★★★ 本文源自AlStudio社区精品项目,【点击此处】查看更多精品内容 >>>

参考项目地址:https://github.com/Hello-SimpleAI/chatgpt-comparison-detection
本项目 Demo 地址:https://aistudio.baidu.com/aistudio/projectdetail/5691205
项目介绍
ChatGPT 是由 OpenAI 开发的一种基于人工智能技术的语言模型,它能够自动回答用户的问题,并生成文本响应。在过去一年中,ChatGPT 已经成为了人工智能领域的一个热门话题,引起了广泛的关注和讨论。
一方面,ChatGPT 的应用前景非常广阔。例如,它可以用于自然语言处理、智能客服、聊天机器人、在线问答等领域。另一方面,ChatGPT生成的文本也可能存在一些问题,比如不真实、不可信、不友善、不合法等。这些问题可能给用户带来误导或欺骗的风险,也可能给社会带来负面的影响。因此,需要对 ChatGPT 进行检测和评估,以确保其安全性和可靠性。
检测和评估 ChatGPT 的方法和技术有很多种,例如基于特定词频判断、基于PTM的分类器、基于深度学习模型、基于语言学特征的模型等等。
本项目使用 ERNIE 模型来对文本进行二分类,来达到 ChatGPT 文本检测的效果。
数据说明
HC3 数据集 至今已经收集了中英文的 3-4 万个问题和近 10 万条「人类-ChatGPT 对比」回答语料,涵盖了开放域、计算机科学、金融、医疗、法律、心理等多个领域。这批语料集从各个领域,反映了人类专家和 ChatGPT 在面对同一个问题时会有怎么不同的回答。
本项目采用 HC3-Chinese 中文文本问答数据集。我们对原始数据集进行了处理,将原本的 JSONL 格式转换为 CSV 格式,并清除了文本中的部分转义符和无意义符号,最后选取了一些适合在 AI Studio 训练的领域的文本合并成了 data.csv。所有的数据操作过程可见 /home/aistudio/data/data_processing.ipynb。
现有数据集包括 文本 id、文本内容和标签,文件名为 data.csv,各字段以 , 分隔,格式如下:
- id,样本 ID
- text,人类或 ChatGPT 回答的文本内容
- label,回答分类标签
| id | text | label |
|---|---|---|
| 341 | 没有特异的疗效,脑出血恢复期主要是功能锻炼和防止再复发:关键是治疗高血压,糖尿病,等危险因素… | 0 |
| 12567 | 在劳动合同期内,或未签订劳动合同,用人单位单方面无缘由解除劳动关系的,劳动者可获得工作每满一… | 0 |
| 4786 | 超频(overclocking)是指在计算机硬件系统的规定范围之外提高其工作频率的操作。这样… | 1 |
数据读取
!unzip -o /home/aistudio/data/data202733/HC3-Chinese.zip -d /home/aistudio/data # 解压原始数据集
!unzip -o /home/aistudio/data/data202734/chatgpt-comparison-detection.zip -d /home/aistudio/data # 解压清洗后的数据集和模型参数文文件
%pip install wordcloud # 词云
import numpy as np
import pandas as pd
from tqdm import tqdm
import paddle
from paddlenlp.transformers import AutoModelForSequenceClassification, AutoTokenizer
from paddle.io import Dataset, DataLoader
from paddlenlp.datasets import MapDataset
from sklearn.model_selection import train_test_split
from visualdl import LogWriter
import matplotlib.pyplot as plt
import jieba
from wordcloud import WordCloud, ImageColorGenerator
# 随机抽取三条数据查看内容
data = pd.read_csv("/home/aistudio/data/data.csv")
data.sample(frac=1).head(3)
| id | text | label | |
|---|---|---|---|
| 15872 | 5882 | SUMPRODUCT函数是一个Excel函数,它可以将一组数字的乘积相加起来。它的语法为:S... | 1 |
| 13148 | 3158 | 《瑞普·凡·温克尔的新娘》是一部讲述瑞普·凡·温克尔的真实故事的电影。该电影由岩井俊二导演,... | 1 |
| 3154 | 3154 | 想到哪写到哪吧! 1落米问题:米从高处的出米口处落下,初速为零,流量不变。米落在一个秤盘上,... | 0 |
模型选取
这是个经典的文本二分类任务,使用 ernie-3.0-base-zh 模型分类,用交叉熵作为损失函数,我们将数据处理后只保留了回答的文本,方便直接进行单文本分类预测。
# 载入模型与分词器
model = AutoModelForSequenceClassification.from_pretrained("ernie-3.0-base-zh", num_classes=2)
