目录
- 1 接口调用
- 1.1 生成key
- 1.2 接口功能
- 1.2.1 图片生成 (image generation)
- 1.2.2 对话(chat)
- 1.2.3 中文纠错 (Chinese Spelling Correct)
- 1.2.4 关键词提取 (keyword extract)
- 1.2.5 抽取文本向量 (Embedding)
- 1.2.6 微调 (fine tune)
- 2 如何写好prompt
- 2.1分类任务
- 2.2 归纳总结
- 3.3 翻译
- 2.4 API接口多样性控制
- 3 实用资料
1 接口调用
我们可以用OpenAI 提供的API接口实现很多NLP的任务,还可以支持生成图像,提取embedding以及finetune的功能。接下来我们来看下具体怎么调用接口。
1.1 生成key
首先需要从网址:https://platform.openai.com/account/api-keys,生成我们的API key:
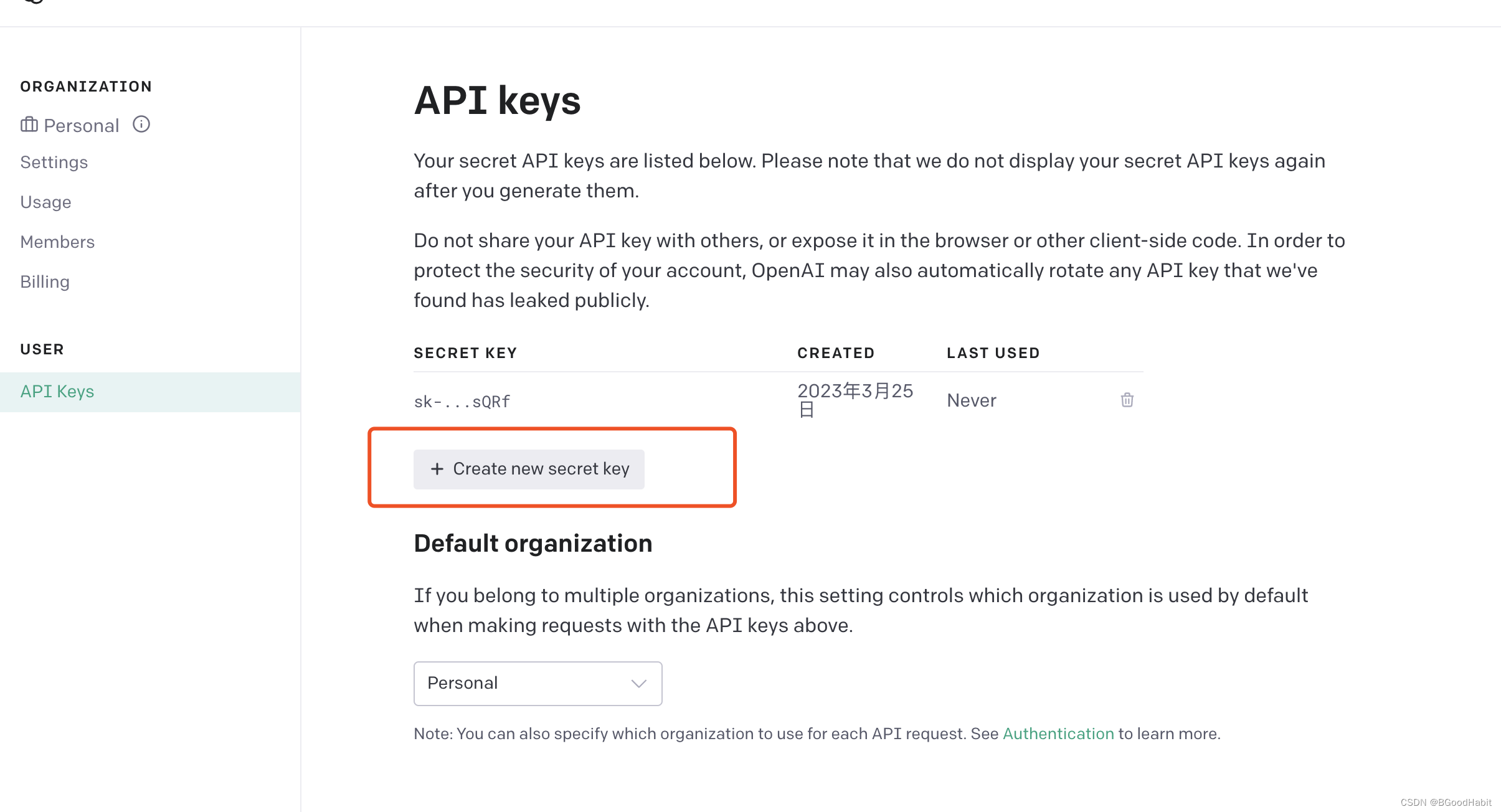
获得key后我们就可以调用API接口了。目前OpenAI 的 API 服务提供了一个免费的 API 计算单元 (ACU) 的额度,该额度可以用于测试和试用 OpenAI 提供的服务。免费的额度用完后,需要购买额外的 ACU 才能继续使用 OpenAI 的 API 服务。我们可以从Usage和Billing:https://platform.openai.com/account/usage 里去查看我们的免费额度以及进行额度充值:

1.2 接口功能
首先我们需要安装openai
pip install openai
安装好openai以及获得API key后,我们就可以调用接口了,首先我们来看下openai能够提供的模型有什么:
