目录
- 前言
-
一、插入排序
- 时间复杂度
- 空间复杂度
- 代码实现(升序)
-
二、希尔排序
- 时间复杂度
- 空间复杂度
- 代码实现
-
三、选择排序
- 时间复杂度
- 空间复杂度
- 代码实现
-
四、堆排序
- 时间复杂度
- 空间复杂度
- 代码实现
-
五、冒泡排序
- 时间复杂度
- 空间复杂度
- 代码实现
-
六、快排排序
- 时间复杂度
- 空间复杂度
- 代码实现
-
七、归并排序
- 时间复杂度
- 空间复杂度
- 代码实现
-
八、计数排序
- 时间复杂度
- 空间复杂度
-
九、各种排序总结比较
前言
排序是数据结构中很重要的一章,先介绍几个基本概念。
- 排序稳定性:多个具有相同的关键字的记录,若经过排序,这些记录的相对次
- 序保持不变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,则称这种排序算法是稳定的;否则称为不稳定的。
- 内部排序:数据元素全部放在内存中的排序。
- 外部排序:数据元素太多不能同时放在内存中,根据排序过程的要求不能在内外存之间移动数据的排序。
一、插入排序
时间复杂度
最坏:-----------o(n^2)
最好:-----------o(n)
平均:-----------o(n^2)
空间复杂度
o(1)
稳定性:稳定
-『 插入排序 』:顾名思义就是把每一个数插入到有序数组中对应的位置。
就相当于你玩扑克牌的过程,抓来一张牌,就放在对应有序位置
直接插入排序:
当插入第i(i>=1)个元素时,前面的array[0],array[1],…,array[i-1]已经排好序,此时用array[i]的排序码与array[i-1],array[i-2],…的排序码顺序进行比较,找到插入位置即将array[i]插入,原来位置上的元素顺序后移

代码实现(升序)
