一、lua语句的执行过程
lua代码首先会被lua编译器(通常所指的luac)编译为二进制文件,编译是以一个lua文件为单位,比如一个lua文件内有语法错误,即使你不执行相关代码,这个文件也是编译不过去的;编译完成后,然后二进制文件被lua虚拟机加载执行。
但实际上我们并不能看到编译器的这个过程,这是因为lua解释器是隐式调用编译器和lvm的,也就是lua的编译和执行是被封装起来的,对外部是完全透明的;具体过程如下图所示:

预编译
提前将lua文件编译为二进制文件,也就是二进制chunk。
预编译的主要优点:更快的加载速度,保护源代码;
编译成二进制chunk只能提高lua虚拟机的加载速度,执行速度还是不变的。
二、luac相关
1.luac基础命令
使用luac可以编译生成一个二进制文件,如luac main.lua,这里没有指定输出文件,它就会默认输出文件名luac.out;
luac主要有两个用途:
- 作为编译器,将Lua源文件编译成二进制chunk文件;
- 作为反编译器,分析二进制chunk,将分析结果输出到控制台;
luac相关命令
luac -l [filename],生成已编译字节码的列表,如果没有给出文件名,则默认加载luac.out并列出字节码;使用luac -l -l [filename]可以得到更详细的信息;
luac -o filename,指定输出文件名,如果只是luac,那么会默认生成luac.out;
luac -p,加载文件但不生成任何输出文件。主要用于语法检查和测试预编译块,只起到一个编译检查的作用。
luac -s,在写入文件之前剥离调试信息;
luac -v,显示版本信息;
2.简单示例
如下所示,新建一个lua文件,输入一条语句print('hello world'),然后进行编译和反编译,反编译结果如下:

编译器在对一个lua源文件进行编译时,会自动为脚本添加一个main函数,并且把整个程序都放进这个函数里,然后再以它为起点进行编译。这个函数不仅是编译的起点,也是未来Lua虚拟机解释执行程序时的入口,我们写的上述print语句就会变成下面的样子:
function main(...)print('hello world')return
end反编译打印出的函数信息分为两个部分:前面两行是函数基础信息,后面是指令列表;
函数基础信息
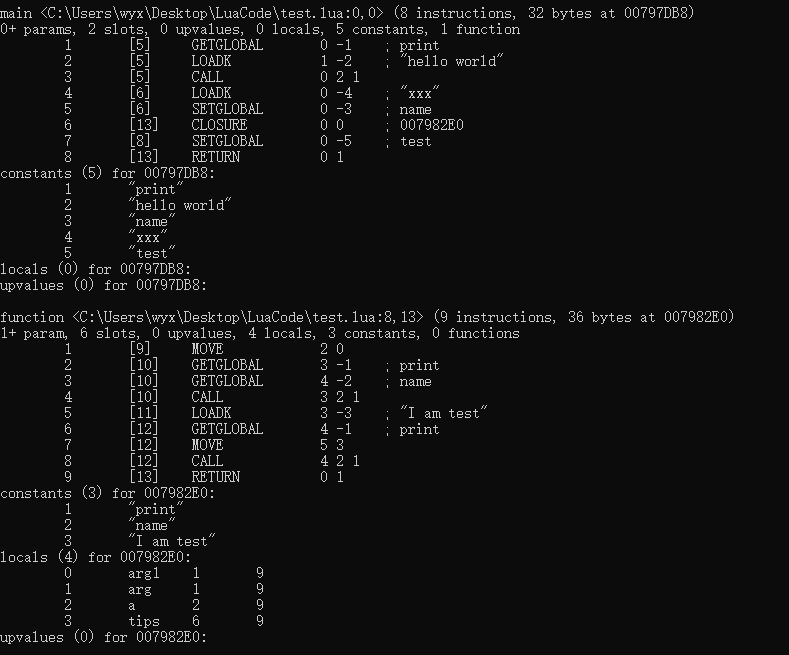
如下是一个测试源代码和反编译结果,用于解读函数基础信息;
print('hello world')
name = 'xxx'function test(arg1, ...)local a = arg1print(name)local tips = 'I am test'print(tips)
end
第一行如果是main,说明是编译器为我们添加的主函数,如果是function,则说明是一个普通函数;跟在后面的是源文件名(文件路径)和函数在文件里的起止行号,对于主函数,起止都是0,对于自定义函数,就是文件内的行号(不过由于我的源文件里前面有几行注释,所以这里的起止和上面的源码没有对应上,但和我本地的行号是对应的);最后就是指令数量和函数的地址;
第二行依次给出函数的固定参数数量(有+号代表是一个vararg函数)、运行函数所必要的寄存器数量、upvalue数量、局部变量数量、常量数量、子函数数量;
可以使用luac -l -l打印详细信息:
三、二进制chunk格式
Lua中的二进制chunk格式也只是一个字节流,该格式属于Lua虚拟机内部实现细节;
chunk格式没有考虑跨平台需求,编译脚本时,直接按照本机的大小端方式生成二进制文件,当加载二进制chunk文件时,会探测被加载文件的大小端方式,如果和本机不匹配,就拒绝加载。
二进制chunk格式的设计也没有考虑不同Lua版本之间的兼容问题,编译时直接按照当时的Lua版本生成二进制chunk文件,当加载二进制chunk文件时,会检测被加载文件的版本号,如果和当前Lua版本不匹配,则拒绝加载。
二进制chunk格式没有被刻意得设计很紧凑,编译成二进制chunk之后,甚至会比文本形式的源文件还要大,但把Lua脚本预编译成二进制chunk的主要目的是为了获得更快的加载速度,所以这并没有什么影响。
本文链接:https://my.lmcjl.com/post/1817.html
4 评论