import openai
openai.api_key = "sk-Wljk3BVhN0VieGCwAzEXT3BlbkFJ*******"models = openai.Model.list()for model in models['data']:print(model['id'])
我们可以看出,目前提供的模型有如下:
接下来大概介绍一下我们应该怎样去调用接口,获取我们想要的结果。
1.2.1 图片生成 (image generation)
import openai
import json# 设置API密钥
openai.api_key = "sk-Wljk3BVhN0VieGCwAzEXT3BlbkFJ*******"def image_genaration(prompt):response = openai.Image.create(prompt=prompt,n=1,size="1024x1024")image_url = response['data'][0]['url']return image_urlif __name__=='__main__':prompt='a delicious dessert'result = image_genaration(prompt)print(result)prompt=‘a delicious dessert’, 其中返回url地址,我们将地址复制到浏览器中,打开看到如下图:

当prompt=‘母亲在厨房忙碌着’,OpenAI返回的效果图如下:

人物画像细节生成还不够逼真。来试一试中国的古诗词效果,
prompt=‘踏花归去马蹄香’

马蹄上应该画出一些蝴蝶🦋来表达马蹄的花香味啊,不太满意~😞
1.2.2 对话(chat)
api接口调用代码如下所示:
import openai
import json# 设置API密钥
openai.api_key = "sk-Wljk3BVhN0VieGCwAzEXT3BlbkFJ*******"
def chat(prompt):response = openai.ChatCompletion.create(model="gpt-3.5-turbo",messages=[{"role": "user", "content":prompt}]
)answer = response.choices[0].message.contentreturn answerif __name__=='__main__':prompt='人口最多的国家'result = chat(prompt)print(result)
结果如下:

1.2.3 中文纠错 (Chinese Spelling Correct)
我们可以通过合理的写prompt,基于问答形式,让gpt-3.5做NLP任务。比如对中文纠错,我们可以这样写prompt,让chagpt能够做纠错NLP任务。如下所示:
def correct():prompt="改正错词输出正确句子:\n\n我在京东电商平台买了苹果耳几和华为体脂称" #建议prompt: 改正错词输出正确句子:\n\n input_sentenceresponse = openai.ChatCompletion.create(model="gpt-3.5-turbo",messages=[{"role": "user", "content":prompt}]
)answer = response.choices[0].message.contentreturn answerif __name__=='__main__':result = correct()print(result)
