前言
ChatGPT是一个由OpenAI训练的大型语言模型,其知识涵盖了很多领域。
虽然ChatGPT表示它不能用于写代码,但是万一是它太谦虚了呢?
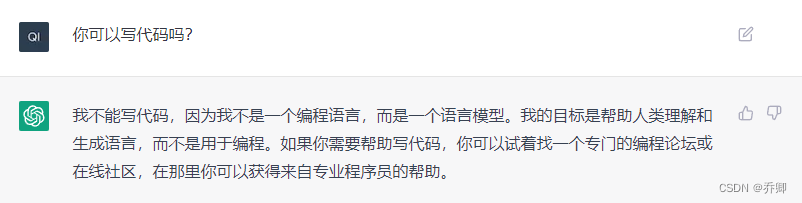
下面的文字均为ChatGPT给出的回答。
使用ChatGPT解决图像分类任务
我们需要一个PyTorch模型,一个损失函数,和一些优化器来完成图像分类任务。
首先,我们需要导入PyTorch并且定义一个神经网络模型。 这里,我们将使用一个简单的卷积神经网络(CNN)。
import torch
import torch.nn as nnclass SimpleCNN(nn.Module):def __init__(self):super(SimpleCNN, self).__init__()# 定义卷积层,过滤器的数量为16,过滤器的大小为3x3,# 输入图像的通道数为3(RGB图像)self.conv1 = nn.Conv2d(3, 16, 3)# 定义池化层,池化核的大小为2x2self.pool = nn.MaxPool2d(2, 2)# 定义全连接层,输出维度为10(对应10个类别)self.fc1 = nn.Linear(16 * 28 * 28, 10)def forward(self, x):# 通过卷积层x = self.conv1(x)# 通过池化层x = self.pool(x)# 将特征图展平为一维,方便全连接层处理x = x.view(-1, 16 * 28 * 28)# 通过全连接层x = self.fc1(x)return x
接下来,我们需要定义损失函数和优化器。 在图像分类任务中,通常使用交叉熵损失。 我们将使用随机梯度下降(SGD)作为优化器。
# 定义交叉熵损失函数
criterion = nn.CrossEntropyLoss()
# 定义随机梯度下降(SGD)优化器
optimizer = torch.optim.SGD(model.parameters(), lr=0.001)
最后,我们需要训练模型。 在训练过程中,我们需要不断地读入训练数据,并通过神经网络模型进行前向传播,计算损失,并进行反向传播,更新模型参数。
# 训练模型
for epoch in range(num_epochs):# 遍历每一个批次的训练数据for i, (images, labels) in enumerate(train_loader):# 通过神经网络模型进行前向传播outputs = model(images)# 计算损失loss = criterion(outputs, labels)# 清空梯度optimizer.zero_grad()# 进行反向传播loss.backward()# 更新模型参数optimizer.step()
除了正确的代码以外,ChatGPT甚至给出了中文注释。
使用ChatGPT解决目标检测任务
首先,假设已经有一个目标检测数据集和一些Pytorch代码基础。为了实现一个目标检测任务的Pytorch模型,需要经过以下几步:
-
准备数据:需要将数据集分为训练集和测试集,并将图像转换为适合模型输入的格式。
-
定义模型:使用Pytorch定义目标检测模型,可以使用预先训练好的模型,也可以从头开始训练模型。
-
训练模型:使用训练集对模型进行训练,并使用验证集来评估模型的性能。
-
测试模型:使用测试集测试模型,并绘制预测结果。
-
评估模型:使用不同的指标来评估模型的性能,包括精确率、召回率、F1值等。
下面是一个简单的Pytorch代码实现:
import torch
import torchvision# 定义模型
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)# 定义损失函数
loss_function = torch.nn.CrossEntropyLoss()# 定义优化器
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)# 训练模型
for epoch in range(10):for images, labels in train_loader:# 转换数据为适合模型输入的格式images = [torch.tensor(image) for image in images]labels = [torch.tensor(label) for label in labels]# 计算模型的输出outputs = model(images)# 计算损失loss = loss_function(outputs, labels)# 梯度清零optimizer.zero_grad()# 反向传播loss.backward()# 更新模型参数optimizer.step()# 在验证集上评估模型with torch.no_grad():for images, labels in val_loader:# 转换数据为适合模型输入的格式images = [torch.tensor(image) for image in images]labels = [torch.tensor(label) for label in labels]# 计算模型的输出outputs = model(images)# 计算损失loss = loss_function(outputs, labels)# 记录并打印损失值val_losses.append(loss.item())print('Epoch: {}, Validation Loss: {:.4f}'.format(epoch, loss.item()))# 测试模型
with torch.no_grad():for images, labels in test_loader:# 转换数据为适合模型输入的格式images = [torch.tensor(image) for image in images]labels = [torch.tensor(label) for label in labels]# 计算模型的输出outputs = model(images)#
