一.简单介绍
urllib库:是python的内置请求库,常用于网页的请求访问。
包括以下模块:
urllib.request 请求模块
urllib.error 异常处理模块
urllib.parse url解析模块
urllib.robotparser robots.txt解析模块
二.实践操作
(1)针对含参数访问
import urllib.request
import urllib.parse
import string
def get_method_params():url = "http://www.baidu.com/s?" param = { #多个参数,利用字典的形式完成"wd":"中文","key":"zhang","value": "san"}# 将字典转换成参数形式的字符串result = str(param)# 这个方法可以将URL转化为计算机可以识别的状态,且多个参数之间补充&,补充=strpa = urllib.parse.urlencode(param)#拼接参数finurl = url + strpa# 将带有中文的url转化为可以识别的状态encode_url = urllib.parse.quote(finurl, safe=string.printable) # 这里后面的参数是一个固定写法,用来保证原有的URL的状态#发送网络请求res = urllib.request.urlopen(encode_url)data = res.read().decode("utf-8")#获得爬取数据,根据网页编码方式进行解码print(data)
get_method_params()
可以看到完成网络请求的API是urllib.request.urlopen(),注意这里的param是访问请求的传入参数,是绑定在地址URL上的组成一个完整的URL。
详细参数情况如下:
1.url:传递访问的地址;
2.data:用于传递访问网页的必要参数,可选。如果要添加该参数,并且如果它是字节流编码格式的内容,即bytes类型,则需要通过bytes()方法转化。另外,如果传递了这个参数,则它的请求方式就不再是GET方式,而是POST方式。
import urllib.parse
import urllib.request
data = bytes(urllib.parse.urlencode({'word': 'hello'}), encoding='utf8')
print(data)
response = urllib.request.urlopen('http://httpbin.org/post', data=data)
print(response.read())
这里使用到了urllib的解析模块中的urlencode()这个API。要用urllib.parse模块里的urlencode()方法来将参数字典转化为字符串。实现转义。这里的参数是发送网络POST请求时携带的参数,与URL并不组成一体。
3.timeout:超时参数设置,可选。
4.其他参数
除了data参数和timeout参数外,还有context参数,它必须是ssl.SSLContext类型,用来指定SSL设置。
此外,cafile和capath这两个参数分别指定CA证书和它的路径,这个在请求HTTPS链接时会有用。
cadefault参数现在已经弃用了,其默认值为False。
(2)添加访问请求参数的完整请求类型:Request
为防止各类反爬,最基本的就是在发送请求同时携带请求头headers,可以包含各类参数,包括User-Agent,Accept-Encoding等等,具体参数数据参看不同网页的html。
具体实现:
import urllib.request
def load_baidu():url = "http://www.baidu.com/s?"#创建一个请求对象,目的是加出请求头信息,防止反扒request = urllib.request.Request(url)#添加请求头信息#动态的添加请求头信息request.add_header("User-Agent",'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36')#发送网络请求reponse = urllib.request.urlopen(request)#请求结果返回strdata = reponse.read().decode("utf-8")#返回结果的读取和解码print(strdata)#响应头print(reponse.headers)#查看响应头 一般没有大用处#请求头!!!重要!!方法1:获取请求头的全部信息requestheader = request.headersprint(requestheader)#这是手动在代码段里面写出来的# 方法2:获取请求头信息,注意他是获取请求头中的一部分信息,需要传参result = request.get_header("User-agent")print(result)#获取完整URL的方式finurl = request.get_full_url()print(finurl)with open("01-header.html","w",encoding="utf-8")as f:f.write(strdata)
load_baidu()
这里就实现了添加请求头的设置以及两种获得请求头的方法,一种获得完整URL的方法。
利用的API:
第一个参数url用于请求URL,这是必传参数,其他都是可选参数。
第二个参数data如果要传,必须传bytes(字节流)类型的。如果它是字典,可以先用urllib.parse模块里的urlencode()编码。
第三个参数headers是一个字典,它就是请求头,我们可以在构造请求时通过headers参数直接构造,也可以通过调用请求实例的add_header()方法添加。
第四个参数origin_req_host指的是请求方的host名称或者IP地址。
第五个参数unverifiable表示这个请求是否是无法验证的,默认是False,意思就是说用户没有足够权限来选择接收这个请求的结果。例如,我们请求一个HTML文档中的图片,但是我们没有自动抓取图像的权限,这时unverifiable的值就是True。
第六个参数method是一个字符串,用来指示请求使用的方法,比如GET、POST和PUT等。
(3)关于高级应用即各类型的Handler!