结果如下:

1.2.4 关键词提取 (keyword extract)
def keyword():prompt="对下面内容识别2个关键词,每个词字数不超过3个字:\n\n齐选汽车挂件车内挂饰车载后视镜吊坠高档实心黄铜玉石出入平安保男女 红流苏-玉髓平安扣" #建议prompt: 对下面内容识别n个关键词,每个词字数不超过m个字:\n\n input dataresponse = openai.ChatCompletion.create(model="gpt-3.5-turbo",messages=[{"role": "user", "content":prompt}]
)answer = response.choices[0].message.contentreturn answerif __name__=='__main__':result = keyword()print(result)

对于不同的prompt,输出的结果差异也较大。所以对于具体的任务场景,我们需要尝试不同的prompt, 根据结果的反馈,不断的调整和优化prompt,从而得到更加准确的结果。
1.2.5 抽取文本向量 (Embedding)
def embedding():content = '苹果手机'response = openai.Embedding.create(model="text-embedding-ada-002",input=content
)answer = response.data[0].embeddingreturn answerif __name__=='__main__':result = embedding()print(len(result))print(result)
得到结果如下:

是一个1536维度的向量,我们可以基于文本的向量去做很多任务,比如计算两个向量的余弦值,计算相似性分值等。
1.2.6 微调 (fine tune)
openAI提供了接口可以用我们自己的数据进行fine tune,得到适应我们自己业务场景的新模型。假如我们需要训练一个适应我们自己领域知识的聊天机器人,我们可以按照下面流程来做fine tune。
- 数据准备
我们可以先把数据转成csv格式,需提供prompt列和对应的completion列,其中prompt相当于问题,completion就是对应的答案,如下是我们要用来fine tune模型的result.csv训练样本内容显示:

然后我们可以用openAI提供的数据处理工具对数据转成json格式的文件
openai tools fine_tunes.prepare_data -f result.csv
执行完后,我们会得到一个对应的json文件:result_prepared.jsonl
- 模型微调训练
接下来我们就可以用已有的模型 (ada, babbage, curie, davinci) 进行fine tune,官方给出的具体可以用来做微调的模型主要如下:

首先需要指定我们自己的API key:
export OPENAI_API_KEY="sk-Wljk3BVhN0VieGCwAzEX*********"
然后开始训练:
openai api fine_tunes.create -t result_prepared.jsonl -m ada
在这里用我们自己的数据result_prepared.jsonl,基于base model: ada模型提交fine tune任务。提交后会返回给我们一个JOB ID,通过这个job id我们可以跟进模型在远程服务器训练情况:
openai api fine_tunes.follow -i ft-sWKDNnTmUyOGEdpvbAOvEaZt