tokenizer = AutoTokenizer.from_pretrained("ernie-3.0-base-zh")optimizer = paddle.optimizer.AdamW(1e-5, parameters=model.parameters())
loss_fn = paddle.nn.loss.CrossEntropyLoss(reduction='mean')
句子分析
我们发现大部分句子长度集中在 200-300 词左右,最大的文本已经达到 2800 词,这对模型来说是个十分大的调整,为了兼顾推理速度和精度,尽可能模拟日常对话文本,我们将模型预测词大小限制在 70 词。
# 句子长度分布图
data['text'].apply(len).plot(kind='box')
plt.title('Data')
Text(0.5,1,'Data')
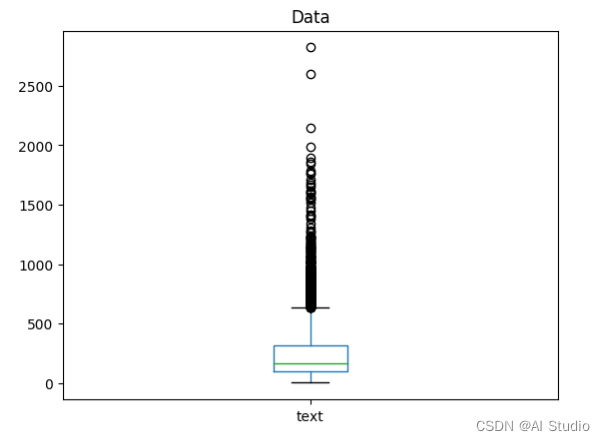
# 句子长度分布数据
data['text'].apply(len).describe()
count 19981.000000
mean 231.086832
std 195.019974
min 2.000000
25% 98.000000
50% 164.000000
75% 314.000000
max 2822.000000
Name: text, dtype: float64
我们同样也发现 ChatGPT 的文本中会出现大量有特点的词汇,这是文本分类器的突破口。
# 句子高频词词云
content = ''.join(data.loc[data["label"] == 1, "text"])
wordcloud = WordCloud(background_color = 'white', max_words = 1000, font_path = '/home/aistudio/data/STHeiti-Light.ttc')
wordcloud.generate(''.join(jieba.lcut(content)))
plt.imshow(wordcloud)
plt.xticks([]); plt.yticks([])
([], <a list of 0 Text yticklabel objects>)

标签比例分析
由于文本问答的特殊性,数据集同时包含了人类文本和对应的 ChatGPT 文本,不配对的文本已经在数据清洗时丢弃,标签分布非常均匀。
# 标签分布图
data["label"].value_counts().plot(kind="pie").text(1, 1, f"{data['label'].value_counts()}")
Text(1,1,'1 9991\n0 9990\nName: label, dtype: int64')
模型训练
# 按照 10% 的比例划分训练集与验证集
train_data, valid_data = train_test_split(data, test_size=0.1)train_dict = train_data.to_dict(orient='records')
valid_dict = valid_data.to_dict(orient='records')
train_ds = MapDataset(train_dict)
valid_ds = MapDataset(valid_dict)
train_loader = DataLoader(train_dict, batch_size=2, shuffle=True)
valid_loader = DataLoader(valid_dict, batch_size=2)with LogWriter(logdir="/home/aistudio/log/ernie/train") as writer:for epoch in range(30):# 训练过程model.train()for batch_x in tqdm(train_loader):X = tokenizer(batch_x["text"], max_length=70, padding=True)input_ids = paddle.to_tensor(X['input_ids'], dtype="int32")token_type_ids = paddle.to_tensor(X['token_type_ids'], dtype="int32")pred = model(input_ids, token_type_ids)loss = loss_fn(pred, paddle.to_tensor(batch_x["label"], dtype="int32"))loss.backward()optimizer.step()optimizer.clear_gradients()# 验证过程model.eval()val_loss = []with paddle.no_grad():for batch_x in tqdm(valid_loader):X = tokenizer(batch_x["text"], max_length=70, padding=True)input_ids = paddle.to_tensor(X['input_ids'], dtype="int32")token_type_ids = paddle.to_tensor(X['token_type_ids'], dtype="int32")pred = model(input_ids, token_type_ids)loss = loss_fn(pred, paddle.to_tensor(batch_x["label"], dtype="int32"))val_loss.append(loss.item())writer.add_scalar(tag="loss", step=epoch, value=np.mean(val_loss))print('Epoch {0}, Val loss {1:3f}, Val Accuracy {2:3f}'.format(epoch,np.mean(val_loss), (pred.argmax(1) == batch_x["label"]).astype('float').mean().item()))
