01、多线程下扩容会死循环
众所周知,HashMap 是通过拉链法来解决哈希冲突的,也就是当哈希冲突时,会将相同哈希值的键值对通过链表的形式存放起来。
JDK 7 时,采用的是头部插入的方式来存放链表的,也就是下一个冲突的键值对会放在上一个键值对的前面(同一位置上的新元素被放在链表的头部)。扩容的时候就有可能导致出现环形链表,造成死循环。
resize 方法的源码:
// newCapacity为新的容量
void resize(int newCapacity) {
// 小数组,临时过度下
Entry[] oldTable = table;
// 扩容前的容量
int oldCapacity = oldTable.length;
// MAXIMUM_CAPACITY 为最大容量,2 的 30 次方 = 1<<30
if (oldCapacity == MAXIMUM_CAPACITY) {
// 容量调整为 Integer 的最大值 0x7fffffff(十六进制)=2 的 31 次方-1
threshold = Integer.MAX_VALUE;
return;
}
// 初始化一个新的数组(大容量)
Entry[] newTable = new Entry[newCapacity];
// 把小数组的元素转移到大数组中
transfer(newTable, initHashSeedAsNeeded(newCapacity));
// 引用新的大数组
table = newTable;
// 重新计算阈值
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
transfer 方法用来转移,将小数组的元素拷贝到新的数组中。
void transfer(Entry[] newTable, boolean rehash) {
// 新的容量
int newCapacity = newTable.length;
// 遍历小数组
for (Entry<K,V> e : table) {
while(null != e) {
// 拉链法,相同 key 上的不同值
Entry<K,V> next = e.next;
// 是否需要重新计算 hash
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
// 根据大数组的容量,和键的 hash 计算元素在数组中的下标
int i = indexFor(e.hash, newCapacity);
// 同一位置上的新元素被放在链表的头部
e.next = newTable[i];
// 放在新的数组上
newTable[i] = e;
// 链表上的下一个元素
e = next;
}
}
}
注意 e.next = newTable[i] 和 newTable[i] = e 这两行代码,就会将同一位置上的新元素被放在链表的头部。
扩容前的样子假如是下面这样子。
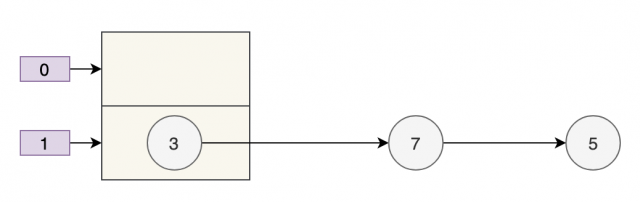
那么正常扩容后就是下面这样子。
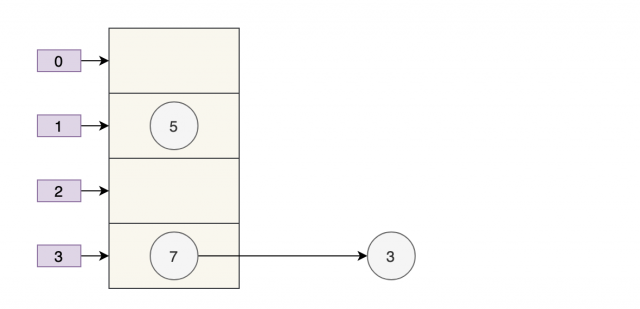
