机器翻译是一项重要的自然语言处理任务,而Transformer模型是一种广泛应用于机器翻译任务的强大模型。它在2017年被提出,通过引入自注意力机制(self-attention)来解决了传统循环神经网络在长距离依赖建模上的限制。在本文中,我们将学习如何使用Transformer模型进行机器翻译。
如何使用Transformer模型进行机器翻译?
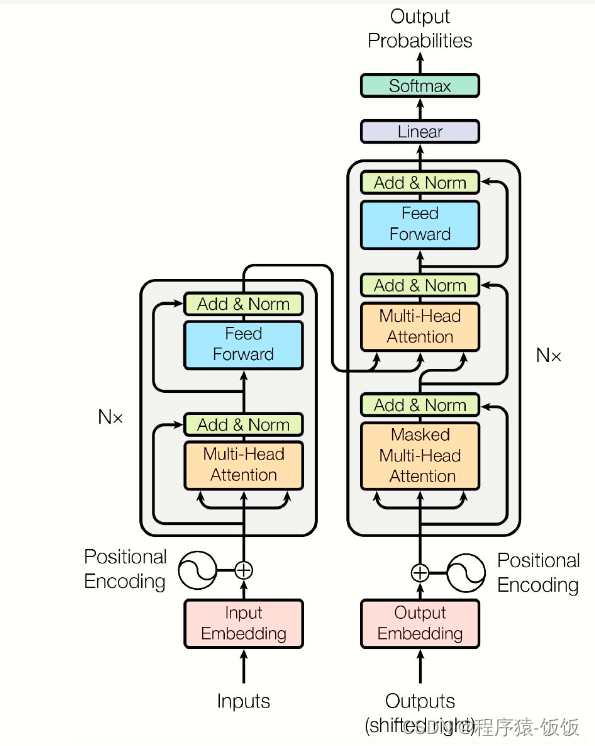

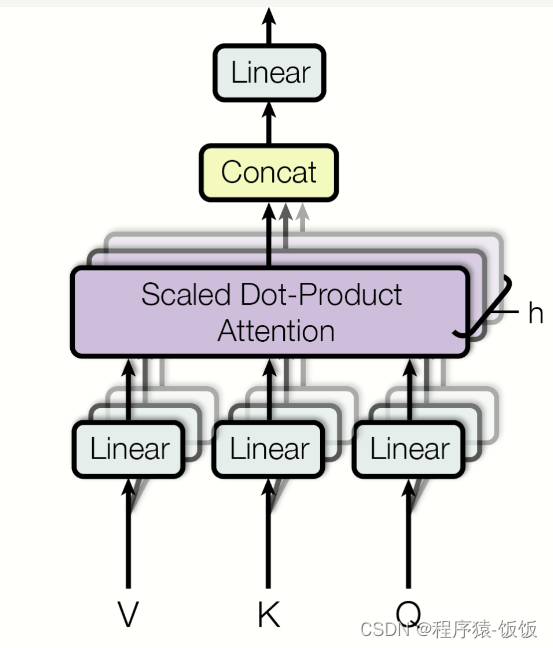
首先,我们需要安装相应的库和工具。在Python中,我们可以使用Hugging Face的transformers库来访问已经预训练好的Transformer模型,并使用torch库来构建和训练模型。您可以使用以下命令进行安装:
pip install transformers torch
安装完成后,我们可以使用以下代码来实现机器翻译:
import torch
from transformers import MarianMTModel, MarianTokenizer# 加载预训练的Transformer模型和分词器
model_name = 'Helsinki-NLP/opus-mt-en-zh'
tokenizer = MarianTokenizer.from_pretrained(model_name)
model = MarianMTModel.from_pretrained(model_name)# 定义要翻译的文本
text = 'Hello, how are you?'# 使用分词器对输入文本进行分词
inputs = tokenizer.encode(text, return_tensors='pt')# 使用模型进行翻译
outputs = model.generate(inputs, max_length=128, num_beams=4, early_stopping=True)# 解码输出文本
translated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)# 打印翻译结果
print(translated_text)
以上代码中,我们首先加载了预训练的Transformer模型和相应的分词器。这里我们选择了Helsinki-NLP团队提供的英语到中文的模型(Helsinki-NLP/opus-mt-en-zh)。您可以根据需要选择其他语言对或不同的模型。
接下来,我们定义了要翻译的文本,并使用分词器对其进行分词。tokenizer.encode()函数将文本编码为模型可以理解的输入格式,并返回PyTorch张量。然后,我们使用模型的generate()函数进行翻译。generate()函数会接收编码后的输入,并生成翻译结果。在这里,我们使用了一些参数来控制生成的过程,例如max_length表示生成的最大长度,num_beams表示束搜索的数量,early_stopping表示是否在遇到停止标记时停止生成。
最后,我们使用分词器的decode()函数对生成的输出进行解码,将其转换回文本格式。然后,我们可以打印翻译结果。
使用以上代码,您可以轻松地使用Transformer模型进行机器翻译。请注意,这里我们使用的是预训练的模型,您也可以根据自己的需求使用自定义数据集进行微调训练。
| 感谢大家对课程的喜欢,欢迎关注 |
公众号【AI技术星球】回复(123) |
| 白嫖配套资料+60G入门进阶AI资源包+技术问题答疑+完整版视频
|


总结: 在本文中,我们学习了如何使用Transformer模型进行机器翻译。通过加载预训练的模型和分词器,并使用相应的API进行编码、生成和解码,我们可以实现简单而强大的机器翻译功能。Transformer模型以其在序列建模任务中的卓越表现而闻名,它不仅在机器翻译中得到广泛应用,还在许多其他自然语言处理任务中发挥着重要作用。希望本文对您理解和应用Transformer模型进行机器翻译有所帮助。
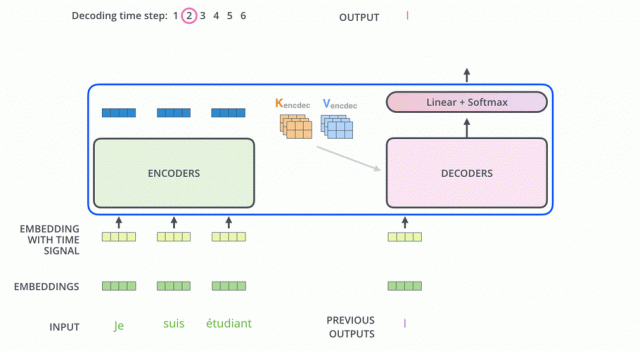
本文链接:https://my.lmcjl.com/post/19893.html
4 评论