# 保存Layer参数
paddle.save(model.state_dict(), "/home/aistudio/model.pdparams")
# 保存优化器参数
paddle.save(optimizer.state_dict(), "/home/aistudio/optimizer.pdopt")
训练参数载入
# 载入模型参数、优化器参数和最后一个epoch保存的检查点
layer_state_dict = paddle.load("/home/aistudio/work/model.pdparams")
opt_state_dict = paddle.load("/home/aistudio/work/optimizer.pdopt")# 将load后的参数与模型关联起来
model.set_state_dict(layer_state_dict)
optimizer.set_state_dict(opt_state_dict)
如果想使用已训练好的模型,直接运行下面的代码
# layer_state_dict = paddle.load("/home/aistudio/data/model.pdparams")
# model.set_state_dict(layer_state_dict)
模型预测
def infer(string):softmax = paddle.nn.Softmax()X = tokenizer([string], max_length=70, padding=True)input_ids = paddle.to_tensor(X['input_ids'], dtype="int32")token_type_ids = paddle.to_tensor(X['token_type_ids'], dtype="int32")pred = model(input_ids, token_type_ids)print(f"text: {string}\n")print(f"label: {pred.argmax(1)} \n probability: {softmax(pred).max().item()}")
标签为 0 的代表可能是人类撰写的文本
infer("根据你的描述属于检查肾脏感染的,需要检查确诊后治疗,配合抗生素抗感染治疗,清热解毒治疗,增加营养补充维生素补充蛋白质。,对患者来说,泌尿外科疾病问题一直困扰患者,病情严重就要及时对症治疗,合理用药,否则会导致疾病再次病发,除此之外,患者还需要保持心情愉快,以免加重病情,这样有利于健康恢复!")
text: 根据你的描述属于检查肾脏感染的,需要检查确诊后治疗,配合抗生素抗感染治疗,清热解毒治疗,增加营养补充维生素补充蛋白质。,对患者来说,泌尿外科疾病问题一直困扰患者,病情严重就要及时对症治疗,合理用药,否则会导致疾病再次病发,除此之外,患者还需要保持心情愉快,以免加重病情,这样有利于健康恢复!label: Tensor(shape=[1], dtype=int64, place=Place(cpu), stop_gradient=True,[0]) probability: 0.9999372959136963
标签为 1 的代表可能由 ChatGPT 生成
infer("我无法确定招联好期贷是否是正规的。如果你对这家公司有任何疑问,我建议你直接向他们进行询问,或者向相关主管部门寻求帮助。")
text: 我无法确定招联好期贷是否是正规的。如果你对这家公司有任何疑问,我建议你直接向他们进行询问,或者向相关主管部门寻求帮助。label: Tensor(shape=[1], dtype=int64, place=Place(cpu), stop_gradient=True,[1]) probability: 0.9999421834945679
834945679
总结与展望
本项目很大程度上参考了:2022人民网算法赛:微博话题识别任务(ERNIE文本分类)。
目前只是用了非常简单的方式来进行直接的文本分类,但是在实际文本中检测时效果不错,并且不仅适用于 ChatGPT,同样适用于 文心一言 、New Bing 等 LLMs。在 How Close is ChatGPT to Human Experts? Comparison Corpus, Evaluation, and Detection,作者们从多个方面分析了预测 ChatGPT 文本的可行性,并且发布了 Demo,非常值得一读。
同类项目还有 DetectGPT: Zero-Shot Machine-Generated Text Detection using Probability Curvature 和 GPTZero。
本项目还有很多可以改进和深入挖掘的工作:
- 预测限制在 70 词,在文字数量较少的情况下,模型预测不稳定,容易出现误判。
- 如维基百科等结构化的人类文本容易误判为 ChatGPT 生成。
- 目前数据集话题覆盖不充分,只适用于特定领域的文本。
- 模型结构简单,后续可以加入对抗训练来增强模型的稳健性
此文章为转载
原文链接
本文链接:https://my.lmcjl.com/post/13282.html
4 评论