假设现在有两个线程同时进行扩容,线程 A 在执行到 newTable[i] = e; 被挂起,此时线程 A 中:e=3、next=7、e.next=null
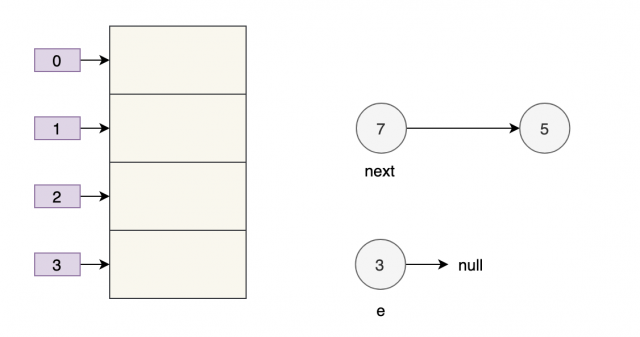
线程 B 开始执行,并且完成了数据转移。
此时,7 的 next 为 3,3 的 next 为 null。
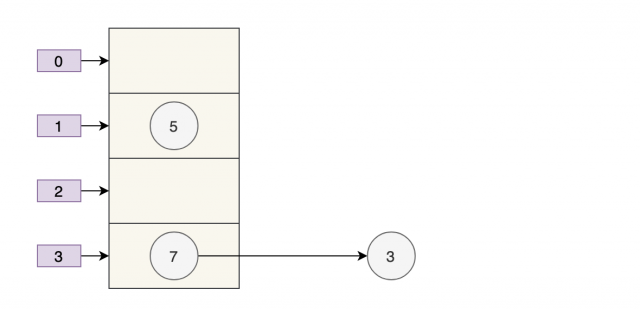
随后线程A获得CPU时间片继续执行 newTable[i] = e,将3放入新数组对应的位置,执行完此轮循环后线程A的情况如下:
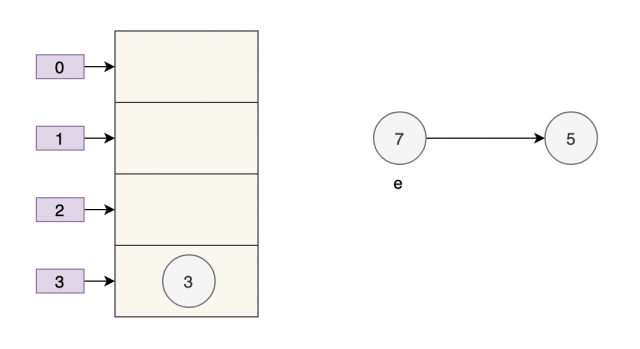
执行下一轮循环,此时 e=7,原本线程 A 中 7 的 next 为 5,但由于 table 是线程 A 和线程 B 共享的,而线程 B 顺利执行完后,7 的 next 变成了 3,那么此时线程 A 中,7 的 next 也为 3 了。
采用头部插入的方式,变成了下面这样子:
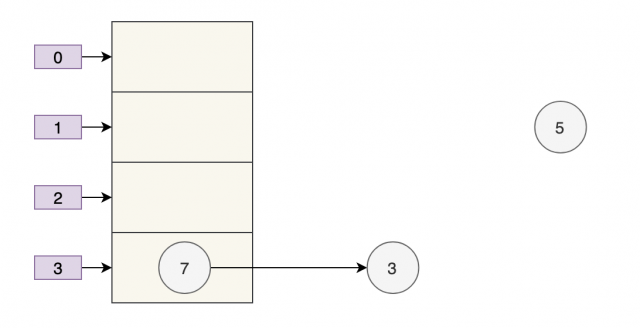
好像也没什么问题,此时 next = 3,e = 3。
进行下一轮循环,但此时,由于线程 B 将 3 的 next 变为了 null,所以此轮循环应该是最后一轮了。
接下来当执行完 e.next=newTable[i] 即 3.next=7 后,3 和 7 之间就相互链接了,执行完 newTable[i]=e 后,3 被头插法重新插入到链表中,执行结果如下图所示:
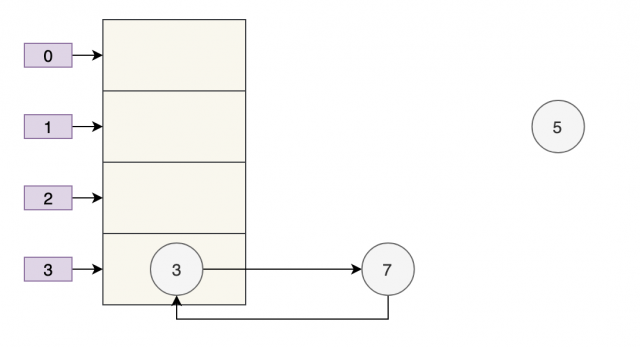
套娃开始,元素 5 也就成了弃婴,惨~~~
不过,JDK 8 时已经修复了这个问题,扩容时会保持链表原来的顺序,参照HashMap 扩容机制的这一篇。
02、多线程下 put 会导致元素丢失
正常情况下,当发生哈希冲突时,HashMap 是这样的:

但多线程同时执行 put 操作时,如果计算出来的索引位置是相同的,那会造成前一个 key 被后一个 key 覆盖,从而导致元素的丢失。
put 的源码:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 步骤①:tab为空则创建
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 步骤②:计算index,并对null做处理
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
// 步骤③:节点key存在,直接覆盖value
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 步骤④:判断该链为红黑树
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// 步骤⑤:该链为链表
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
//链表长度大于8转换为红黑树进行处理
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
// key已经存在直接覆盖value