?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
|
那么我们可以看到,越是接近有序的数组,插入排序的效率越高(有序时对于任何一个数只需要和前边的数比较一次)。
二、希尔排序
时间复杂度
o(n^(1.3—2))
空间复杂度
o(1)
稳定性:稳定
『 希尔排序 』(shell's sort)是插入排序的一种又称“缩小增量排序”(diminishing increment sort),是直接插入排序算法的一种更高效的改进版本。希尔排序是非稳定排序算法。该方法因 d.l.shell 于 1959 年提出而得名。
该方法实质上是一种『 分组插入 』方法,因为插入排序对于接近有序的数组排序效率非常高,那么希尔提出:
算法先将要排序的一组数按某个增量d分成若干组,每组中记录的下标相差d.对每组中全部元素进行排序,然后再用一个较小的增量对它进行分组,在每组中再进行排序。当增量减到1时,整个要排序的数被分成一组,排序完成。
一般的初次取序列的一半为增量,以后每次减半,直到增量为1。
并且插入排序可以看成分组是1的希尔排序。动图如下:

因为插入排序可以看做gap==1的希尔排序,因此只需要改变插入排序中for循环的增量控制排序即可。
代码实现
?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
|
关于希尔排序时间复杂度证明比较复杂,取决于gap怎么取,如果按照knuth提出的/3,来取是o(n^(1.25)- 1.6*o(n^1.25).
希尔排序的特性总结:
- 希尔排序是对直接插入排序的优化。
- 当gap > 1时都是预排序,目的是让数组更接近于有序。当gap == 1时,数组已经接近有序的了,这样就会很快。这样整体而言,可以达到优化的效果。我们实现后可以进行性能测试的对比。
- 希尔排序的时间复杂度不好计算,因为gap的取值方法很多,导致很难去计算,因此在好些树中给出的希尔排序的时间复杂度都不固定
