推荐编程书籍:Python网络爬虫权威指南 第2版,由人民邮电出版社2019-04-01月出版发行,本书编译以及作者信息 为:瑞安·米切尔(Ryan Mitchell) 著,神烦小宝 译,此次为第2次发行, 国际标准书号为:9787115509260,品牌为人民邮电出版社, 这本书采用平装开本为16开,纸张采为胶版纸,全书共有241页字数万字,是本Python 编程相关非常不错的书。此书内容摘要 本书采用简洁强大的Python 语言,介绍了网页抓取,并为抓取新式网络 继续阅读
Search Results for: python爬虫
查询到最新的12条
解析Python网络爬虫:核心技术、Scrapy框架、分布式爬虫
编程书籍推荐:解析Python网络爬虫:核心技术、Scrapy框架、分布式爬虫,由中国铁道出版社2018-08-01月出版,本书发行作者信息: 黑马程序员 著此次为第1次发行, 国际标准书号为:9787113246785,品牌为中国铁道出版社, 这本书采用平装开本为16开,附件信息:未知,纸张采为胶版纸,全书共有272页字数万 字,值得推荐的Python Book。此书内容摘要 网络爬虫是一种按照一定的规则,自动请求万维网网站并提取网络数据的程序或脚本,它可以代替人 继续阅读
Python 网络爬虫实战 [Web Crawler With Python]
Python 网络爬虫实战 [Web Crawler With Python],由清华大学出版社在2016-12-01月出版发行,本书编译以及作者信息为: 胡松涛 著,这是第1次发行, 国际标准书号为:9787302457879,品牌为清华大学, 这本书采用平装开本为16开,纸张采为胶版纸,全书共有294页,字数48万6000字,值得推荐。此书内容摘要《Python 网络爬虫实战》从Python的安装开始,详细讲解了Python从简单程序延伸到Python网络爬虫的全过程。《Python 网络爬 继续阅读
Python网络爬虫实战/清华科技大讲堂
Python网络爬虫实战/清华科技大讲堂,由清华大学出版社在2019-04-01月出版发行,本书编译以及作者信息为: 吕云翔,张扬 著,这是第1次发行, 国际标准书号为:9787302515920,品牌为清华大学出版社(TSINGHUA UNIVERSITY PRESS), 这本书采用平装开本为16开,纸张采为胶版纸,全书共有391页,字数43万3000字,值得推荐。 此书内容摘要本书介绍如何利用Python进行网络爬虫程序的开发,从Python语言的基本特性入手,详细介 继续阅读
Python爬虫开发 从入门到实战(微课版)
Python爬虫开发 从入门到实战(微课版)这本书,是由人民邮电出版社在2018-09-01月出版的,本书著作者是 谢乾坤 著,此次本版是第1次印刷发行, 国际标准书号(ISBN):9787115490995,品牌为人民邮电出版社, 这本书的包装是16开平装,所用纸张为胶版纸,全书共有未知页字数万字, 是一本非常不错的Python编程书籍。此书内容摘要 本书较为全面地介绍了定向爬虫的开发过程、各种反爬虫机制的破解方法和爬虫开发的相关技巧。全书共13章,包括绪论、Py 继续阅读
Python爬虫中Requests设置请求头Headers的方法
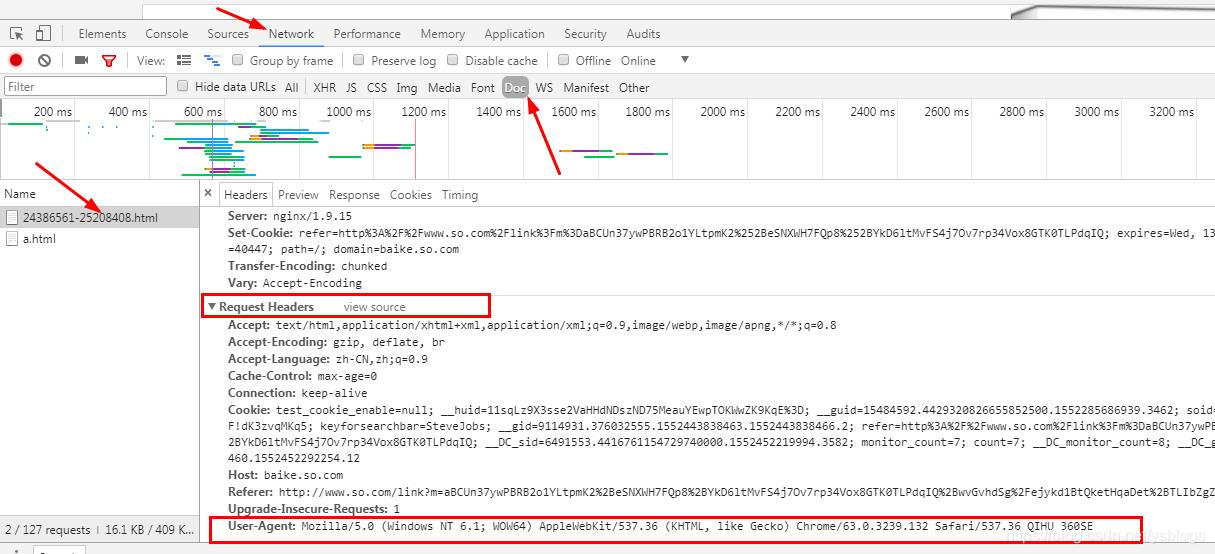
