微软-多模态ChatGPT来了:Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models - 知乎摘要ChatGPT吸引了各个领域的兴趣,因其提供了一个跨领域的具有卓越会话能力和推理能力的语言界面。然而,由于ChatGPT是一个语言模型,目前无法处理、生成来自视觉世界的图像。同时,视觉基础模型Visual Foundatio…![]() https://zhuanlan.zhihu.com/p/612613742如何评价 ChatGPT 3.5 ?未来的 ChatGPT 4.0 会有哪些升级?未来发展方向是什么? - 知乎小科普:尤里卡,希腊词汇,是发现真相时的感叹词,在游戏文明6中,当你触发尤里卡,你的科技会缩短40%的…
https://zhuanlan.zhihu.com/p/612613742如何评价 ChatGPT 3.5 ?未来的 ChatGPT 4.0 会有哪些升级?未来发展方向是什么? - 知乎小科普:尤里卡,希腊词汇,是发现真相时的感叹词,在游戏文明6中,当你触发尤里卡,你的科技会缩短40%的…![]() https://www.zhihu.com/question/571427024/answer/2911287237visual chatgpt包括三个部分chatgpt,vfm和prompt manager,其中vfm包括很多的下游视觉应用,串联chatgpt和vfm是prompt manager,核心就是langchain,通过langchain的三个接口,initialize_agent,conversationBufferMemory和Tools,其中Tools是将下游vfm的推理能力用prompt描述的形式,conversationBufferMemory是指cot的形式,cot思维链视锥将复杂问题拆成多个子问题可以提升正确率,并且让Ai推理的过程可视化,memory有记录的作用,最终通过initialize_agent来综合。
https://www.zhihu.com/question/571427024/answer/2911287237visual chatgpt包括三个部分chatgpt,vfm和prompt manager,其中vfm包括很多的下游视觉应用,串联chatgpt和vfm是prompt manager,核心就是langchain,通过langchain的三个接口,initialize_agent,conversationBufferMemory和Tools,其中Tools是将下游vfm的推理能力用prompt描述的形式,conversationBufferMemory是指cot的形式,cot思维链视锥将复杂问题拆成多个子问题可以提升正确率,并且让Ai推理的过程可视化,memory有记录的作用,最终通过initialize_agent来综合。
1.introduction
我们能否构建一个类似chatgpt系统,同时支持图像理解和生成?基于chatgpt构建visual chatgpt,合并了多种vfm(visual foundation models),为了弥合chatgpt和这些vfm的能力,提出了一个prompt manager。prompt manager支持一下功能,1.明确告诉chatgpt每个vfm的能力,并指定输入输出。2.转换不同的视觉信息,例如png图像,深度图像和掩码矩阵,语言格式,以帮助chatgpt。3.处理不同的视觉基础模型的历史,优先级和冲突。在prompt manager的帮助下,chatgpt可以利用这些vfm,并以迭代的方式接收他们的反馈,直到它满足用户需求或达到结束条件。
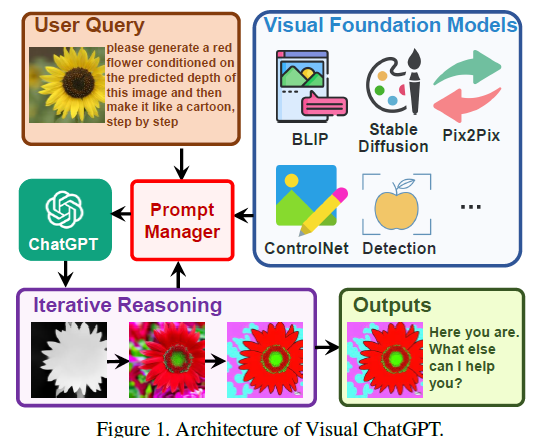
如上图所示:用户上传一个黄色花的图像,然后输入一个复杂的语言指令,"请根据这个图像的深度预测图生成一个红色花朵,然后一步一步的把做成卡通图像"。在prompt manager的帮助下,visual chatgpt启动相关的visual foundation模型的执行链。在这种情况下,首先应用深度估计模型来检测深度信息,然后利用深度-图像模型来生成带有深度信息的红色花卉图像,最后基于稳定扩散模型的风格转换vfm来将图像风格转成卡通图像。在上述pipeline中,prompt manager通过提供可视化格式的类型和记录信息转换过程,充当chatgpt的调度器。

例如上图:把图中的replace the sofa in this image with a desk and then make it like a water-color painting(把这张图中的沙发换成书桌,然后做成水彩画)第二个QA,左边是三轮QA,我没关注的是第二个QA,其中user query输入到prompt manager中,chatgpt决定下游是否使用vfm,若使用vfm则对问题进行拆分,首先进行替换,在进行inpainting操作,见右边,这就是cot。
下游有一系列的基础应用。

本文链接:https://my.lmcjl.com/post/3439.html
4 评论