三、选择排序
时间复杂度
最坏:-----------o(n^2)
最好:-----------o(n^2)
平均:-----------o(n^2)
空间复杂度
o(1)
稳定性:不稳定
『 基本思想 』:
每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始(末尾)位置,直到全部待排序的数据元素排完 。如图:

代码实现
?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
直接选择排序思考非常好理解,但是效率不是很好。实际中很少使用。
四、堆排序
时间复杂度
最坏:-----------o(n * logn)
最坏:-----------o(n * logn)
平均:-----------o(n*logn)
空间复杂度
o(1)
堆排序(heapsort)是指利用堆积树(堆)这种数据结构所设计的一种排序算法,它是选择排序的一种。它是通过堆来进行选择数据。需要注意的是排升序要建大堆,排降序建小堆。
具体可见另一篇文章堆排序和topk问题
动图:
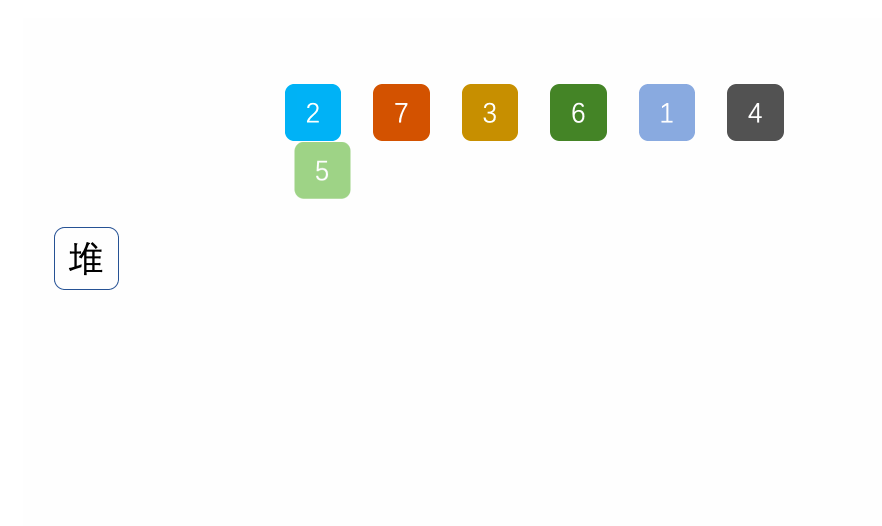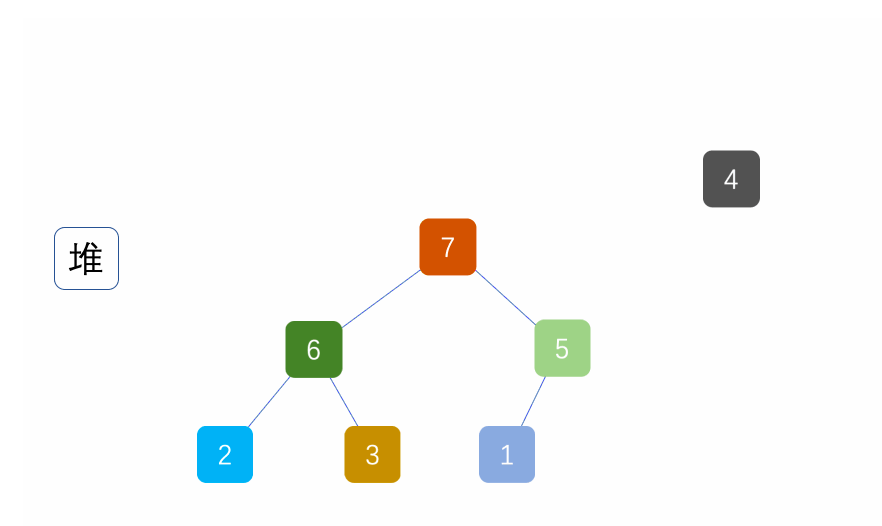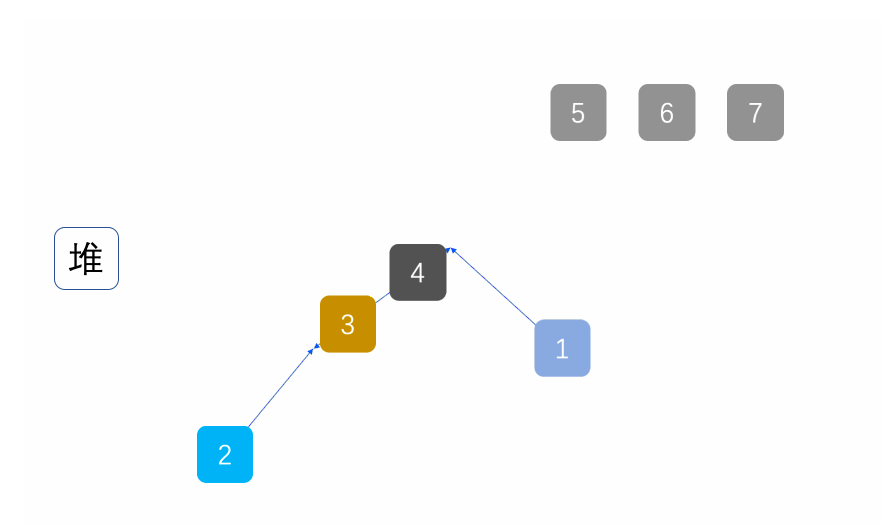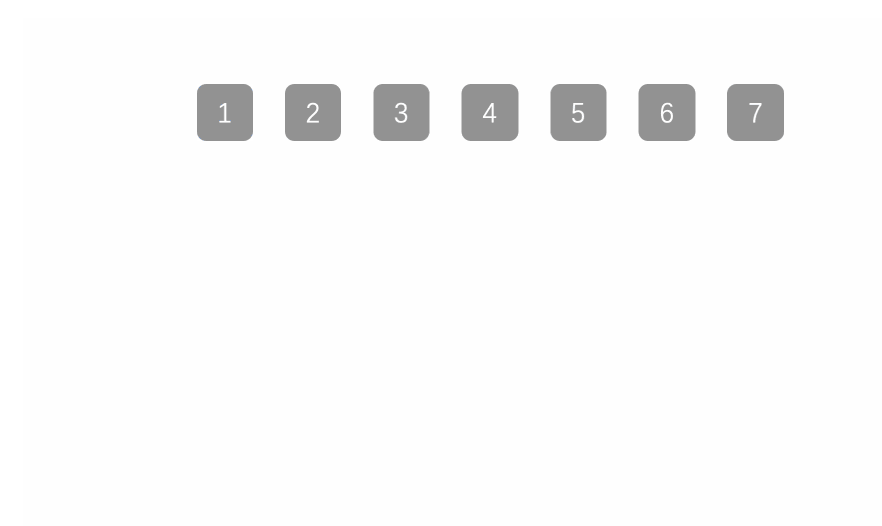
代码实现
?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
|
五、冒泡排序
时间复杂度
最坏:-----------o(n^2)
最好:-----------o(n)
平均:-----------o(n^2)
空间复杂度
