文章目录
- 本文导读
- 1. 数字识别
- 2. 图像识别
- 3. 图像分类
- 4. 目标检测
- 5. 人脸识别
- 6. 文本分类
- 7. 聊天机器人
- 8. 书籍推荐(包邮送书5本)
本文导读
1. 数字识别
数字识别是计算机从纸质文档、照片或其他来源接收、理解并识别可读的数字的能力,目前比较受关注的是手写数字识别。手写数字识别是一个典型的图像分类问题,已经被广泛应用于汇款单号识别、手写邮政编码识别等领域,大大缩短了业务处理时间,提升了工作效率和质量。

2. 图像识别
图像识别,是指利用计算机对图像进行处理、分析和理解,以识别各种不同模式的目标和对象的技术,是应用深度学习算法的一种实践应用。 现阶段图像识别技术一般分为人脸识别与商品识别,人脸识别主要运用在安全检查、身份核验与移动支付中;商品识别主要运用在商品流通过程中,特别是无人货架、智能零售柜等无人零售领域
图像的传统识别流程分为四个步骤:图像采集→图像预处理→特征提取→图像识别。图像识别软件国外代表的有康耐视等,国内代表的有图智能、海深科技等。另外在地理学中指将遥感图像进行分类的技术。

3. 图像分类
图像分类,根据各自在图像信息中所反映的不同特征,把不同类别的目标区分开来的图像处理方法。它利用计算机对图像进行定量分析,把图像或图像中的每个像元或区域划归为若干个类别中的某一种,以代替人的视觉判读。
常用的分类方法:
- 基于色彩特征的索引技术:色彩是物体表面的一种视觉特性,每种物体都有其特有的色彩特征,譬如人们说到绿色往往是和树木或草原相关,谈到蓝色往往是和大海或蓝天相关,同一类物体往拍几有着相似的色彩特征,因此我们可以根据色彩特征来区分物体.用色彩特特征进行图像分类一可以追溯到Swain和Ballard提出的色彩直方图的方法.由于色彩直方图具有简单且随图像的大小、旋转变化不敏感等特点,得到了研究人员的厂泛关注,目前几乎所有基于内容分类的图像数据库系统都把色彩分类方法作为分类的一个重要手段,并提出了许多改进方法,归纳起主要可以分为两类:全局色彩特征索引和局部色彩特征索引。
- 基于纹理的图像分类技术:纹理特征也是图像的重要特征之一,其本质是刻画象素的邻域灰度空间分布规律由于它在模式识别和计算机视觉等领域已经取得了丰富的研究成果,因此可以借用到图像分类中。
- 基于形状的图像分类技术:形状是图像的重要可视化内容之一在二维图像空间中,形状通常被认为是一条封闭的轮廓曲线所包围的区域,所以对形状的描述涉及到对轮廓边界的描述以及对这个边界所包围区域的描述.目前的基于形状分类方法大多围绕着从形状的轮廓特征和形状的区域特征建立图像索引。关于对形状轮廓特征的描述主要有:直线段描述、样条拟合曲线、傅立叶描述子以及高斯参数曲线等等。
- 基于空间关系的图像分类技术:在图像信息系统中,依据图像中对象及对象间的空间位置关系来区别图像库中的不同图像是一个非常重要的方法。因此,如何存贮图像对象及其中对象位置关系以方便图像的分类,是图像数据库系统设计的一个重要问题。而且利用图像中对象间的空间关系来区别图像,符合人们识别图像的习惯,所以许多研究人员从图像中对象空间位置关系出发,着手对基于对象空间位置关系的分类方法进行了研究。早在1976年,Tanimoto提出了用像元方法来表示图像中的实体,并提出了用像元来作为图像对象索引。随后被美国匹兹堡大学chang采纳并提出用二维符号串(2D一String)的表示方法来进行图像空间关系的分类,由于该方法简单,并且对于部分图像来说可以从ZD一String重构它们的符号图,因此被许多人采用和改进,该方法的缺点是仅用对象的质心表示空间位置;其次是对于一些图像来。

4. 目标检测
目标检测,也叫目标提取,是一种基于目标几何和统计特征的图像分割。它将目标的分割和识别合二为一,其准确性和实时性是整个系统的一项重要能力。
它将目标的分割和识别合二为一,其准确性和实时性是整个系统的一项重要能力。尤其是在复杂场景中,需要对多个目标进行实时处理时,目标自动提取和识别就显得特别重要。
随着计算机技术的发展和计算机视觉原理的广泛应用,利用计算机图像处理技术对目标进行实时跟踪研究越来越热门,对目标进行动态实时跟踪定位在智能化交通系统、智能监控系统、军事目标检测及医学导航手术中手术器械定位等方面具有广泛的应用价值。

