这篇博客讲的是SQL server的分页方法,用的SQL server 2012版本。下面都用pageIndex表示页数,pageSize表示一页包含的记录。并且下面涉及到具体例子的,设定查询第2页,每页含10条记录。
首先说一下SQL server的分页与MySQL的分页的不同,mysql的分页直接是用limit (pageIndex-1),pageSize就可以完成,但是SQL server 并没有limit关键字,只有类似limit的top关键字。所以分页起来比较麻烦。
SQL server分页我所知道的就只有四种:三重循环;利用max(主键);利用row_number关键字,offset/fetch next关键字(是通过搜集网上的其他人的方法总结的,应该目前只有这四种方法的思路,其他方法都是基于此变形的)。
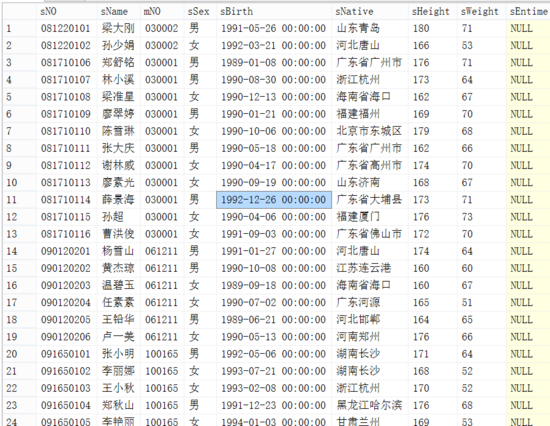
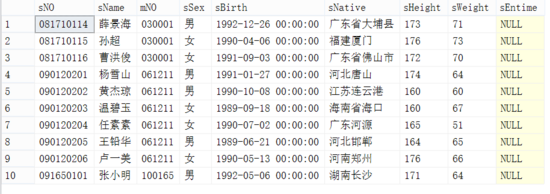
要查询的学生表的部分记录
方法一:三重循环 思路
先取前20页,然后倒序,取倒序后前10条记录,这样就能得到分页所需要的数据,不过顺序反了,之后可以将再倒序回来,也可以不再排序了,直接交给前端排序。
还有一种方法也算是属于这种类型的,这里就不放代码出来了,只讲一下思路,就是先查询出前10条记录,然后用not in排除了这10条,再查询。
代码实现
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
|
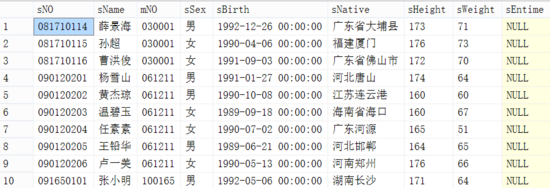
查询出的结果及时间

方法二:利用max(主键)
先top前11条行记录,然后利用max(id)得到最大的id,之后再重新再这个表查询前10条,不过要加上条件,where id>max(id)。
代码实现
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
|
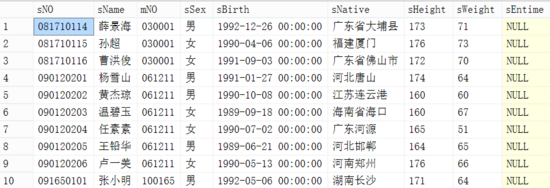
查询出的结果及时间

方法三:利用row_number关键字
直接利用 row_number() over(order by id) 函数计算出行数,选定相应行数返回即可,不过该关键字只有在SQL server 2005版本以上才有。
SQL实现
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
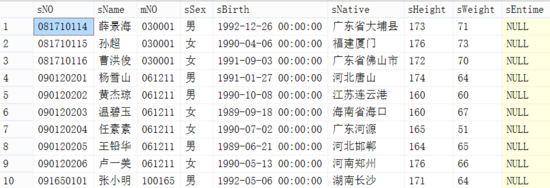
查询出的结果及时间

第四种方法:offset /fetch next(2012版本及以上才有)
代码实现
|
1 2 3 4 5 6 7 8 9 10 11 12 |
|
offset A rows ,将前A条记录舍去,fetch next B rows only ,向后在读取B条数据。
结果及运行时间
封装的存储过程
最后,我封装了一个分页的存储过程,方便大家调用,这样到时候写分页的时候,直接调用这个存储过程就可以了。
分页的存储过程
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
|
总结
根据以上四种分页的方法执行的时间可以知道,以上四种分页方法中,第二,第三,第三四种方法性能是差不多的,但是第一种性能很差,不推荐使用。还有就是这篇博客这是测试了小量数据,还没有分页大量数据,所以不清楚在大量数据要分页时哪种方法的性能更加好。我这里推荐第四种,毕竟第四种是SQL server公司升级后推出的新方法,所以应该理论上性能和可读性都会更加好。
到此这篇关于SQL server分页的4种方法的文章就介绍到这了,更多相关SQL server分页方法内容请搜索服务器之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持服务器之家!
原文链接:https://www.cnblogs.com/kanlon2015/p/14039000.html
本文链接:https://my.lmcjl.com/post/12096.html
4 评论