目录
一、使用官网
1、地址
2、例子 - examples
3、api-reference
1、查询所有model的接口
2、创建聊天
3、画图
4、音频转文字
4、测试场地-playground
二、介绍model
一、使用官网
1、地址
首先登录openai官网,可能需要科学上网

2、例子 - examples
这里是一些官方推荐的例子,一共是48个
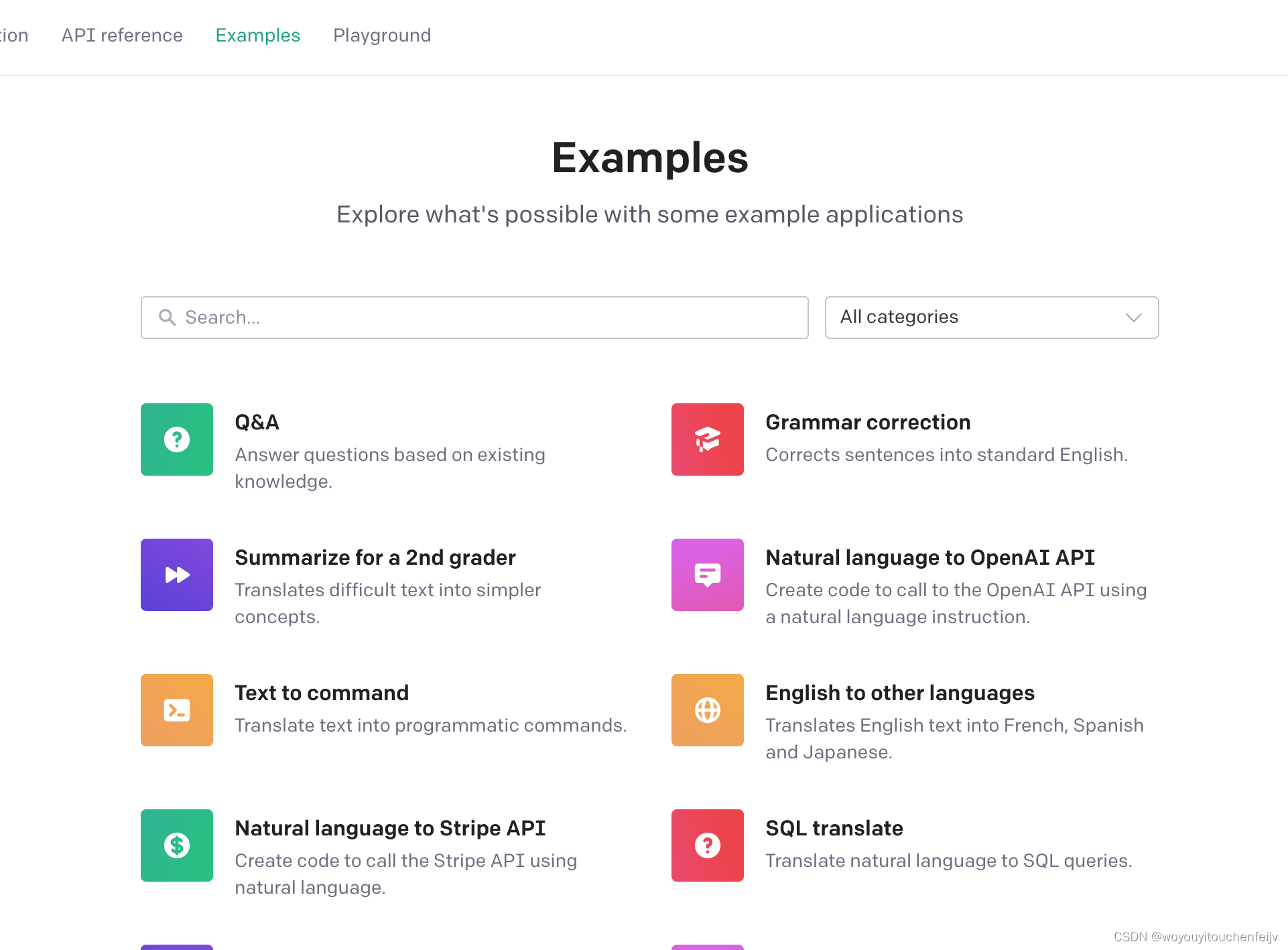
点击每个例子,都会弹出一个调用,并且根据你的需求选择语言。

这个时候,可以看到有一个参数叫model,那如何获得有什么model呢,就需要进入api-reference自己查了。
3、api-reference
已进入,open就要你安装pythone和node,其实完全不用安装(这些包只是方便你调用,我是写Java的,安什么pythone!!!)