o(1)
『 冒泡排序 』是大家最熟悉的也是最容易理解的排序,如下图:
『 冒泡排序基本思想 』就是每一次将相邻的数据进行『 两两比较 』,选出最大的依次比较送到右边,那么最右边就是最大值,而左边留下的自然就是小的(排升序)
-『 冒泡排序 』需要两层循环
『 内层循环 』表示一次冒泡,也就是两两比较先选出最大的放到最右边,同时注意每一次冒泡选出最大元素,那么两两比较次数-1(下一次不用比较选好的最右边)
『 外层循环 』控制的是冒泡的次数(假设数组n 个元素)也就是n-1次冒泡选出n-1个最大的元素
代码实现
初版代码如下:
?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
|
时间复杂度分析:每一次比较次数是n-1,n-2,n-3***1.因此是n(n-1)/2
但是这种写法还是有缺陷,时间复杂度永远是o(n^2) , 对于一个已经排好序的数组来说,还是需要n^2的复杂度,但对于有序的数组,每一次冒泡都不会进行交换因为有序,因此如果只要任何一次冒泡中没有数据交换就证明数组有序了。时间复杂度最好也可以达到0(n)。
代码优化如下:
?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
六、快排排序
时间复杂度
最坏:-----------o(n^2)
最好:-----------o(logn)
平均:-----------o(logn)
空间复杂度
o(logn)
『 快速排序 』是hoare于1962年提出的一种二叉树结构的交换排序方法,其『 基本思想 』为:任取待排序元素序列中的某元素作为『 基准值 』,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。如图:

代码实现
递归写法:
?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
