
前言
Large Language Models (LLMs)在2020年OpenAI 的 GPT-3 的发布而进入世界舞台 。从那时起,他们稳步增长进入公众视野。
众所周知 OpenAI 的 API 无法联网,所以大家如果想通过它的API实现联网搜索并给出回答、总结 PDF 文档、基于某个 Youtube 视频进行问答等等的功能肯定是无法实现的。所以,我们来介绍一个非常强大的第三方开源库:LangChain 。
LangChain 是一个用于开发由语言模型驱动的应用程序的框架。他主要拥有 2 个能力:可以将 LLM 模型与外部数据源进行连接&允许与 LLM 模型进行交互。
项目地址:https://github.com/langchain-ai/langchain

LangChain 是一个开发由语言模型驱动的应用程序的框架。
框架是设计原则:
数据感知 : 将语言模型连接到其他数据源
具有代理性质 : 允许语言模型与其环境交互
Langchain的核心思想
将不同的组件“链接”在一起,以围绕LLM创建更高级的用例。
LangChain 核心模块支持
模型(models) : LangChain 支持的各种模型类型和模型集成。
提示(prompts) : 包括提示管理、提示优化和提示序列化。
内存(memory) : 内存是在链/代理调用之间保持状态的概念。LangChain 提供了一个标准的内存接口、一组内存实现及使用内存的链/代理示例。
索引(indexes) : 与您自己的文本数据结合使用时,语言模型往往更加强大——此模块涵盖了执行此操作的最佳实践。
链(chains) : 链不仅仅是单个 LLM 调用,还包括一系列调用(无论是调用 LLM 还是不同的实用工具)。LangChain 提供了一种标准的链接口、许多与其他工具的集成。LangChain 提供了用于常见应用程序的端到端的链调用。
代理(agents) : 代理涉及 LLM 做出行动决策、执行该行动、查看一个观察结果,并重复该过程直到完成。LangChain 提供了一个标准的代理接口,一系列可供选择的代理,以及端到端代理的示例。
###LangChain工作原理
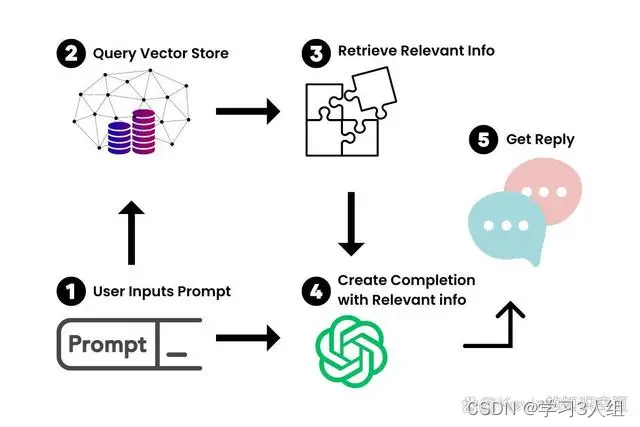
LangChain就是把大量的数据组合起来,让LLM能够尽可能少地消耗计算力就能轻松地引用。它的工作原理是把一个大的数据源,比如一个50页的PDF文件,分成一块一块的,然后把它们嵌入到一个向量存储(Vector Store)里。

创建向量存储的简单示意图
现在我们有了大文档的向量化表示,我们就可以用它和LLM一起工作,只检索我们需要引用的信息,来创建一个提示-完成(prompt-completion)对。
当我们把一个提示输入到我们新的聊天机器人里,LangChain就会在向量存储里查询相关的信息。你可以把它想象成一个专门为你的文档服务的小型谷歌。一旦找到了相关的信息,我们就用它和提示一起喂给LLM,生成我们的答案。

使用场景用例

自治代理(autonomous agents)
长时间运行的代理会采取多步操作以尝试完成目标。 AutoGPT 和 BabyAGI就是典型代表。
代理模拟(agent simulations)
将代理置于封闭环境中观察它们如何相互作用,如何对事件作出反应,是观察它们长期记忆能力的有趣方法。
个人助理(personal assistants)
主要的 LangChain 使用用例。个人助理需要采取行动、记住交互并具有您的有关数据的知识。
问答(question answering)
第二个重大的 LangChain 使用用例。仅利用这些文档中的信息来构建答案,回答特定文档中的问题。
聊天机器人(chatbots)
由于语言模型擅长生成文本,因此它们非常适合创建聊天机器人。
查询表格数据(tabular)
如果您想了解如何使用 LLM 查询存储在表格格式中的数据(csv、SQL、数据框等),请阅读此页面。
代码理解(code) : 如果您想了解如何使用 LLM 查询来自 GitHub 的源代码,请阅读此页面。
与 API 交互(apis)
使LLM 能够与 API 交互非常强大,以便为它们提供更实时的信息并允许它们采取行动。
提取(extraction)
从文本中提取结构化信息。
摘要(summarization)
将较长的文档汇总为更短、更简洁的信息块。一种数据增强生成的类型。
评估(evaluation)
生成模型是极难用传统度量方法评估的。 一种新的评估方式是使用语言模型本身进行评估。 LangChain 提供一些用于辅助评估的提示/链。
Langchian生态