直接往下,看有什么接口。里面太多了,我还没来得及全部使用。目前就我使用过的,在这里整理了几个重要的接口
1、查询所有model的接口
curl https://api.openai.com/v1/models \-H "Authorization: Bearer apiKey" \-H "OpenAI-Organization: 你自己的组织"这个接口是可以查询有多少种model,上面的例子里面其实也是使用这些model。这些model是有各自的擅长的地方。header里的Authorization 参数一定要带上Bearer ,不然会报错!
2、创建聊天
curl https://api.openai.com/v1/chat/completions \-H "Content-Type: application/json" \-H "Authorization: Bearer apiKey" \-d '{"model": "gpt-3.5-turbo","messages": [{"role": "user", "content": "Say this is a test!"}],"temperature": 0.7}'用到最多的接口,其实也就是问答。不过这个是使用gpt-3.5-turbo model。
3、画图
curl https://api.openai.com/v1/images/generations \-H "Content-Type: application/json" \-H "Authorization: Bearer apiKey" \-d '{"prompt": "A cute baby sea otter","n": 2,"size": "1024x1024"}'
4、音频转文字
curl https://api.openai.com/v1/audio/transcriptions \-H "Authorization: Bearer apiKey" \-H "Content-Type: multipart/form-data" \-F file="@/path/to/file/audio.mp3" \-F model="whisper-1"
还有好多接口,其他的可以自行去找。
4、测试场地-playground
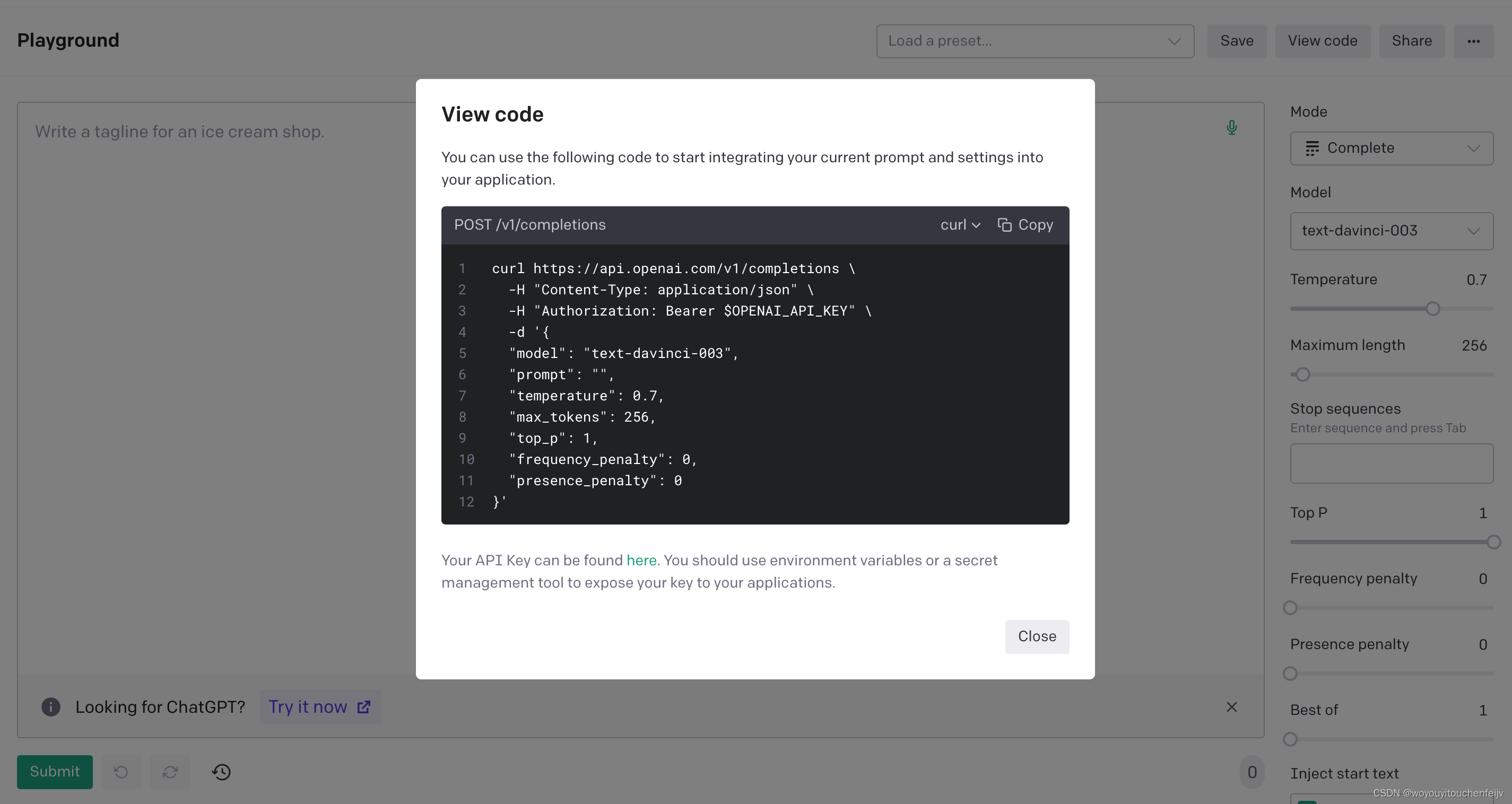
你所有的接口都可以在这里测试,包括选择model,选择语气等等。然后点击 view code按钮拿到请求格式。放到自己代码里。
二、介绍model
说完官网结构,介绍下模型。调用接口发现一共64中,这是我让GPT自己介绍的
如何发请求就看各自的了。大家可以根据自己的需求,在playground中调出想要的接口模型,放到自己代码里。如果需要用什么jar包或者依赖,完全可以问GPT自己。
最后,小心自己的流量哦!!GPT默认除了在页面和他聊天外,使用playground 和api接口发送的请求都是要收费的。免费的5¥ 用完就GG了。
收费标准在官网也有https://platform.openai.com/account/billing/overview
本文链接:https://my.lmcjl.com/post/5101.html
4 评论