|
递归框架写完了接下来就差partion函数的实现也就是快排的灵魂,去每一次找基准值。那么一共有三种写法如下:
hoare版本
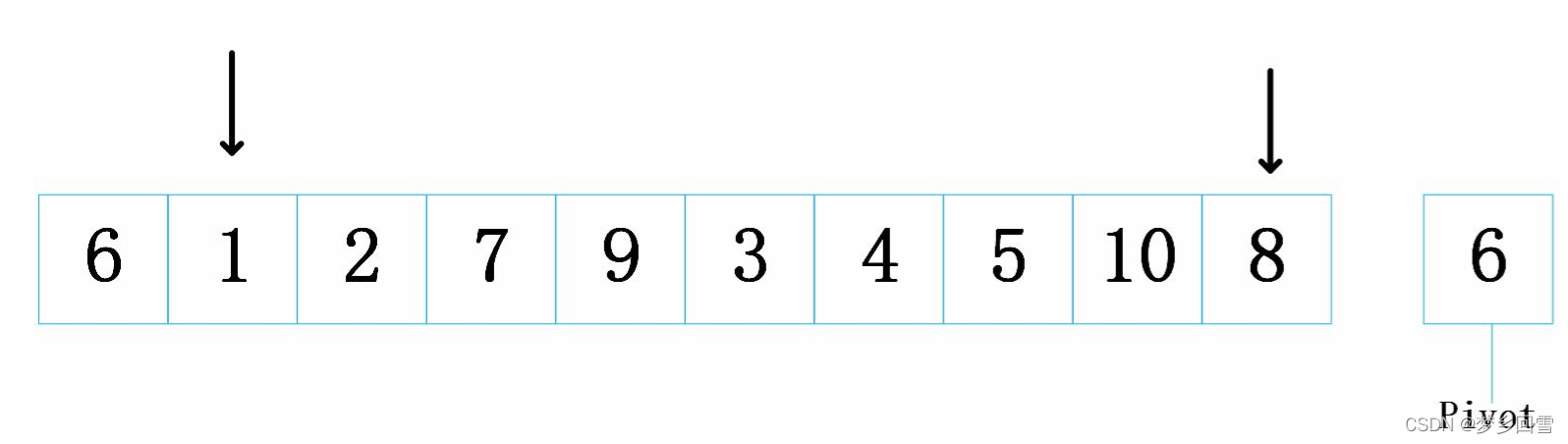
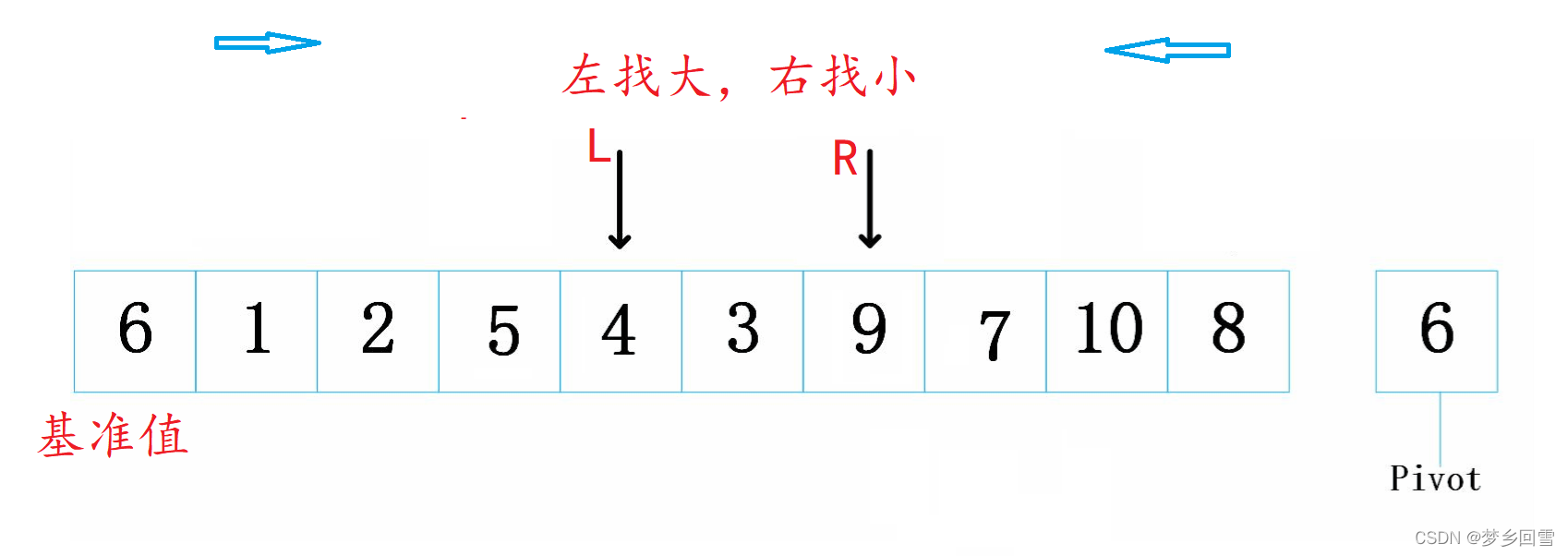
1.首先就是要找基准值,这里你可以选最左边或最右边的值(图中是6)
2.两个指针指向头(这里选左为基准值,头指针指向第二个)和尾,基准值选左,则右指针先走,反之左指针先走。
3.左指针找到比基准值大的停下,右指针找比基准值小的停下,交换左右指针指向值
4.重复2.3动作,直到左右指针相遇,交换左指针值和基准值

左值为基准,右指针先走找比6小的:
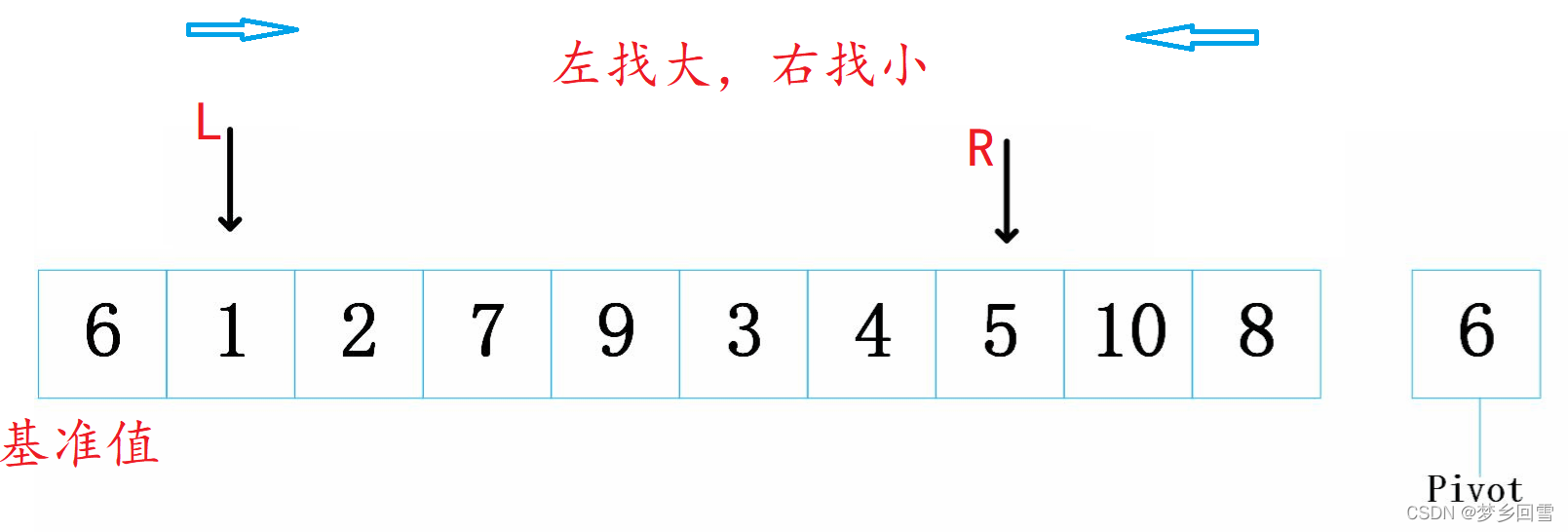
左值为基准,右指针先走找比6小的:
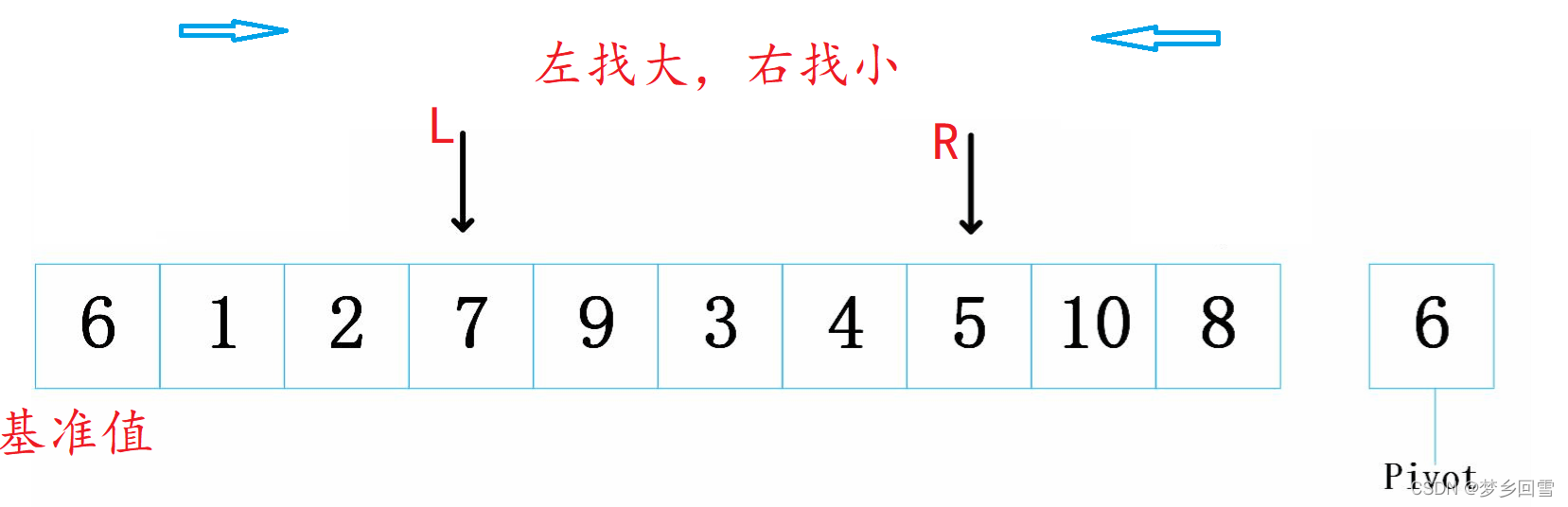
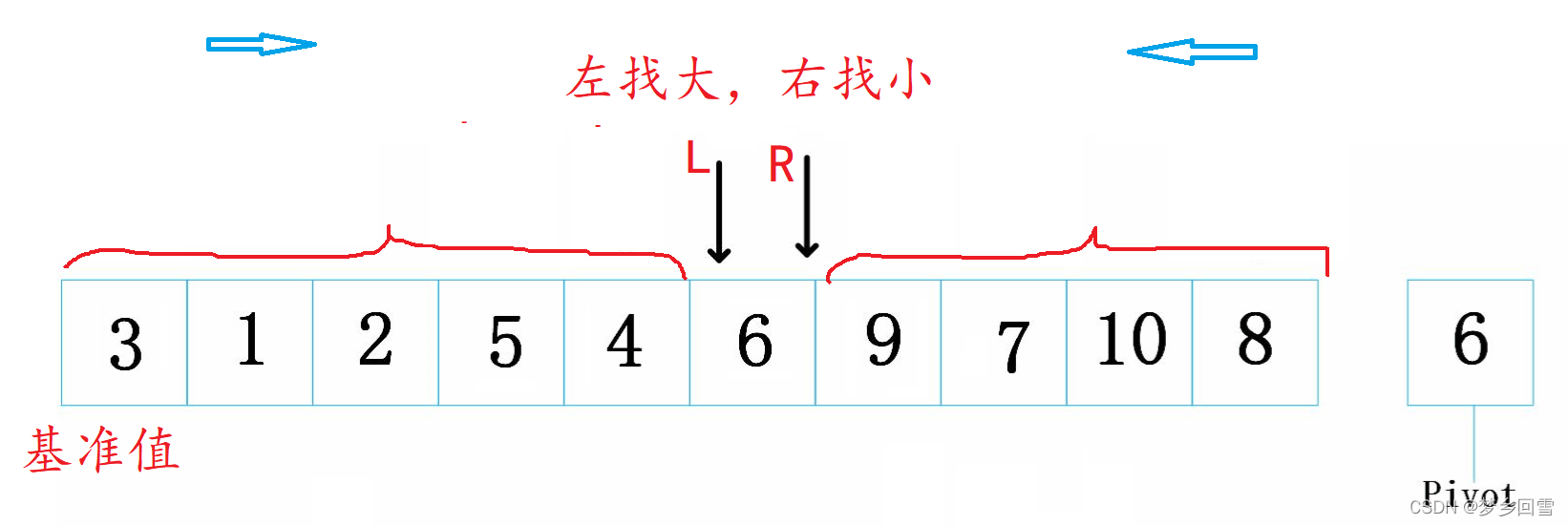
交换:
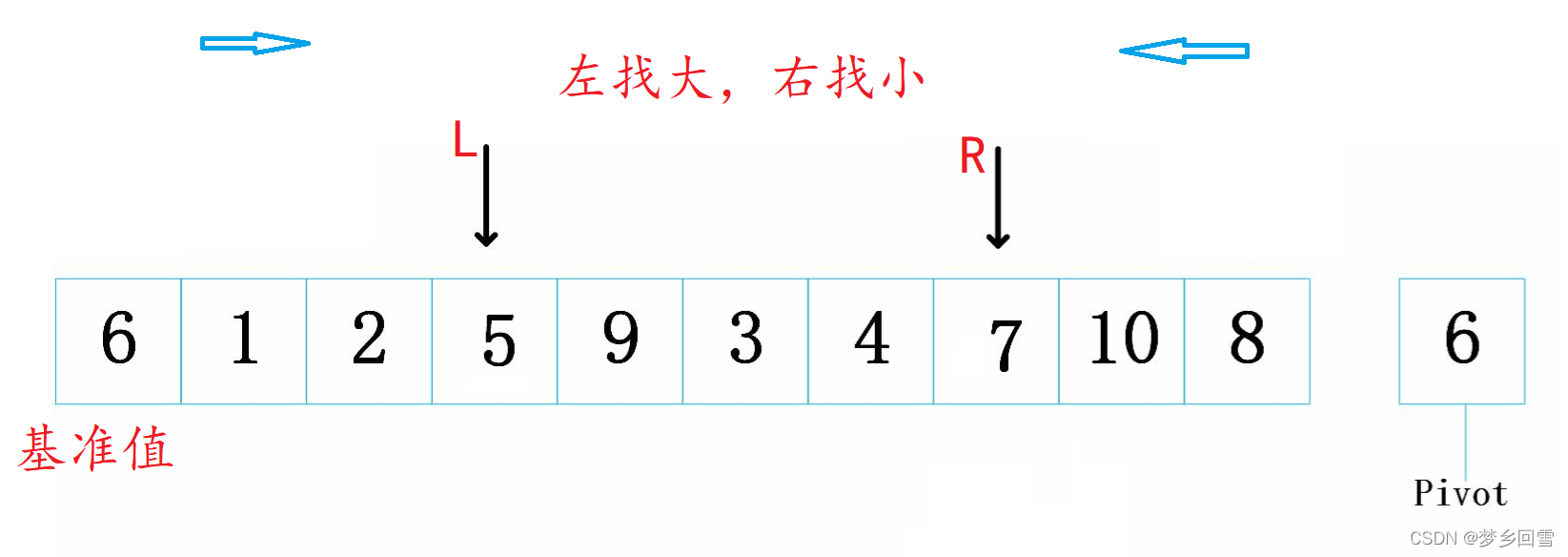
最终效果:相遇交换左指针和基准值,保证了6的左边都比6小,右边比6大。
并且除此之外,由于我们看到这种算法类似于二叉树的思想排好中间再排左右子树,因此我要保证选取的随机值尽量位与中位数。所以我们采取三数取中的方法。(选取最左值最右最中间的数的中位数)效率是可以提升5%到10%的。
?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
|
挖坑法
挖坑法就是对hoare版本的一种变形,过程如下:
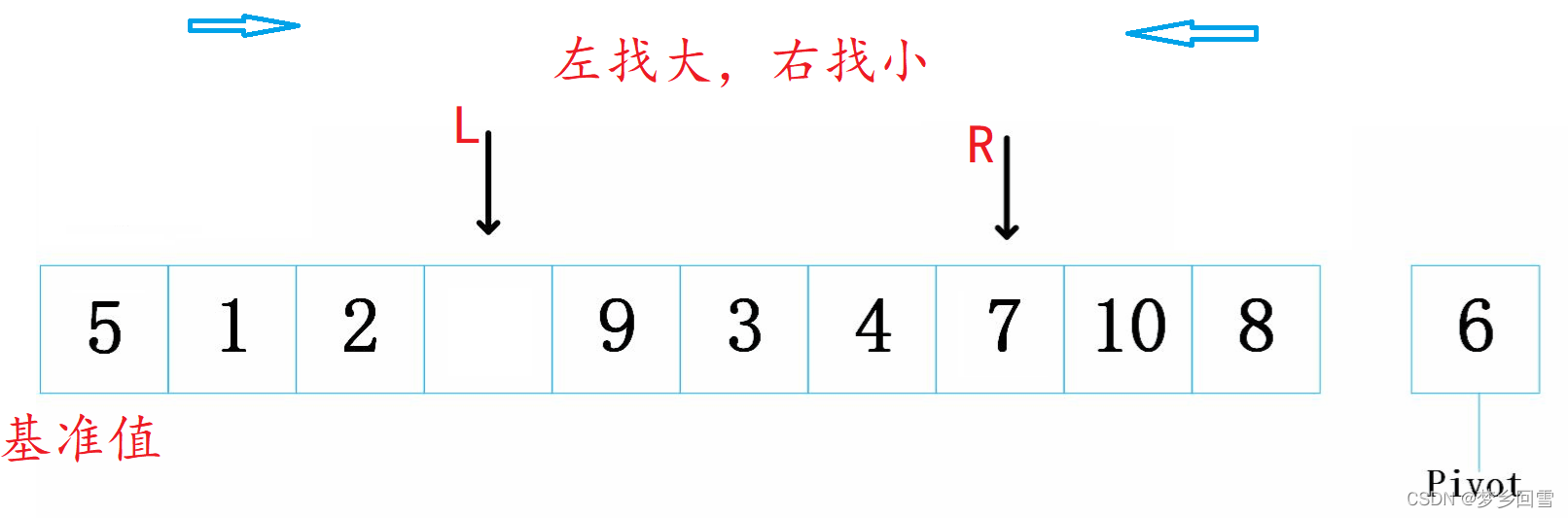
初始如下:先保存基准值,基准值形成一个坑位!

