本地部署 privateGPT
- 1. 什么是 privateGPT
- 2. Github 地址
- 3. 创建虚拟环境
- 4. 部署 privateGPT
- 5. 配置 .env
- 6. 下载模型
- 7. 将文件放入 source_documents 目录中
- 8. 摄取所有数据
- 9. 向本地文档提问
1. 什么是 privateGPT
利用 GPT 的强大功能,私密地与您的文档交互,100% 保密,绝不泄露任何数据。
使用 LLMs 的能力,在没有互联网连接的情况下向您的文档提问,100%保密,您的执行环境没有任何数据离开。您可以在没有互联网连接的情况下摄取文档并提问!
使用 LangChain、GPT4All、LlamaCpp、Chroma 和 SentenceTransformers 等技术构建。
2. Github 地址
https://github.com/imartinez/privateGPT
3. 创建虚拟环境
conda create -n privategpt python==3.10.6
conda activate privategpt conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia
4. 部署 privateGPT
克隆项目,
git clone https://github.com/imartinez/privateGPT; cd privateGPT/
安装依赖,
pip install -r requirements.txt
5. 配置 .env
将 example.env 重命名为 .env 并适当编辑变量,
cp example.env .env
6. 下载模型
mkdir models
wget https://gpt4all.io/models/ggml-gpt4all-j-v1.3-groovy.bin -O ./models/ggml-gpt4all-j-v1.3-groovy.bin
7. 将文件放入 source_documents 目录中
将任何和所有文件放入 source_documents 目录中。支持的文件扩展名有:
- .csv: CSV 文件,
- .docx: Word 文件,
- .doc: Word 文件,
- .enex: EverNote 文件,
- .eml: 邮件
- .epub: EPub 文件
- .html: HTML 文件,
- .md: Markdown 文件,
- .msg: Outlook 消息,
- .odt: Open Document Text 文件,
- .pdf: 可移植文档格式(PDF)文件,
- .pptx: PowerPoint 文件,
- .ppt: PowerPoint 文件,
- .txt: 文本文件(UTF-8)
8. 摄取所有数据
运行以下命令以摄取所有数据,
python ingest.py
9. 向本地文档提问
python privateGPT.py
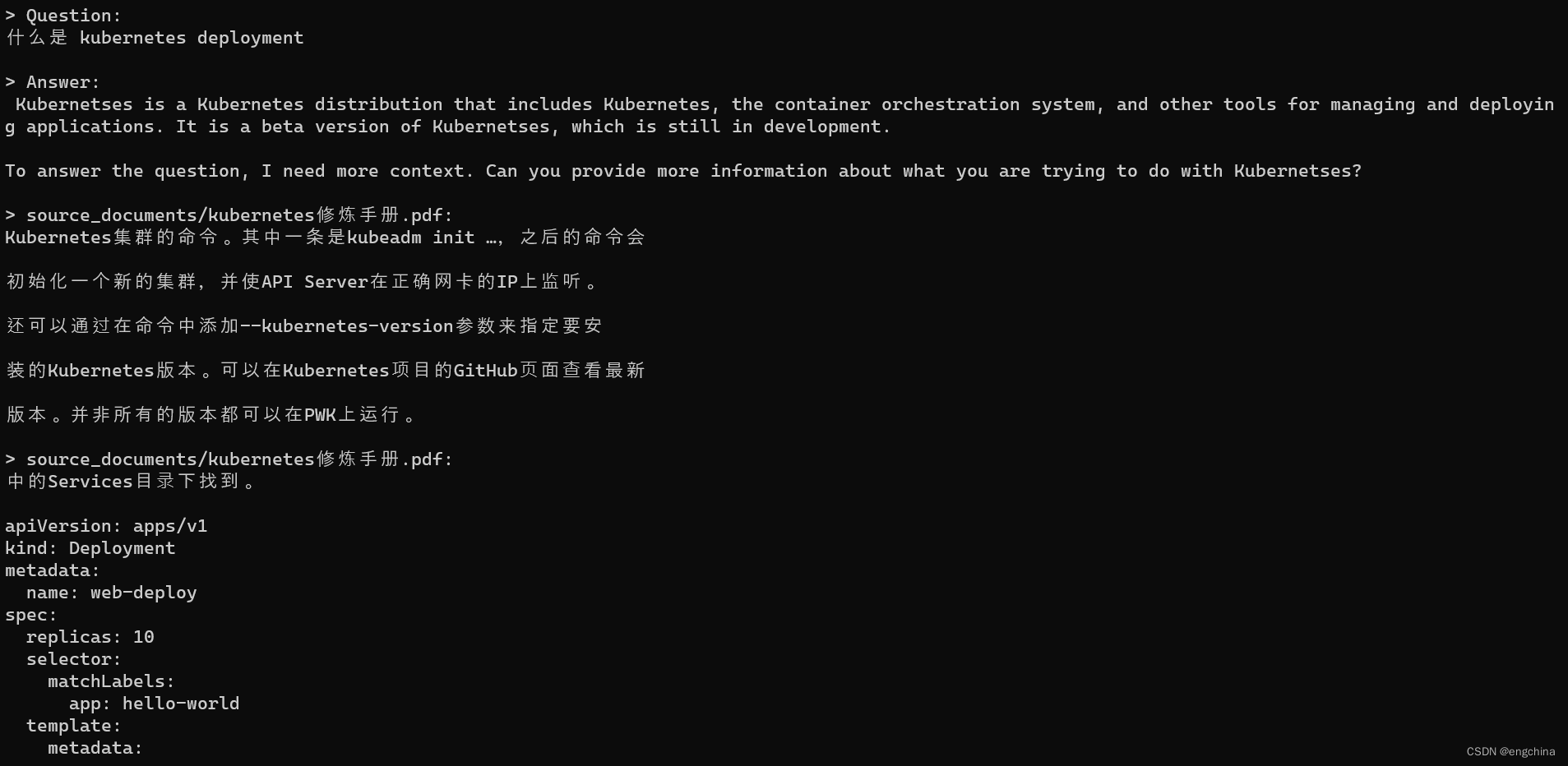
作为测试,我导入了一个 “kubernetes修炼手册.pdf” 文件,问了 “什么是 kubernetes deployment”,回答结果如截屏所示。个人觉得这种回答,完全不可以使用。
完结!
本文链接:https://my.lmcjl.com/post/11393.html
展开阅读全文
4 评论