实战举例
模型(LLM包装器)
提示
链
嵌入和向量存储
代理
我会给你分别来介绍每个部分,让你能够对LangChain的工作原理有一个高层次的理解。接下来,你应该能够运用这些概念,开始设计你自己的用例和创建你自己的应用程序。
接下来我会用Rabbitmetrics(Github)的一些简短的代码片段来进行介绍。他提供了有关此主题的精彩教程。这些代码片段应该能让你准备好使用LangChain。
首先,让我们设置我们的环境。你可以用pip安装3个你需要的库:
pip install -r requirements.txt
python-dotenv==1.0.0 langchain==0.0.137 pinecone-client==2.2.1
Pinecone是我们将要和LangChain一起使用的向量存储(Vector Store)。在这里,你要把你的OpenAI、Pinecone环境和Pinecone API的API密钥存储到你的环境配置文件里。你可以在它们各自的网站上找到这些信息。然后我们就用下面的代码来加载那个环境文件:
现在,我们准备好开始了!
# 加载环境变量
from dotenv import loaddotenv,finddotenv loaddotenv(finddotenv())
3.1、模型(LLM包装器)
为了和我们的LLM交互,我们要实例化一个OpenAI的GPT模型的包装器。在这里,我们要用OpenAI的GPT-3.5-turbo,因为它是最划算的。但是如果你有权限,你可以随意使用更强大的GPT4。
要导入这些,我们可以用下面的代码:
# 为了查询聊天模型GPT-3.5-turbo或GPT-4,导入聊天消息和ChatOpenAI的模式(schema)。
from langchain.schema import ( AIMessage, HumanMessage, SystemMessage)
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI(model_name="gpt-3.5-turbo",temperature=0.3)
messages = [ SystemMessage(content="你是一个专业的数据科学家"), HumanMessage(content="写一个Python脚本,用模拟数据训练一个神经网络")]
response=chat(messages)print(response.content,end='\n')
实际上,SystemMessage为GPT-3.5-turbo模块提供了每个提示-完成对的上下文信息。HumanMessage是指您在ChatGPT界面中输入的内容,也就是您的提示。
但是对于一个自定义知识的聊天机器人,我们通常会将提示中重复的部分抽象出来。例如,如果我要创建一个推特生成器应用程序,我不想一直输入“给我写一条关于…的推特”。
因此,让我们来看看如何使用提示模板(PromptTemplates)来将这些内容抽象出来。
3.2、提示
LangChain提供了PromptTemplates,允许你可以根据用户输入动态地更改提示,类似于正则表达式(regex)的用法。
# 导入提示并定义
PromptTemplatefrom langchain
import PromptTemplatetemplate = """您是一位专业的数据科学家,擅长构建深度学习模型。用几行话解释{concept}的概念"""
prompt = PromptTemplate( input_variables=["concept"], template=template,)
# 用PromptTemplate运行LLM
llm(prompt.format(concept="autoencoder"))
llm(prompt.format(concept="regularization"))
你可以用不同的方式来改变这些提示模板,让它们适合你的应用场景。如果你熟练使用ChatGPT,这应该对你来说很简单。
3.3、链
链可以让你在简单的提示模板上面构建功能。本质上,链就像复合函数,让你可以把你的提示模板和LLM结合起来。
使用之前的包装器和提示模板,我们可以用一个单一的链来运行相同的提示,它接受一个提示模板,并把它和一个LLM组合起来:
# 导入LLMChain并定义一个链,用语言模型和提示作为参数。
from langchain.chains import LLMChain
chain = LLMChain(llm=llm, prompt=prompt)
# 只指定输入变量来运行链。
print(chain.run("autoencoder"))
除此之外,顾名思义,我们还可以把这些链连起来,创建更大的组合。
比如,我可以把一个链的结果传递给另一个链。在这个代码片段里,Rabbitmetrics把第一个链的完成结果传递给第二个链,让它用500字向一个五岁的孩子解释。
你可以把这些链组合成一个更大的链,然后运行它。
# 定义一个第二个提示
second_prompt = PromptTemplate( input_variables=["ml_concept"], template="把{ml_concept}的概念描述转换成用500字向我解释,就像我是一个五岁的孩子一样",)
chain_two = LLMChain(llm=llm, prompt=second_prompt)
# 用上面的两个链定义一个顺序链:第二个链把第一个链的输出作为输入
from langchain.chains import SimpleSequentialChain