左为基准,右指针先走,找到小的送到坑位,那么此刻右指针形成了新的坑位

左指针出动,找到大的继续送到坑位,左指针形成了新的坑位


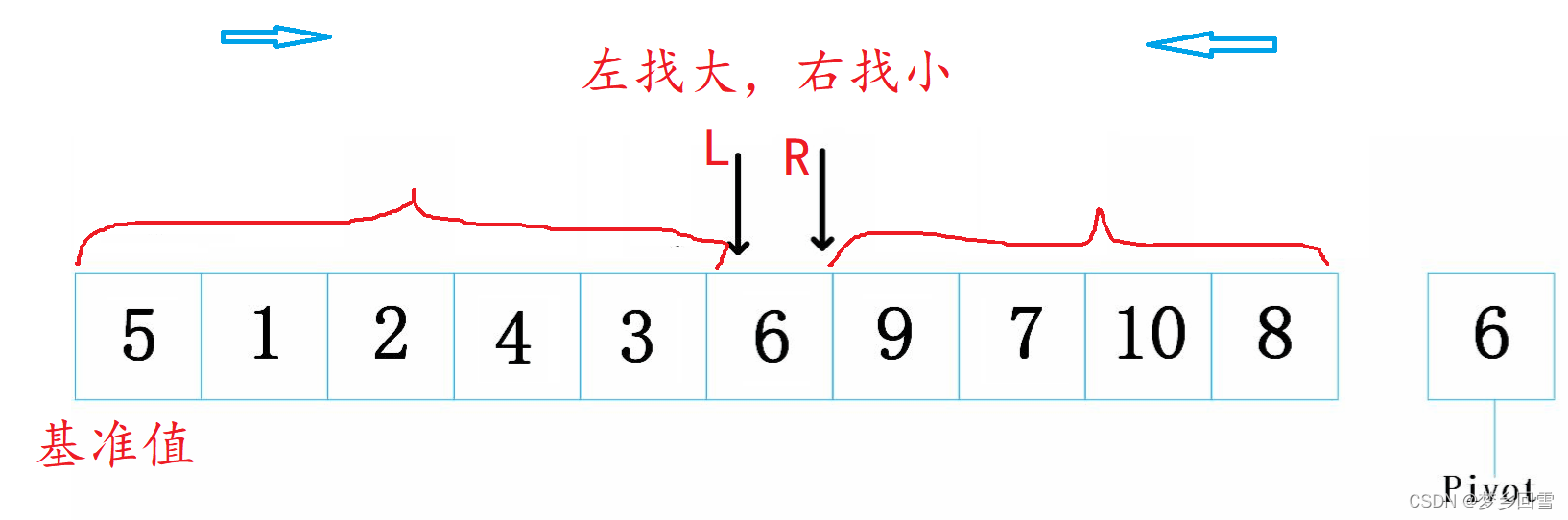
指针相遇,把6写入。也保证左边比6小,右边比6大。代码如下:
?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
|
前后指针版本
顾名思义,使用两个指针,这里选取左为基准值为例,两个指针从左开始出发一个cur,一个prev。
要求:
cur指针先走,一旦找到比基准值小的就停下,++prev,并交换。
cur指针一直到头为止,最后交换prev指向值和基准值


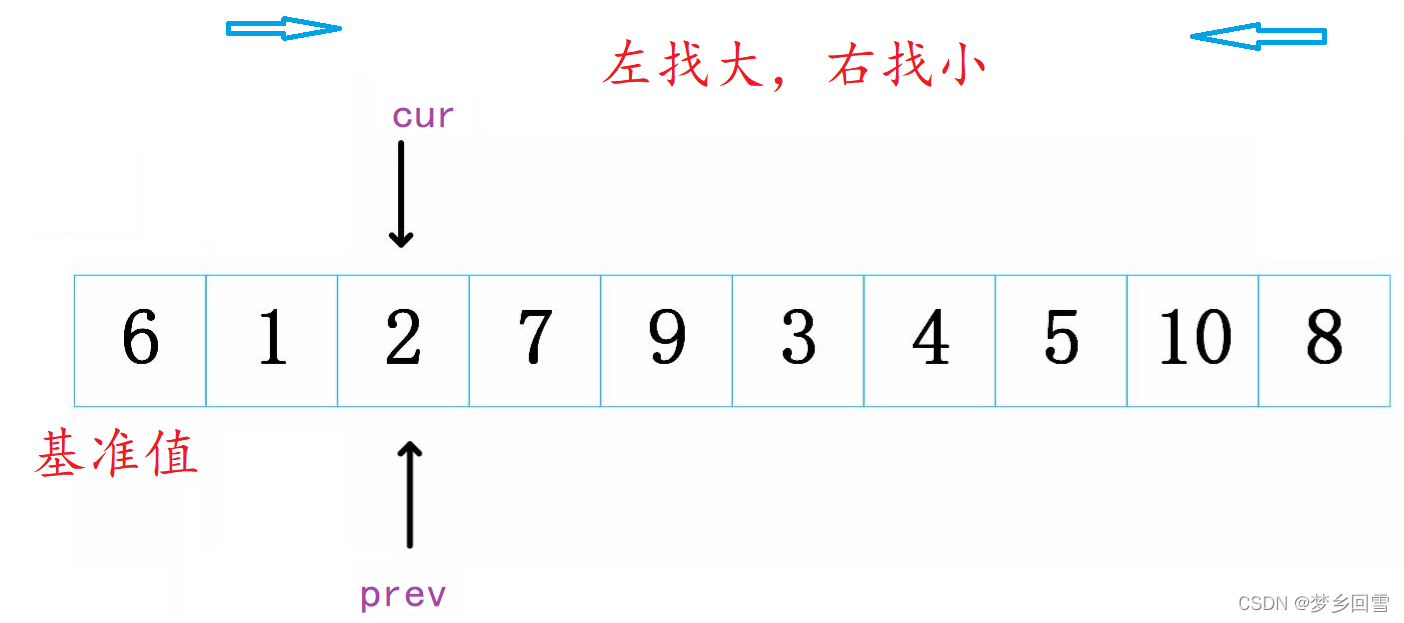
1和2都比6小cur走一步停一步,prev++并交换,指向相等。
cur越过7和9去找小的3,此时停下,prev++指向7交换。(我们注意到prev和cur不等时prev永远是去找大的,cur是找小的,因此交换就做到把cur指向的小的往前扔,大的往后仍,)
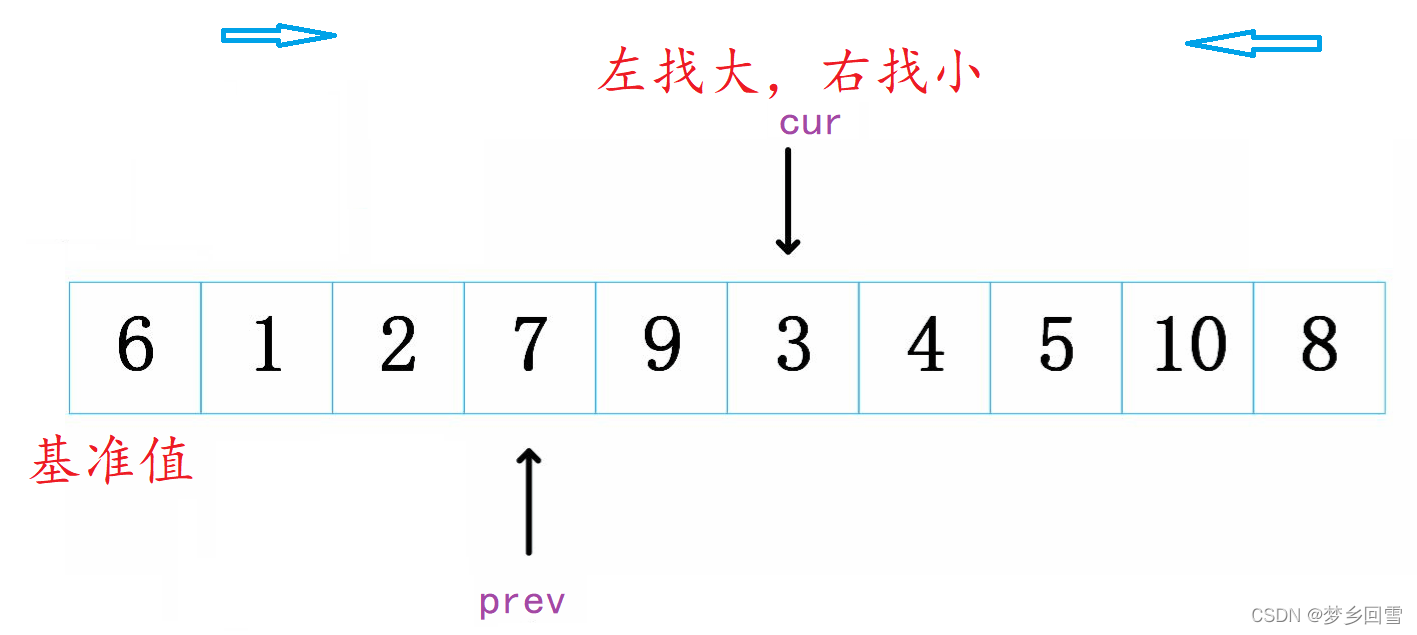
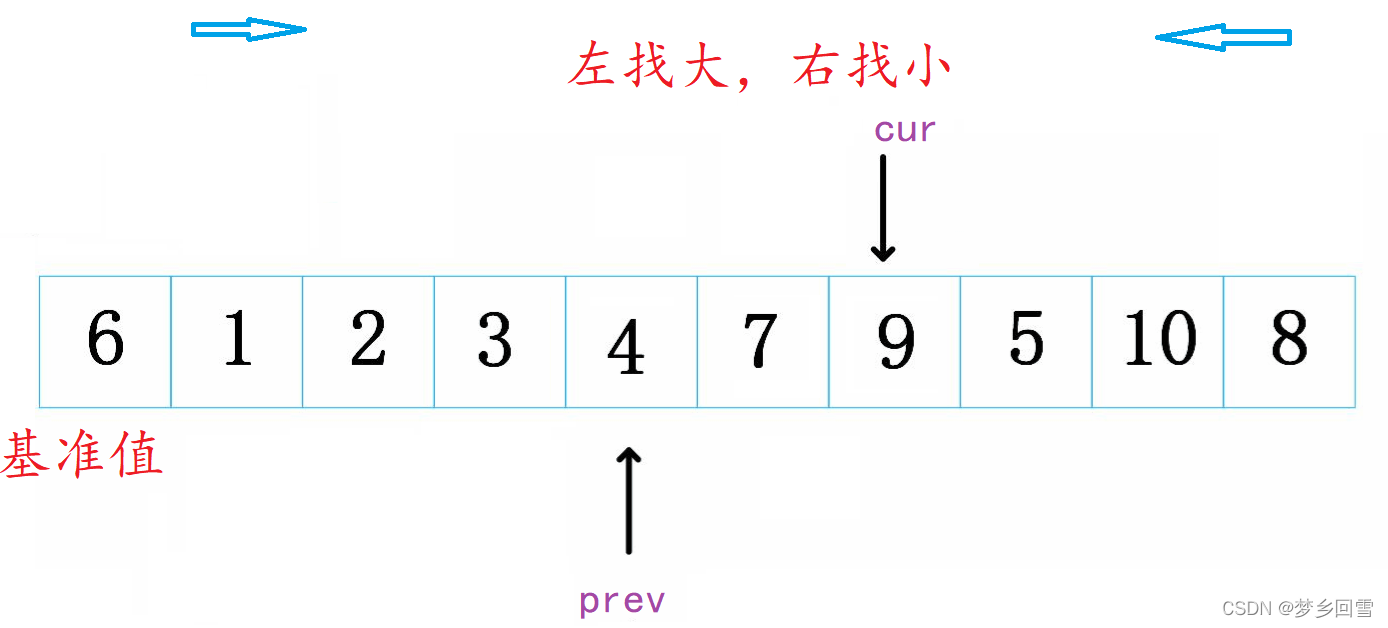


整个过程如上,代码:
?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
小结
递归版本三种方法如上,但是递归毕竟有缺陷,就是需要不断开辟栈帧,当数据量超过10w以上时就会有栈溢出的风险。
并且递归类似二叉树的结构越往下递归调用越多,栈帧翻倍开辟,因此我们还可以去优化一下,就是当递归到左右区间比较小时,我们去控制剩下的排序用别的排序来代替它。
?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
