微软-多模态ChatGPT来了:Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models - 知乎摘要ChatGPT吸引了各个领域的兴趣,因其提供了一个跨领域的具有卓越会话能力和推理能力的语言界面。然而,由于ChatGPT是一个语言模型,目前无法处理、生成来自视觉世界的图像。同时,视觉基础模型Visual Foundatio…https 继续阅读
Search Results for: drawing
查询到最新的4条
Visual ChatGPT可视化的chatgpt
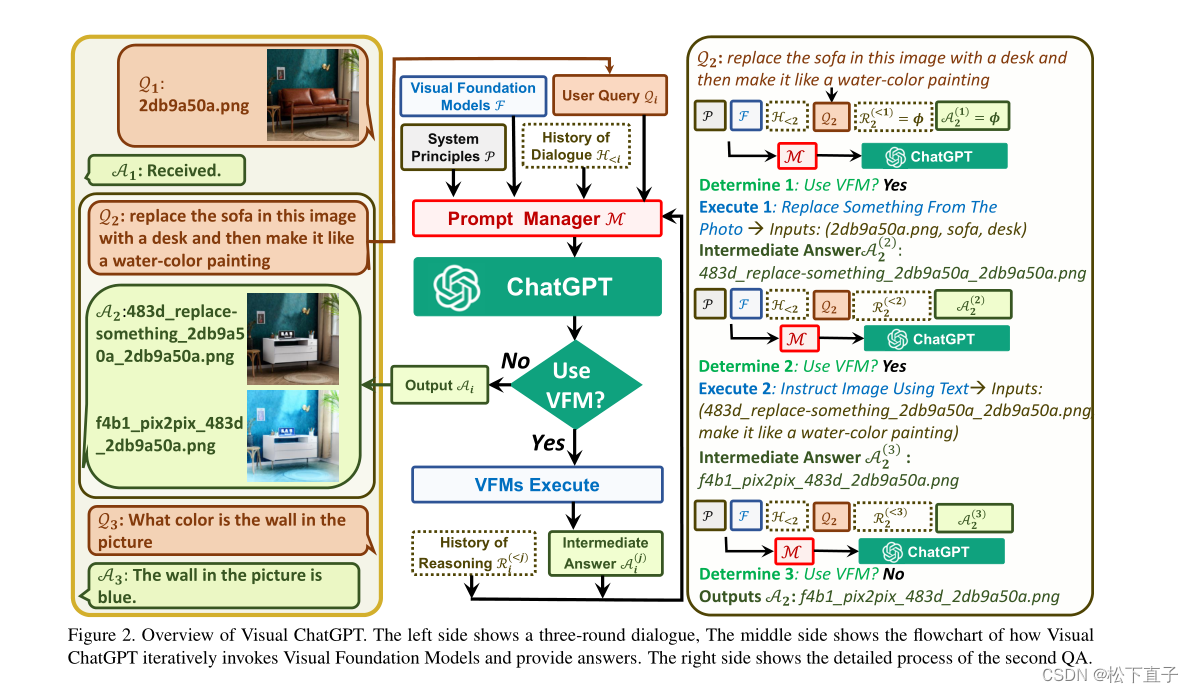
Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models 摘要 不仅发送和接收语言,还发送和接收图像提供复杂的视觉问题或视觉编辑指令,这些问题需要多个AI模型以多步骤协作提供反馈并要求纠正结果考虑到多输入/输出模型和需要视觉反馈的模型,设计了一系列提示符将可视化模型信息注入到ChatGPT中代码地址 引言 ChatGPT建立在InstructGPT的基础上 继续阅读
(小伞每日论文概读)视觉ChatGPT?让ChatGPT能画画的模型设计!

声明 本篇文章的相关图片来源于论文:Visual ChatGPT: Talking, Drawing and Editing with Visual Foundation Models 论文链接如下:https://arxiv.org/pdf/2303.04671.pdf 碍于本人的知识水平所限,本篇文章的总结可能存在不妥之处,如: 作为参考,请谨慎推理内容的真实性(人某种意义上与chatg 继续阅读
Label立体字体效果

一.效果图 二.简单谈谈实现思路 应该说实现方法还是很简单的,就是错位绘制而已.当然,这种效果没有完全体现出字体的立体效果,只是一种错位模仿,在对字体的边框进行描边后,又移动了一下绘制的坐标来体现阴影.感兴趣的朋友应该很容易实现.这里就不多说了. 三.部分源代码 using System; using System.Collections.Generic; using System.ComponentModel; using System.Drawing; usin 继续阅读