems, 2022.
[51] YUAN Z, WU T, WANG Q, et al. T3OMVP: a transformerbased time and team reinforcement learning scheme for observation -constrained multi -vehicle pursuit in urban area[J]. Electronics, 2022, 11 (9) : 1339.
[52] MELO L C. Transformers are meta-reinforcement learners[C]// International Conference on Machine Learning. PMLR,2022: 15340-15359.
[53] TEAM A A, BAUER J, BAUMLI K, et al. Human-timescale adaptation in an open-ended task space[EB/OL].(2023-01-18) [2023-01-19]. https://arxiv.org/abs/2301.07608.
[54] JANNER M, LI Q, LEVINE S. Offline reinforcement learning as one big sequence modeling problem[J]. Advances in Neural Information Processing Systems, 2021, 34: 1273 -1286.
[55] WANG K, ZHAO H, LUO X, et al. Bootstrapped trans former for offline reinforcement learning[C]// Thirty-Sixth Conference on Neural Information Processing Systems. New Orleans, 2022.
[56] CARROLL M, LIN J, PARADISE O, et al. Towards flexible inference in sequential decision problems via bidirectional transformers[C]// ICLR 2022 Workshop on Generalizable Policy Learning in Physical World, 2022.
[57] FURUTA H, MATSUO Y, GU S. Generalized decision transformer for offline hindsight information matching [EB/OL].(2021-11-19) [2022-09-01]. https://arxiv.org/abs/2111.10364.
[58] KONAN S G, SERAJ E, GOMBOLAY M. Contrastive decision transformers[C]// 6th Annual Conference on Robot Learning, 2022.
[59] SUDHAKARAN S, RISI S. Skill decision transformer [EB/OL].(2023-01-31) [2023-02-01]. https://arxiv.org/abs/2301.13573.
[60] VILLAFLOR A R, HUANG Z, PANDE S, et al. Addressing optimism bias in sequence modeling for reinforcement learning[C]// International Conference on Machine Learning.PMLR, 2022: 22270-22283.
[61] ZHANG Q, ZHANG L, XU H, et al. SaFormer: a conditional sequence modeling approach to offline safe reinforcement learning[EB/OL].(2023-01-28) [2023-02-01]. https://arxiv.org/abs/2301.12203.
[62] YAMAGATA T, KHALIL A, SANTOS-RODRIGUEZ R. Qlearning decision transformer: leveraging dynamic programming for conditional sequence modelling in offline RL[EB/OL].(2022-09-08) [2022-10-01]. https://arxiv.org/abs/2209.03993.
[63] ZHENG Q, ZHANG A, GROVER A. Online decision transformer[C]// International Conference on Machine Learning.PMLR, 2022: 27042-27059.
[64] XU M, SHEN Y, ZHANG S, et al. Prompting decision transformer for few-shot policy generalization[C]// International Conference on Machine Learning. PMLR, 2022: 24631-24645.
[65] BOUSTATI A, CHOCKLER H, MCNAMEE D C. Transfer learning with causal counterfactual reasoning in decision transformers[EB/OL].(2021-10-27) [2022-09-01]. https://arxiv.org/abs/2110.14355.
[66] XU M, LU Y, SHEN Y, et al. Hyper-decision transformer for efficient online policy adaptation [C]// NeurIPS 2022 Foundation Models for Decision Making Workshop, 2022.
[67] LIN R, LI Y, FENG X, et al. Contextual transformer for offline meta reinforcement learning[C]// NeurIPS 2022 Foundation Models for Decision Making Workshop, 2022.
[68] MENG L, WEN M, YANG Y, et al. Offline pre-trained multi-agent decision transformer: one big sequence model tackles all SMAC tasks[EB/OL].(2021-12-06) [2022-09-01]. https://arxiv.org/abs/2112.02845.
[69] WEN M, KUBA J G, LIN R, et al. Multi-agent reinforcement learning is a sequence modeling problem [EB/OL].(2022-05-30) [2022-09-01]. https://arxiv.org/abs/2205.14953.
[70] LEE K H, NACHUM O, YANG S, et al. Multi-Game decision transformers[C]// Thirty-Sixth Conference on Neural Information Processing Systems. New Orleans, 2022.
[71] LIN Q, LIU H, SENGUPTA B. Switch trajectory transformer with distributional value approximation for multi-task reinforcement learning[EB/OL].(2022-03-14) [2022-09-01].https://arxiv.org/abs/2203.07413.