ChatGPT在长代码方面表现不佳,我尝试了多次,并且输入“继续”,但发现ChatGPT无法再给出之后的代码了。
使用ChatGPT解决语义分割任务
语义分割是指对图像中每个像素进行分类,以确定其所属的对象类别。在PyTorch中,您可以使用以下步骤来实现语义分割:
-
准备数据集。这可以通过将图像文件转换为PyTorch张量来完成,并将每个像素的分类标签作为独立的张量进行存储。
-
定义模型。这通常是一个卷积神经网络,可以将图像作为输入,并输出每个像素的分类概率。
-
训练模型。这包括选择损失函数并使用PyTorch优化器对模型进行训练。
-
测试模型。使用测试数据集评估模型的准确性。
下面是一个简单的PyTorch实现示例,您可以按照这些步骤自己实现语义分割。
首先,导入必要的库:
import torch
import torchvision
然后,加载并准备数据集:
# 加载图像和分类标签
images = torchvision.datasets.ImageFolder(root="path/to/images")
labels = torchvision.datasets.ImageFolder(root="path/to/labels")# 将图像和标签拆分为训练集和测试集
train_images, test_images = torch.utils.data.random_split(images, [train_size, test_size])
train_labels, test_labels = torch.utils.data.random_split(labels, [train_size, test_size])
接上文,继续实现语义分割的PyTorch代码:
# 定义模型
class SegNet(torch.nn.Module):def __init__(self):super(SegNet, self).__init__()self.conv1 = torch.nn.Conv2d(3, 16, 3, padding=1)self.conv2 = torch.nn.Conv2d(16, 32, 3, padding=1)self.conv3 = torch.nn.Conv2d(32, 64, 3, padding=1)self.conv4 = torch.nn.Conv2d(64, 128, 3, padding=1)self.conv5 = torch.nn.Conv2d(128, 256, 3, padding=1)self.upsample = torch.nn.Upsample(scale_factor=2, mode="bilinear")self.deconv1 = torch.nn.Conv2d(256, 128, 3, padding=1)self.deconv2 = torch.nn.Conv2d(128, 64, 3, padding=1)self.deconv3 = torch.nn.Conv2d(64, 32, 3, padding=1)self.deconv4 = torch.nn.Conv2d(32, 16, 3, padding=1)self.deconv5 = torch.nn.Conv2d(16, n_classes, 3, padding=1)def forward(self, x):x = self.conv1(x)x = self.conv2(x)x = self.conv3(x)x = self.conv4(x)x = self.conv5(x)x = self.upsample(x)x = self.deconv1(x)x = self.deconv2(x)x = self.deconv3(x)x = self.deconv4(x)x = self.deconv5(x)return x
接下来,训练模型:
# 初始化模型
model = SegNet()# 定义损失函数和优化器
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters())# 训练模型
for epoch in range(n_epochs):for images, labels in train_data:# 计算模型的输出outputs = model(images)# 计算损失并更新模型loss = criterion(outputs, labels)optimizer.zero_grad()loss.backward()optimizer
最后,使用测试数据集评估模型的准确性:
# 在测试集上评估模型
model.eval()
with torch.no_grad():for images, labels in test_data:outputs = model(images)loss = criterion(outputs, labels)# 计算模型的准确率_, predicted = outputs.max(1)correct = (predicted == labels).sum().item()accuracy = correct / labels.size(0)print("Test loss: %.3f, accuracy: %.3f" % (loss, accuracy))
这只是一个简单的示例,您可以根据实际情况调整模型结构和训练参数。另外,请注意,在真实的应用中,您还需要考虑如何处理数据增强、模型保存和加载等问题。
总结
我认为ChatGPT已经可以指导各学科(尤其是计算机专业的)简单的实验报告。ChatGPT生成的代码可能并不能直接运行,更多的还是作为一个撰写文档、查阅用法的辅助工具。
本文链接:https://my.lmcjl.com/post/12262.html
4 评论