|
非递归:
非递归版本就是改变了快排的框架,用一个栈和循环来代替递归实现。依次将左右下标入栈出栈(出栈之前排序)来模拟递归。
?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
|
七、归并排序
时间复杂度
最坏:-----------o(nlogn)
最好:-----------o(nlogn)
平均:-----------o(nlogn)
空间复杂度
o(n)
稳定性:稳定
基本思想:
归并排序(merge-sort)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(divide andconquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。 动图演示:
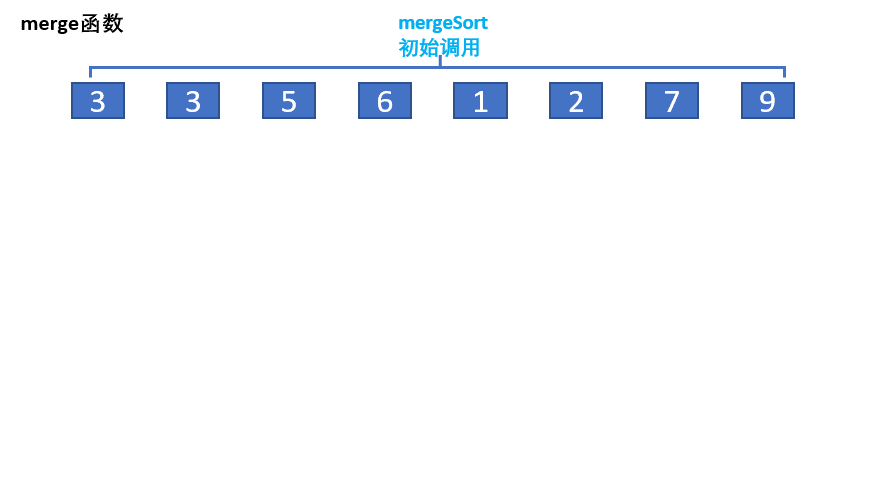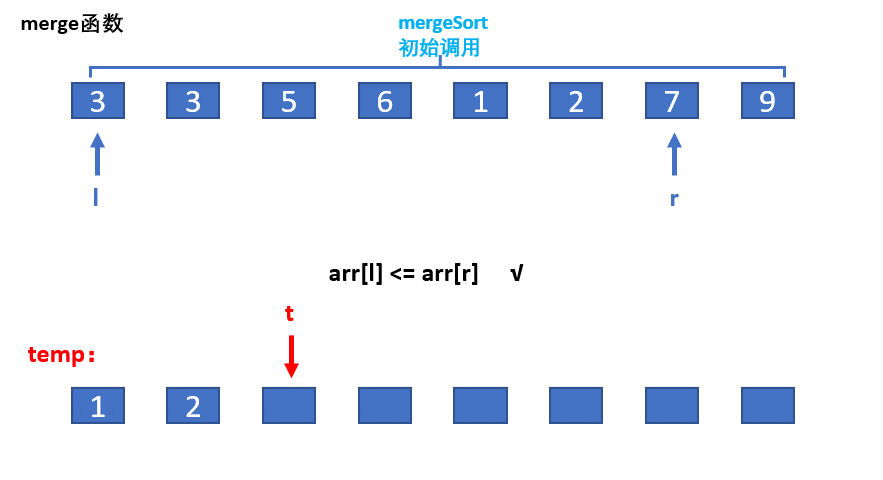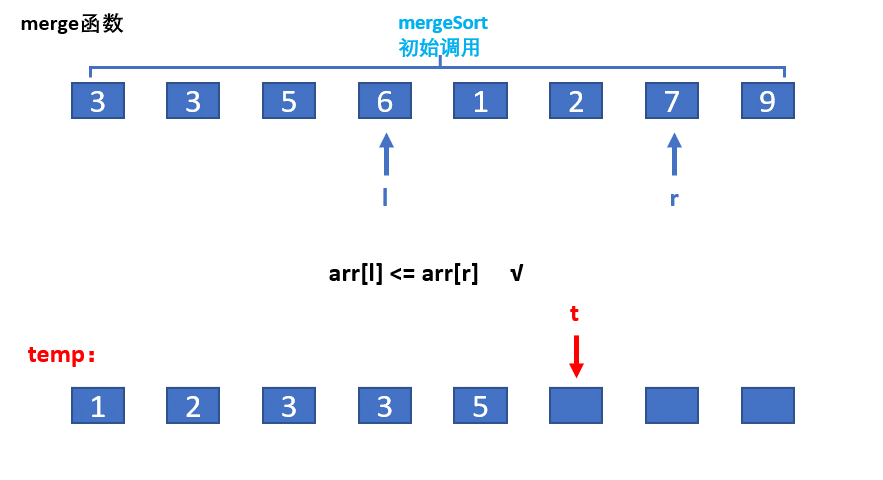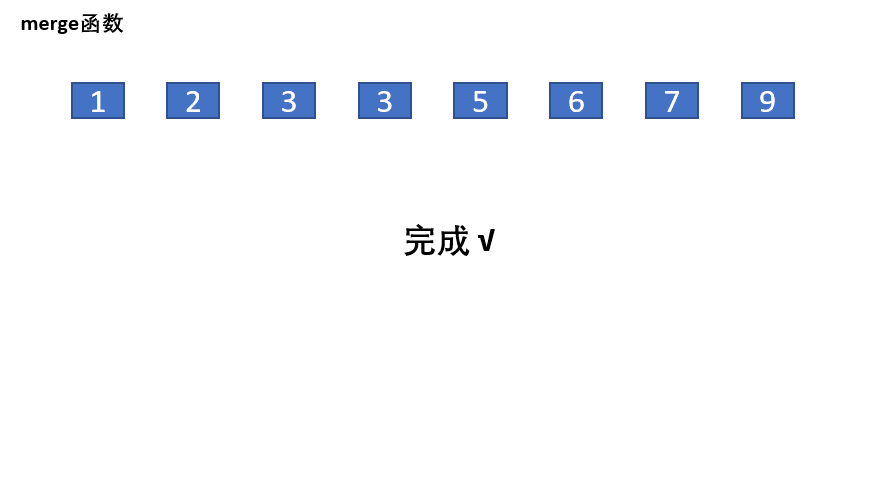
归并的思想就是把先假设数组分成两个有序,对其进行筛选排序,如上图:
但是问题来了我们怎么保证数组是有序的?因此就要求我们从小区间开始对数组归并排序,对于上图中的数据,先对开始3和3归并,小的先进入到tmp数组,因此前两个就是有序,再对,5和6归并,5,6有序后,在归并3,3,5,6……以此类推
代码实现
递归写法
框架:
?
|
1 2 3 4 5 6 7 8 9 10 11 |
|
归并排序:
运用递归先不断缩小偏序区间,在递归层层退出时一遍退出,一边对不断回大的区间归并排序:
?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