我们可以看到结果如下:
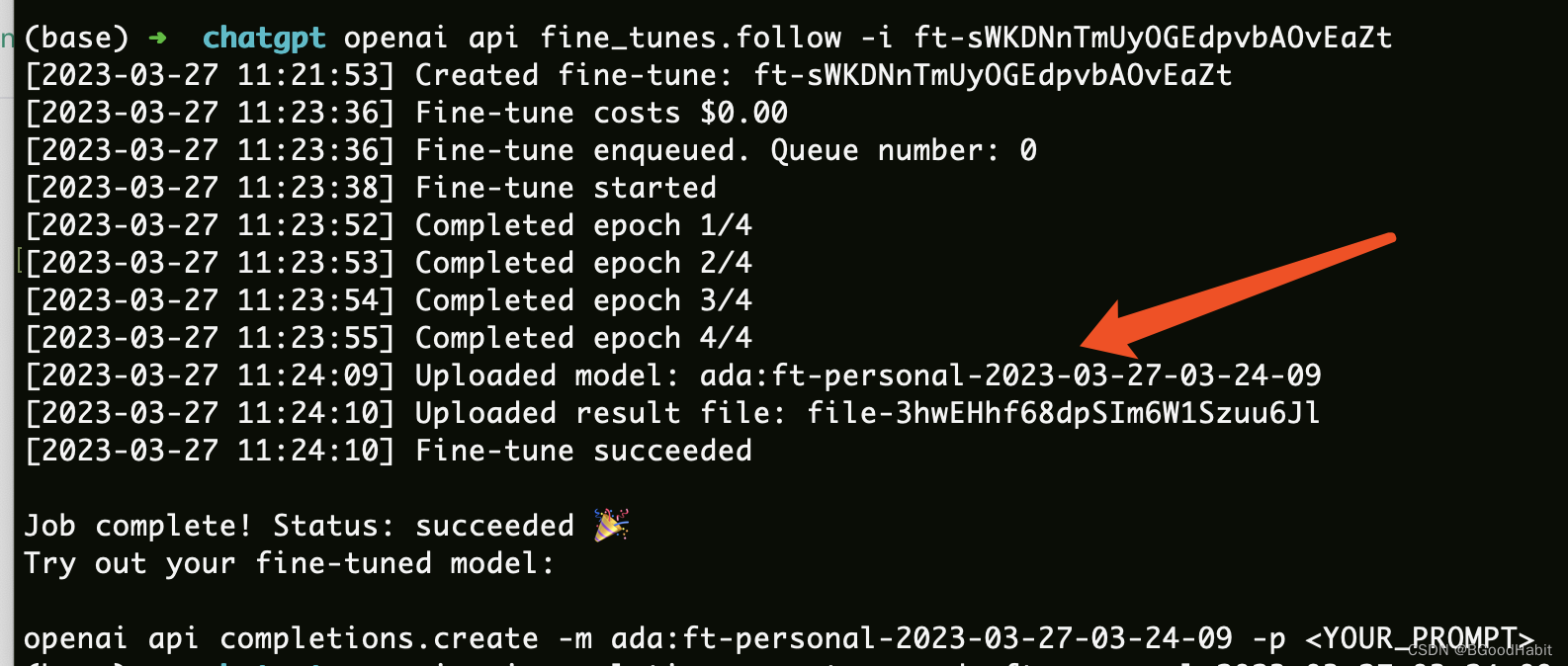
可以看到我们的模型训练好了模型名称叫做:ada:ft-personal-2023-03-27-03-24-09,然后我们就可以试用我们训练好的模型看效果了,测试如下:
openai api completions.create -m ada:ft-personal-2023-03-27-03-24-09 -p <YOUR_PROMPT>
其中<YOUR_PROMPT>写入我们要测试的问题就好。
现在我们可以去远程服务器上查看下我们fine tune好的模型是否已经有了:
models = openai.Model.list()
发现有了刚刚fine tune的模型:

对于分类,实体识别等任务,OPNAI官网也提供了如何做处理数据,让模型做fine tune,详情可以参考官网https://platform.openai.com/docs/introduction/overview
2 如何写好prompt
prompt如何表达,对于chatgpt返回的答案会差异很大,通过prompt正确的表达问题,chatgpt才会返回更合适的结果。通过自己这些天的尝试以及官网给的提示,感受就是在写prompt时候,可以通过说明,例子,限制条件,修饰词等具体表达问题,这样chatgpt会给出更加精准的答案。接下来,我们对几种常见的任务,prompt应用如何写。
2.1分类任务
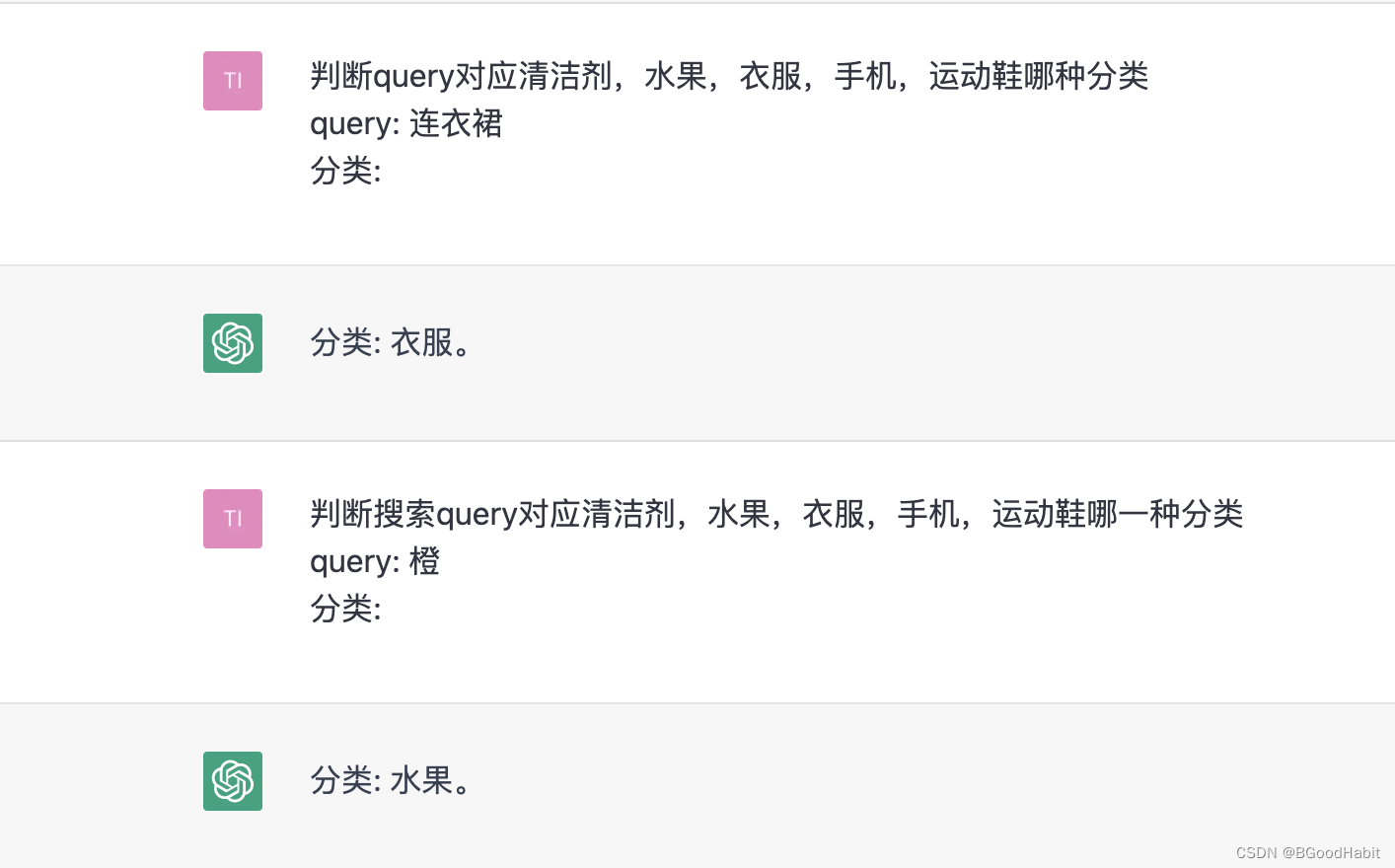
我们可以对prompt这么构造:
判断content属于A,B,C,D哪一种分类
content: detail
分类:
对应的查询结果如下:
2.2 归纳总结