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// 步骤⑥、直接覆盖
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
// 步骤⑦:超过最大容量 就扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
问题发生在步骤 ② 这里:
if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null);
两个线程都执行了 if 语句,假设线程 A 先执行了 tab[i] = newNode(hash, key, value, null),那 table 是这样的:
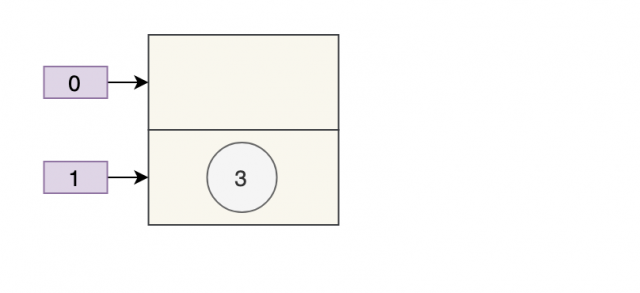
接着,线程 B 执行了 tab[i] = newNode(hash, key, value, null),那 table 是这样的:
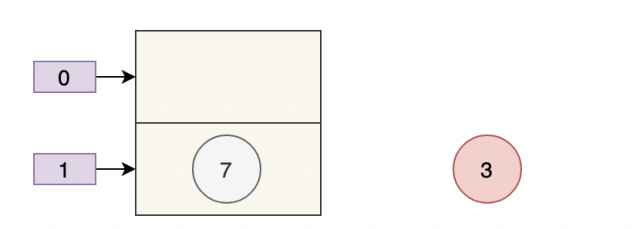
3 被干掉了。
03、put 和 get 并发时会导致 get 到 null
线程 A 执行put时,因为元素个数超出阈值而出现扩容,线程B 此时执行get,有可能导致这个问题。
注意来看 resize 源码:
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
// 超过最大值就不再扩充了,就只好随你碰撞去吧
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
// 没超过最大值,就扩充为原来的2倍
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
// 计算新的resize上限
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
}
线程 A 执行完 table = newTab 之后,线程 B 中的 table 此时也发生了变化,此时去 get 的时候当然会 get 到 null 了,因为元素还没有转移。
这是《Java 程序员进阶之路》专栏的第 58 篇,我们来聊了聊为什么 HashMap 是线程不安全的。
为了便于大家更系统化地学习 Java,二哥已经将《Java 程序员进阶之路》专栏开源到 GitHub 上了,大家只需轻轻地 star 一下,就可以和所有的小伙伴一起打怪升级了。
GitHub 地址:https://github.com/itwanger/toBeBetterJavaer
到此这篇关于Java京东面试题之为什么HashMap线程不安全的文章就介绍到这了,更多相关Java HashMap线程内容请搜索服务器之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持服务器之家!
原文链接:https://blog.csdn.net/qing_gee/article/details/120559630
本文链接:https://my.lmcjl.com/post/14156.html
4 评论