首先,urllib.request模块里的BaseHandler类,它是所有其他Handler的父类。
接下来,就有各种Handler子类继承这个BaseHandler类:
HTTPDefaultErrorHandler:用于处理HTTP响应错误,错误都会抛出HTTPError类型的异常。
HTTPRedirectHandler:用于处理重定向。
HTTPCookieProcessor:用于处理Cookies。
ProxyHandler:用于设置代理,默认代理为空。
HTTPPasswordMgr:用于管理密码,它维护了用户名和密码的表。
HTTPBasicAuthHandler:用于管理认证,如果一个链接打开时需要认证,那么可以用它来解决认证问题。另外,还有其他的Handler类,详情可以参考官方文档。
然后利用这些handler创建opener,再次发送网络请求opener.open()。
举例实现:
(3.1)利用handler实现IP代理
import urllib.request
def proxy_user():url = "http://www.baidu.com/"#前面的 代理IPproxy = {"http": "39.137.168.229:8080"}#(1)创建可以添加IP的处理器,创建处理器的时候IP作为参数传入proxy_handler = urllib.request.ProxyHandler(proxy)#真正发送网络请求的不是处理器(handler),而是opener#创建真正发送网络请求的opener(处理器作为参数)opener = urllib.request.build_opener(proxy_handler)#拿着IP发送网络请求,参数就是网页的链接reponse = opener.open(url)data = reponse.read().decode("utf-8")print(data)with open("04-data.html","w",encoding="utf-8")as f:f.write(data)
proxy_user()
具体, 先创建一个代理的handler,然后利用这个Handler及build_opener()方法构造一个Opener,之后发送请求即可。
(3.2)利用处理器Handler实现携带cookies,发送请求
import urllib.request
import ssl
ssl._create_default_https_context = ssl._create_unverified_context#全局除去SSL的警告
from http import cookiejar
#用来管理cookie
from urllib import parse
#用来参数转码解析# 1.1登陆之前获取用户账号密码(登陆界面
# 1.2发送请求登陆用(账号密码)(查看登陆所需要的参数)
url = "https://www.wlyxmusic.net/"
header = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36","cookie":"BAIDUID=6EB65BD9F8F5377811634CAB0FA826EB:FG=1; BIDUPSID=6EB65BD9F8F5377811634CAB0FA826EB; PSTM=1550312207; delPer=0; H_PS_PSSID=1420_25810_21110_28607_28584_28558_28604_28626_28605; BDUSS=lNNEE1NjdqcXNNZ1BTOFlTWmszSGdlQ0kwZUpLaWRXNkZSaDZESlZUaUpIS2RjQVFBQUFBJCQAAAAAAAAAAAEAAACUUKYhz9LBrMTjztIAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAImPf1yJj39cbH; PHPSESSID=b9073fqe459o63kh8bsn9gr1v1; Hm_lvt_4010fd5075fcfe46a16ec4cb65e02f04=1551863694; Hm_lpvt_4010fd5075fcfe46a16ec4cb65e02f04=1551863694"}#这个cookie是登陆界面的cookie# 构造请求参数(post请求参数必须是字典形式)
login_datas = {'username':"*******","password":"***********","formhash":"*****","referer":"https://www.wlyxmusic.net/"}
#post上传参数必须是二进制类型,将参数转码
log_bytes_datas = parse.urlencode(login_datas).encode("utf-8")#会返回一个二进制数据给我们#构造请求头对象
request = urllib.request.Request(url,headers=header,data=log_bytes_datas)# 发送请求