5. 人脸识别
人脸识别,是基于人的脸部特征信息进行身份识别的一种生物识别技术。用摄像机或摄像头采集含有人脸的图像或视频流,并自动在图像中检测和跟踪人脸,进而对检测到的人脸进行脸部识别的一系列相关技术,通常也叫做人像识别、面部识别。
人脸识别系统主要包括四个组成部分,分别为:人脸图像采集及检测、人脸图像预处理、人脸图像特征提取以及匹配与识别。

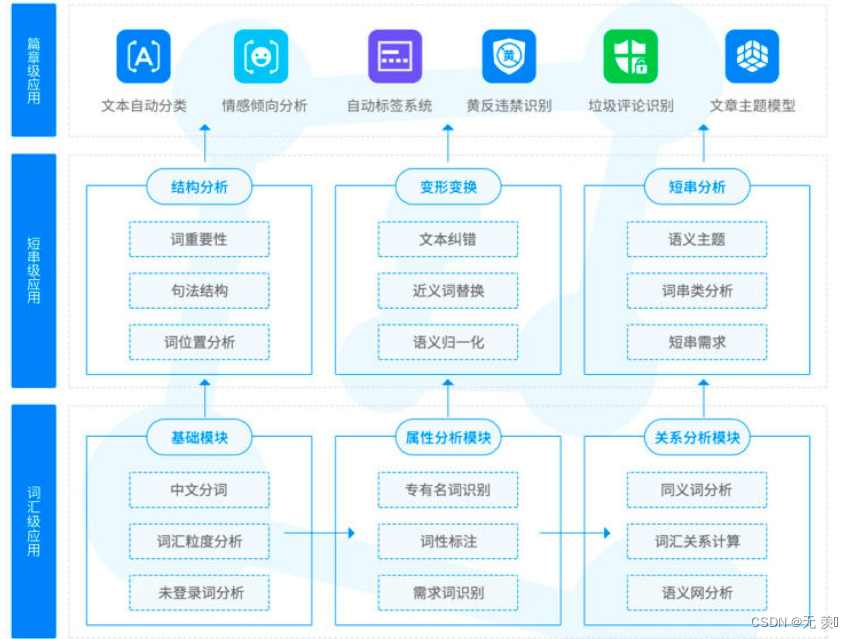
6. 文本分类
文本分类用电脑对文本集(或其他实体或物件)按照一定的分类体系或标准进行自动分类标记。 它根据一个已经被标注的训练文档集合, 找到文档特征和文档类别之间的关系模型, 然后利用这种学习得到的关系模型对 新的文档进行类别判断 。文本分类从基于知识的方法逐渐转变为基于统计 和机器学习的方法。
词匹配法:词匹配法是最早被提出的分类算法。这种方法仅根据文档中是否出现了与类名相同的词(顶多再加入同义词的处理)来判断文档是否属于某个类别。很显然,这种过于简单机械的方法无法带来良好的分类效果。
统计学习:统计学习方法需要一批由人工进行了准确分类的文档作为学习的材料(称为训练集,注意由人分类一批文档比从这些文档中总结出准确的规则成本要低得多),计算机从这些文档中挖掘出一些能够有效分类的规则,这个过程被形象的称为训练,而总结出的规则集合常常被称为分类器。训练完成之后,需要对计算机从来没有见过的文档进行分类时,便使用这些分类器来进行。
7. 聊天机器人
近日,人工智能研究公司OpenAI推出的一款名为ChatGPT的聊天机器人火遍全球。ChatGPT不仅能流畅地与人对话,还能写代码、找Bug、做海报、构建虚拟机等等。
从整体技术路线上来看,ChatGPT使用了GPT-3.5大规模语言模型(LLM,Large Language Model),并在该模型的基础上引入强化学习来Fine-turn预训练的语言模型。这里的强化学习采用的是RLHF(Reinforcement Learning from Human Feedback),即采用人工标注的方式。目的是通过其奖励惩罚机制(reward)让LLM模型学会理解各种NLP任务并学会判断什么样的答案是优质的(helpfulness、honest、harmless三个维度)。

8. 书籍推荐(包邮送书5本)
本文链接:https://my.lmcjl.com/post/6572.html
4 评论