1、为什么要设置headers? 在请求网页爬取的时候,输出的text信息中会出现抱歉,无法访问等字眼,这就是禁止爬取,需要通过反爬机制去解决这个问题。 headers是解决requests请求反爬的方法之一,相当于我们进去这个网页的服务器本身,假装自己本身在爬取数据。 对反爬虫网页,可以设置一些headers信息,模拟成浏览器取访问网站 。 2、 headers在哪里找? 谷歌或者火狐浏览器,在网页面上点击:右键–> 继续阅读
Python爬虫 从小白到高手 Urllib
Urllib 1.什么是互联网爬虫? 如果我们把互联网比作一张大的蜘蛛网,那一台计算机上的数据便是蜘蛛网上的一个猎物,而爬虫程序就是一只小蜘蛛,沿着蜘蛛网抓取自己想要的数据 解释1:通过一个程序,根据Url(http://www.taobao.com)进行爬取网页,获取有用信息 解释2:使用程序模拟浏览器,去向服务器发送请求,获取响应信息 继续阅读
python爬虫(一)urllib.request库学习总结
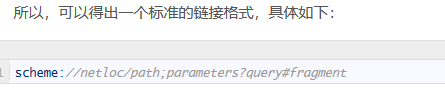
一.简单介绍 urllib库:是python的内置请求库,常用于网页的请求访问。 包括以下模块: urllib.request 请求模块 urllib.error 异常处理模块 urllib.parse url解析模块 urllib.robotparser robots.txt解析模块 二.实践操作 (1)针对含参数访问 import urllib.request import urllib.parse import 继续阅读
python实现新闻网站_Python 教你 4 行代码开发新闻网站通用爬虫
GNE(GeneralNewsExtractor)是一个通用新闻网站正文抽取模块,输入一篇新闻网页的 HTML, 输出正文内容、标题、作者、发布时间、正文中的图片地址和正文所在的标签源代码。GNE在提取今日头条、网易新闻、游民星空、 观察者网、凤凰网、腾讯新闻、ReadHub、新浪新闻等数百个中文新闻网站上效果非常出色,几乎能够达到100%的准确率。 ! 使用方式非常简单: from gne 继续阅读
Python对AES进行加密和解密的多种方法
本文是该专栏的第24篇,后面会持续分享python的各种干货知识,值得关注。 做过爬虫项目的同学,对AES加解密都有遇到过。 在密码学中,加密算法也分为双向加密和单向加密。单向加密包括MD5、SHA等摘要算法,它们是不可逆的。而双向加密包括对称加密和非对称加密,对称加密包括AES加密、DES加密等。需要注意的是,双向加密是可逆的,存在密文的密钥。AES算法是DES算法的替代者,也是现在最流行的加密算法之一。 那么AES又具体是什么呢?总的来说,AES加密标准也称为高级加密标准Rijnd 继续阅读
Python开发基础
推荐编程书籍:Python开发基础,由人民邮电出版社2018-12-01月出版发行,本书编译以及作者信息 为:戴歆,罗玉军 著,此次为第1次发行, 国际标准书号为:9787115494528,品牌为人民邮电出版社, 这本书采用平装开本为16开,纸张采为胶版纸,全书共有184页字数万字,是本Python 编程相关非常不错的书。此书内容摘要 Python语言是当前*活跃的开发语言之一,在数据科学领域、网络爬虫领域、Web开发领域、服务器自动化运维及游戏领域都有着非常广泛 继续阅读
Python爬虫实战之爬取某宝男装信息

知识点介绍 本次爬取用到的知识点有: 1. selenium 2. pymysql 3 pyquery 实现步骤 1. 分析目标网站 1. 打开某宝首页, 输入"男装"后点击"搜索", 则跳转到"男装"的搜索界面. 2. 空白处"右击"再点击"检查"审查网页元素, 点击"Network&quo 继续阅读