cook= cookiejar.CookieJar()#保存cookie用
#创建可以添加cookie的处理器(handler),原因还是urlopen没有保存cookie的参数
cookhandler = urllib.request.HTTPCookieProcessor(cook)
opener = urllib.request.build_opener(cookhandler)
reponse = opener.open(request)
#既包含请求信息,又包含参数信息,还有cookie信息
#如果发送请求成功自动保存cookie,这个cookie是个人中心的cookie#2访问个人中心页面(opener对象里面有cookie)# # 2.1个人中心url# 构造请求对象
center_url = "https://www.wlyxmusic.net/space-uid-19759.html"
#构造请求对象
center_request = urllib.request.Request(center_url,headers=header)# 发送网络请求(拿刚刚创建好的opener着cookie里面的信息去发送)
response2 = opener.open(center_request)
data = response2.read().decode("utf-8")
with open("06.html","w",encoding="utf-8")as f:f.write(data)
#到此就是可以通过用户账号密码进入个人中心了
利用cookie的处理器实现cookieJar()对访问页面的保存,从而实现个人中心页面的访问。
首先,我们必须声明一个CookieJar对象。接下来,就需要利用HTTPCookieProcessor来构建一个Handler,最后利用build_opener()方法构建出Opener,执行open()函数即可。
三.Urllib.request的异常处理
urllib的error模块定义了由request模块产生的异常。针对网络请求的各种异常情况进行了包装。
- URLError
URLError类来自urllib库的error模块,它继承自OSError类,是error异常模块的基类,由request模块生的异常都可以通过捕获这个类来处理。 - HTTPError
它是URLError的子类,专门用来处理HTTP请求错误,比如认证请求失败等。它有如下3个属性。
code:返回HTTP状态码,比如404表示网页不存在,500表示服务器内部错误等。
reason:同父类一样,用于返回错误的原因。
headers:返回请求头。
因为URLError是HTTPError的父类,所以可以先选择捕获子类的错误,再去捕获父类的错误
这样就可以做到先捕获HTTPError,获取它的错误状态码、原因、headers等信息。如果不是HTTPError异常,就会捕获URLError异常,输出错误原因。最后,用else来处理正常的逻辑。这是一个较好的异常处理写法。
具体依赖博客:https://cuiqingcai.com/5505.html
四.解析链接模块
urllib库里还提供了parse这个模块,它定义了处理URL的标准接口,例如实现URL各部分的抽取、合并以及链接转换。
1.urlparse():识别URL并分段,6段: scheme(协议)、netloc(域名)、path(路径)、params(参数)、query(疑问)和fragment(碎片)。
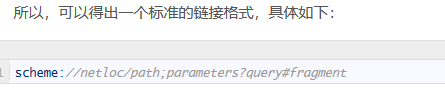
2.urlunparse():将分段进行合并成完整的URL
3.urlsplit():不单独解析params这一部分,将url分段为5段(params会跟到path后面)
4.urlunsplit():五段合并
5.urljoin():将两个链接合并,由新连接对基础连接进行修改
6.urlencode():将字典参数序列化到url链接当中,常用于get请求当中
7.parse_qs():反序列化,针对url当中的请求参数部分解析回字典格式
8.parse_qsl():反序列化方法二,针对url当中的请求参数部分解析回列表
9.quote():针对url的中文参数部分进行url编码
10.unquote():对已经形成的完整URL由中文编码的部分转为普通中文(解码)
原文链接:https://cuiqingcai.com/5508.html
(参考:[Python3网络爬虫开发实战] 3.1.3-解析链接)
五.附录:
很多内容是在崔神的博客等其他大佬那里学来滴,追加原文链接:
https://cuiqingcai.com/5500.html
https://www.cnblogs.com/zhaof/p/6910871.html
https://docs.python.org/3/library/urllib.request.html#urllib.request.Request
本文链接:https://my.lmcjl.com/post/6573.html
4 评论