overall_chain = SimpleSequentialChain(chains=[chain, chain_two], verbose=True)
# 只指定第一个链的输入变量来运行链。
explanation = overall_chain.run("autoencoder")print(explanation)
有了链,你可以创建很多功能,这就是LangChain功能强大的原因。但是它真正发挥作用的地方是和前面提到的向量存储一起使用。接下来我们开始介绍一下这个部分。
3.4、嵌入和向量存储
这里我们将结合LangChain进行自定义数据存储。如前所述,嵌入和向量存储的思想是把大数据分成小块,并存储起来。
LangChain有一个文本分割函数来做这个:
# 导入分割文本的工具,并把上面给出的解释分成文档块
from langchain.text_splitter import RecursiveCharacter
TextSplittertext_splitter = RecursiveCharacterTextSplitter( chunk_size = 100, chunk_overlap = 0,)
texts = text_splitter.create_documents([explanation])
分割文本需要两个参数:每个块有多大(chunksize)和每个块有多少重叠(chunkoverlap)。让每个块之间有重叠是很重要的,可以帮助识别相关的相邻块。
每个块都可以这样获取:
texts[0].page_content
在我们有了这些块之后,我们需要把它们变成嵌入。这样向量存储就能在查询时找到并返回每个块。我们将使用OpenAI的嵌入模型来做这个。
# 导入并实例化 OpenAI embeddingsfrom langchain.embeddings import OpenAIEmbeddingsembeddings = OpenAIEmbeddings(model_name="ada") # 用嵌入把第一个文本块变成一个向量query_result = embeddings.embed_query(texts[0].page_content)print(query_result)
最后,我们需要有一个地方来存储这些向量化的嵌入。如前所述,我们将使用Pinecone来做这个。使用之前环境文件里的API密钥,我们可以初始化Pinecone来存储我们的嵌入。
# 导入并初始化Pinecone客户端
import osimport pineconefrom langchain.vectorstores
import Pineconepinecone.init( api_key=os.getenv('PINECONE_API_KEY'), environment=os.getenv('PINECONE_ENV') )
# 上传向量到
Pineconeindex_name = "langchain-quickstart"
search = Pinecone.from_documents(texts, embeddings, index_name=index_name) # 做一个简单的向量相似度搜索query = "What is magical about an autoencoder?"result = search.similarity_search(query)print(result)
现在我们能够从我们的Pinecone向量存储里查询相关的信息了!剩下要做的就是把我们学到的东西结合起来,创建我们特定的用例,给我们一个专门的AI“代理”。
3.5、代理
一个智能代理就是一个能够自主行动的AI,它可以根据输入,依次完成一系列的任务,直到达成最终的目标。这就意味着我们的AI可以利用其他的API,来实现一些功能,比如发送邮件或做数学题。如果我们再加上我们的LLM+提示链,我们就可以打造出一个适合我们需求的AI应用程序。
这部分的原理可能有点复杂,所以让我们来看一个简单的例子,来演示如何用LangChain中的一个Python代理来解决一个简单的数学问题。这个代理是通过调用我们的LLM来执行Python代码,并用NumPy来求解方程的根:
# 导入Python REPL工具并实例化Python代理
from langchain.agents.agent_toolkits
import create_python_agent from langchain.tools.python.tool
import PythonREPLToolfrom langchain.python
import PythonREPLfrom langchain.llms.openai
import OpenAI
agent_executor = create_python_agent( llm=OpenAI(temperature=0, max_tokens=1000), tool=PythonREPLTool(), verbose=True)
# 执行Python代理
agent_executor.run("找到二次函数3 * x ** 2 + 2 * x - 1的根(零点)。")
一个定制知识的聊天机器人,其实就是一个能够把问题和动作串起来的智能代理。它会把问题发送给向量化存储,然后把得到的结果和原来的问题结合起来,给出答案!
其它参考
10个最流行的向量数据库【AI】
本文链接:https://my.lmcjl.com/post/18792.html
4 评论