提供了非常强大能力,能够基于学到的广泛知识,给出问题解决方案,合理的建议,实施步骤,商业计划,人物描写等等。所以我们可以合理写prompt,更有意思的答案。
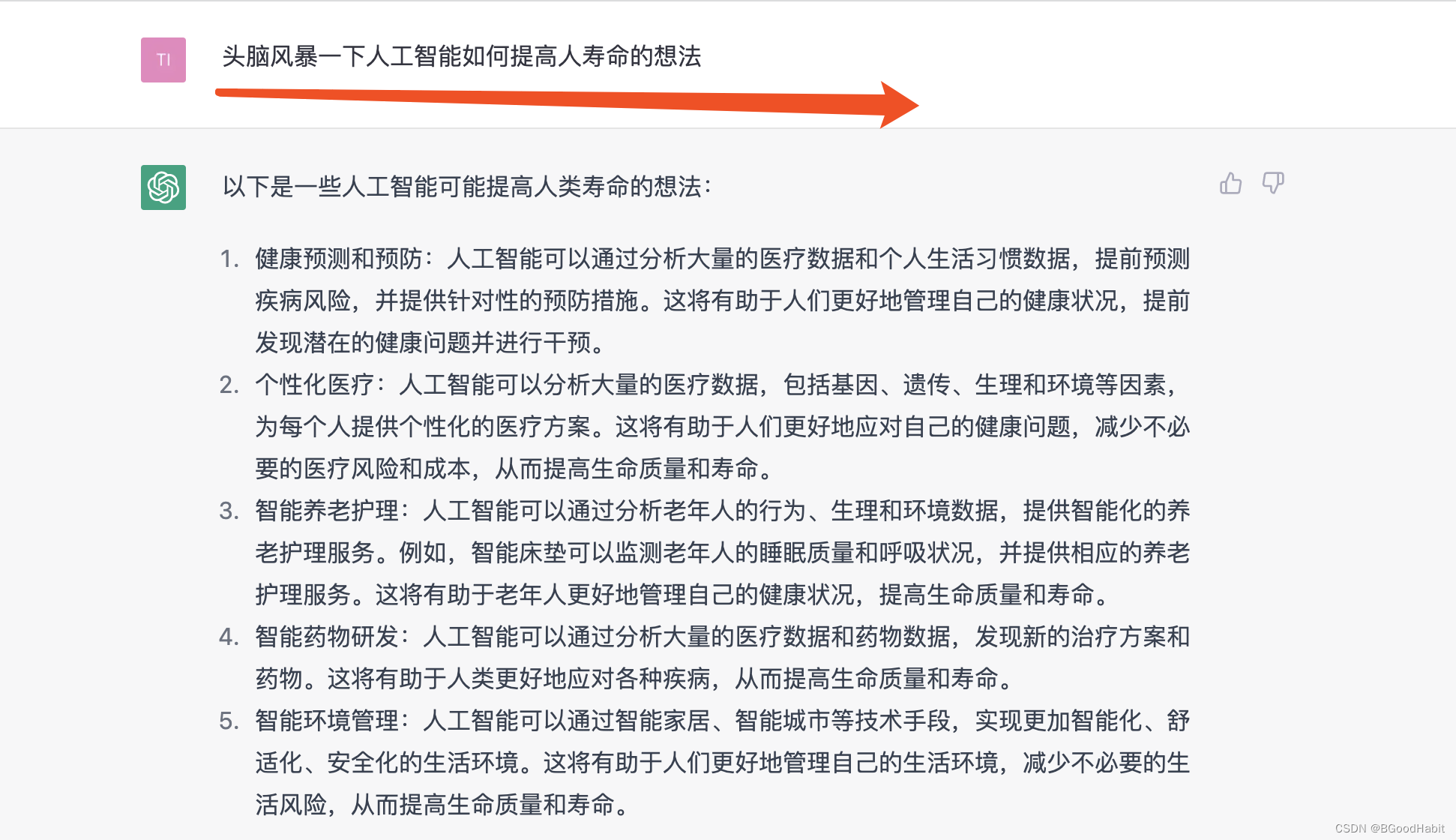
哈哈,看起来不够大胆,于是进一步发问:

给出的这些答案果然更加激动人心。
3.3 翻译
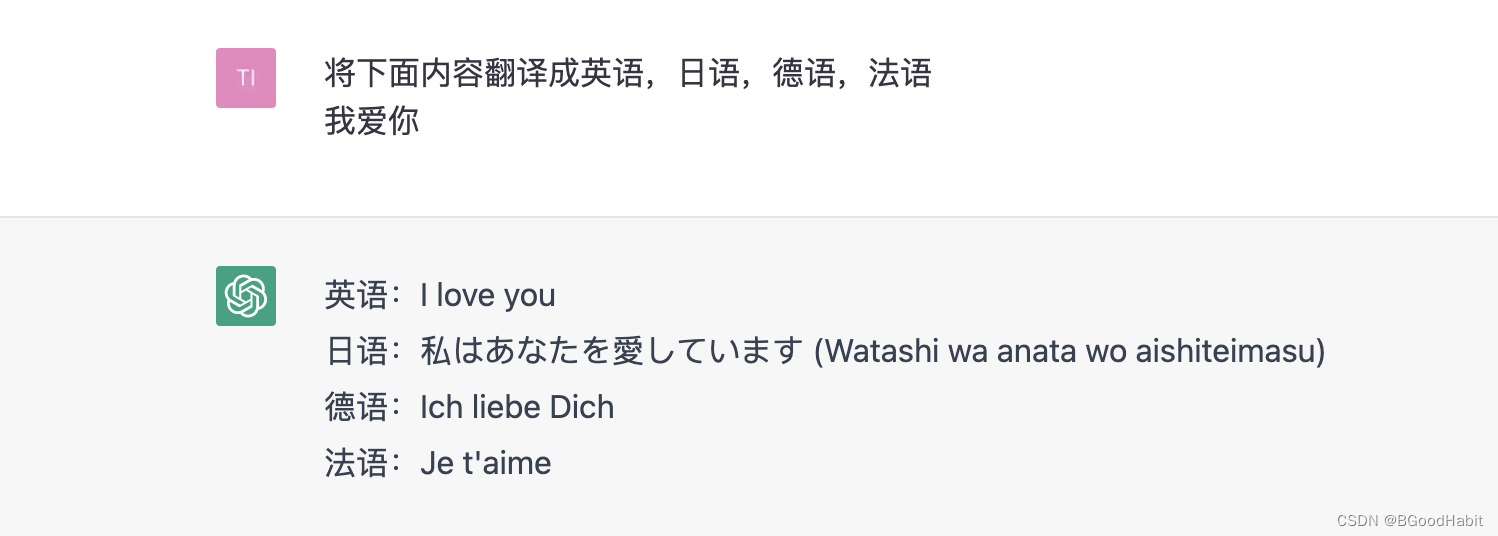
我们可以将一种语言翻译成我们大多数其他语言。对于翻译任务,我们只需要写prompt表达我们的意愿就是:
将下面内容翻译成英语,日语,德语
content
2.4 API接口多样性控制
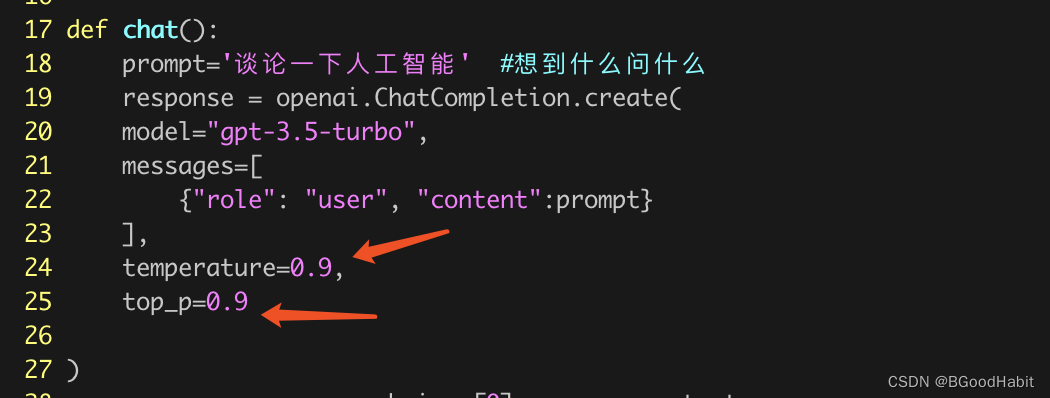
在调用API接口的时候,我们可以通过设置两个参数=='temperature’和’top_p’来控制生成文本的多样性和可控度==。当temperature较高时,生成的文本会更加随机和多样化,而当temperature较低时,生成的文本会更加保守和可控。top_p参数用于控制生成文本的可控度,它会限制模型生成文本时可以选择的token的数量。具体来说,当top_p越低时,模型只考虑概率分布中累计概率最高的一部分token,而忽略其他低概率的token。这样一来,生成的文本就更加可控,因为只有那些最可能的token才会被考虑。而当top_p越高的时候,生成的文本可能会更加灵活和多样,因为模型会考虑更多的低概率token。每次调用的时候,我们可以设置这两个参数:
3 实用资料
大模型训练平台:https://github.com/hpcaitech/ColossalAI
相关资料:中文精选资源清单
本文链接:https://my.lmcjl.com/post/6656.html
4 评论