[72] MAHI SHAFIULLAH N M, CUI Z J, ALTANZAYA A, et al. Behavior transformers: cloning k modes with one stone[EB/OL].(2022-06-22) [2022-10-01]. https://arxiv.org/abs/2206.11251.
[73] SHANG J, LI X, KAHATAPITIYA K, et al. StARformer: transformer with state -action -reward representations for robot learning[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2022, 26: 67-76.
[74] SUN Y, MA S, MADAAN R, et al. SMART: self-supervised multi-task pretraining with control transformers[EB/OL].(2023-01-24) [2023-02-01]. https://arxiv.org/abs/2301.09816.
[75] BROHAN A, BROWN N, CARBAJAL J, et al. RT -1:robotics transformer for real-world control at scale[EB/OL].(2012-12-13) [2022-09-01]. https://arxiv.org/abs/2212.06817.
[76] PASTER K, MCILRAITH S, BA J. You can't count on luck: why decision transformers fail in stochastic environments[EB/OL].(2022-05-31) [2022-09-01]. https://arxiv.org/abs/2205.15967.
[77] VILLAFLOR A R, HUANG Z, PANDE S, et al. Addressing optimism bias in sequence modeling for reinforcement learning[C]// International Conference on Machine Learning.PMLR, 2022: 22270-22283.
[78] NGUYEN T, GROVER A. Transformer neural processes: uncertainty-aware meta learning via sequence modeling[C]//International Conference on Machine Learning. PMLR, 2022:16569-16594.
[79] LI S, WANG X, CERNY J, et al. Offline equilibrium finding[EB/OL].(2022-07-12) [2022-09-01]. https://arxiv.org/abs/2207.05285.
[80] ZHONG H, XIONG W, TAN J, et al. Pessimistic minimax value iteration: provably efficient equilibrium learning from offline datasets[C]// International Conference on MachineLearning. PMLR, 2022: 27117-27142.
[81] DUAN Z, ZHANG D, HUANG W, et al. Is Nash equilibrium approximator learnable[EB/OL].(2021-08-17) [2022-09-01]. https://arxiv.org/abs/2108.07472.
[82] LASKIN M, WANG L, OH J, et al. In-context reinforcement learning with algorithm distillation[EB/OL].(2022-10-25) [2022-11-02]. https://arxiv.org/abs/2210.14215.
[83] SIEBENBORN M, BELOUSOV B, HUANG J, et al. How crucial is transformer in decision transformer[C]// NeurIPS 2022 Foundation Models for Decision Making Workshop,2022.
[84] AJAY A, DU Y, GUPTA A, et al. Is conditional generative modeling all you need for decision-making[EB/OL].(2022-11-28) [2022-12-17]. https://arxiv.org/abs/2211.15657.
[85] LI X, ZHANG Y, LUO J, et al. Pre-trained bert for natural language guided reinforcement learning in atari game[C]//34th Chinese Control and Decision Conference. IEEE, 2022:5119-5124.
[86] TAKAGI S. On the effect of pre-training for transformer in different modality on offline reinforcement learning [C]//Thirty-Sixth Conference on Neural Information Processing Systems. New Orleans, 2022.
作者简介
罗俊仁 (1989-) , 男, 博士研究生, 主要研究方向为不完美信息博弈、多智能体学习。
张万鹏 (1981-) , 男, 博士, 研究员, 博士生导师, 主要研究方向为大数据智能、智能演进。
苏炯铭 (1984-) , 男, 博士, 副研究员, 主要研究方向为智能博弈、可解释性学习。
王 尧 (1996-) , 男, 硕士研究生, 主要研究方向为演化强化学习。
陈 璟 (1972-) , 男, 博士, 教授, 博士生导师, 主要研究方向为认知决策博弈、分布式智能。
未来智能实验室的主要工作包括:建立AI智能系统智商评测体系,开展世界人工智能智商评测;开展互联网(城市)大脑研究计划,构建互联网(城市)大脑技术和企业图谱,为提升企业,行业与城市的智能水平服务。每日推荐范围未来科技发展趋势的学习型文章。目前线上平台已收藏上千篇精华前沿科技文章和报告。
如果您对实验室的研究感兴趣,欢迎加入未来智能实验室线上平台。扫描以下二维码或点击本文左下角“阅读原文”

本文链接:https://my.lmcjl.com/post/11267.html
4 评论