|
非递归
非递归的不同就是需要手动控制区间大小,也就是不断2倍扩大区间归并。
但是还需要注意就是当下标是奇数,无法分成整数个组的时候,需要考虑剩余的数,以及是否越界的问题
?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 |
|
八、计数排序
时间复杂度
最坏:-----------o(max(n,范围))
最好:-----------o(max(n,范围))
平均:-----------o(max(n,范围))
空间复杂度
o(范围)
稳定性:不稳定
思想:计数排序又称为鸽巢原理,是对哈希直接定址法的变形应用。 操作步骤:
- 统计相同元素出现次数
- 根据统计的结果将序列回收到原来的序列中
动图如下:

类似桶排序的思想,如上图,先开辟数组统计数组中某一个数出现的次数,比如2出现1次,3出现两次,那么我们直接按顺序读入开辟的数组,在原数组写1一个2,两个3以此类推……
?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
|
计数排序的特性总结:
计数排序在数据范围集中时,效率很高,但是适用范围及场景有限。
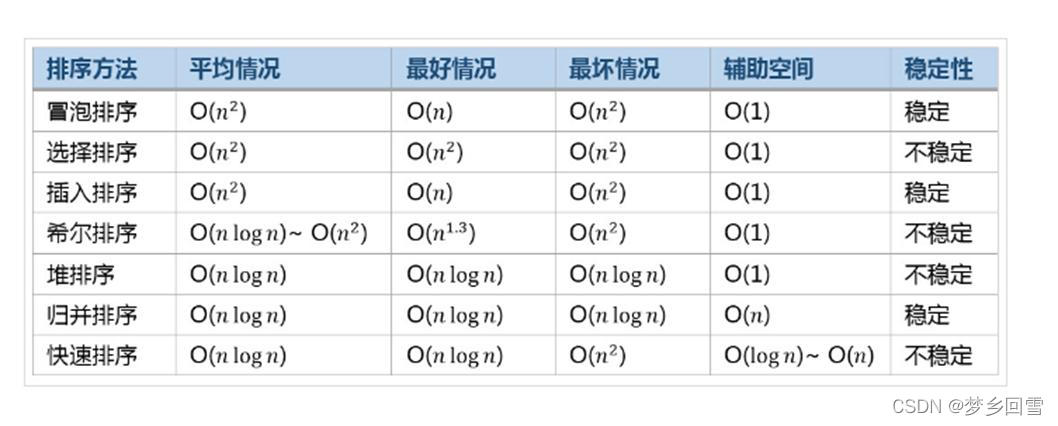
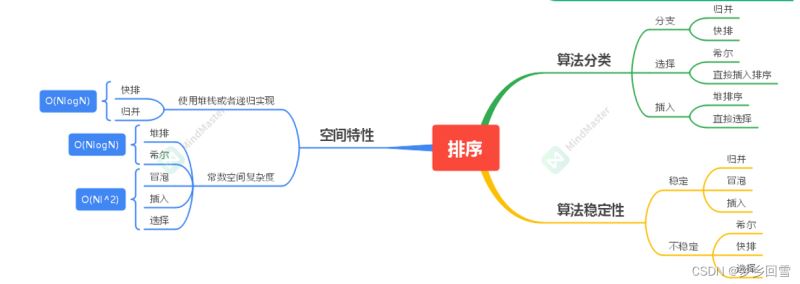
九、各种排序总结比较
1. 复杂度总结
2. 性质分类
以上就是c语言 八大排序算法的过程图解及实现代码的详细内容,更多关于c语言八大排序算法的资料请关注服务器之家其它相关文章!
原文链接:https://blog.csdn.net/weixin_51484780/article/details/121628023
本文链接:https://my.lmcjl.com/post/3165.html
4 评论