我就废话不多说了,大家还是直接看代码吧!
?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 |
|
输入两张图片,标记1为相似,0为不相似。
损失函数用的是简单的均方误差,有待改成Siamese的对比损失。
总结:
1.随机生成了几组1000对的图片,测试精度0.7左右,效果一般。
2.问题 1)数据加载没有用生成器,还得继续认真看看文档 2)训练时划分验证集的时候,训练就会报错,什么输入维度的问题,暂时没找到原因 3)输入的shape好像必须给出数字,本想用shape= input_tensor.get_shape(),能训练,不能保存模型,会报(NOT JSON Serializable,Dimension(None))类型错误
补充知识: keras 问答匹配孪生网络文本匹配 RNN 带有数据
用途:
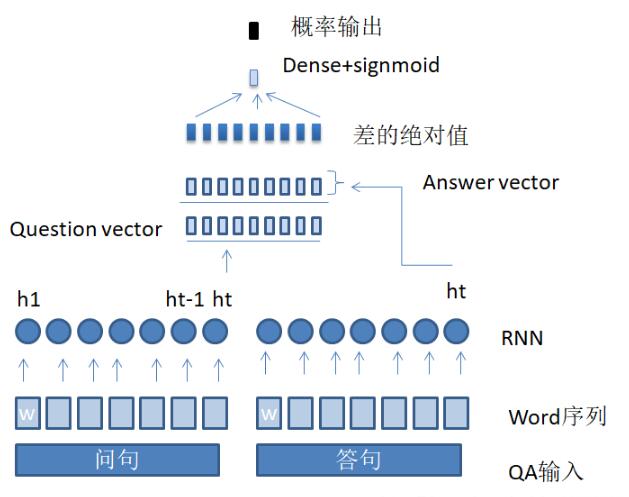
这篇博客解释了如何搭建一个简单的匹配网络。并且使用了keras的lambda层。在建立网络之前需要对数据进行预处理。处理过后,文本转变为id字符序列。将一对question,answer分别编码可以得到两个向量,在匹配层中比较两个向量,计算相似度。
网络图示:
数据准备:
数据基于网上的淘宝客服对话数据,我也会放在我的下载页面中。原数据是对话,我筛选了其中label为1的对话。然后将对话拆解成QA对,q是用户,a是客服。然后对于每个q,有一个a是匹配的,label为1.再选择一个a,构成新的样本,label为0.
超参数:
比较简单,具体看代码就可以了。
?
|
1 2 3 4 5 6 7 8 9 10 11 |
|
细节:
导入一些库
?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
|
数据准备,先统计词频,然后取出top N个常用词,然后将句子转换成 单词id的序列。把句子中的有效id靠右边放,将句子左边补齐padding。然后分成训练集和测试集
?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 |
|
最后建立网络。先定义两个函数,一个是句子编码器,另一个是lambda层,计算两个向量的绝对差。将QA分别用encoder处理得到两个向量,把两个向量放入lambda层。最后有了2*hidden size的一层,将这一层接一个dense层,接activation,得到分类概率。
?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 |
|
最后是处理数据的函数,写在另一个文件里。
?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
|
以上这篇keras实现基于孪生网络的图片相似度计算方式就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持服务器之家。
原文链接:https://blog.csdn.net/u013491950/article/details/83997234
本文链接:https://my.lmcjl.com/post/16887.html
4 评论