最近ChatGPT很火,国内清华也发布了ChatGLM,于是想在云平台上实现一下小型的ChatGLM。目前准备在趋动云这个平台上试试ChatGLM-6B-int8。
目前ChatGLM-6B-int8显存最少需要10G
可以参考GitHub - THUDM/ChatGLM-6B: ChatGLM-6B: An Open Bilingual Dialogue Language Model | 开源双语对话语言模型![]() https://github.com/THUDM/ChatGLM-6B
https://github.com/THUDM/ChatGLM-6B

第一步:创建一个项目
选择官方pytorch:1.12.1
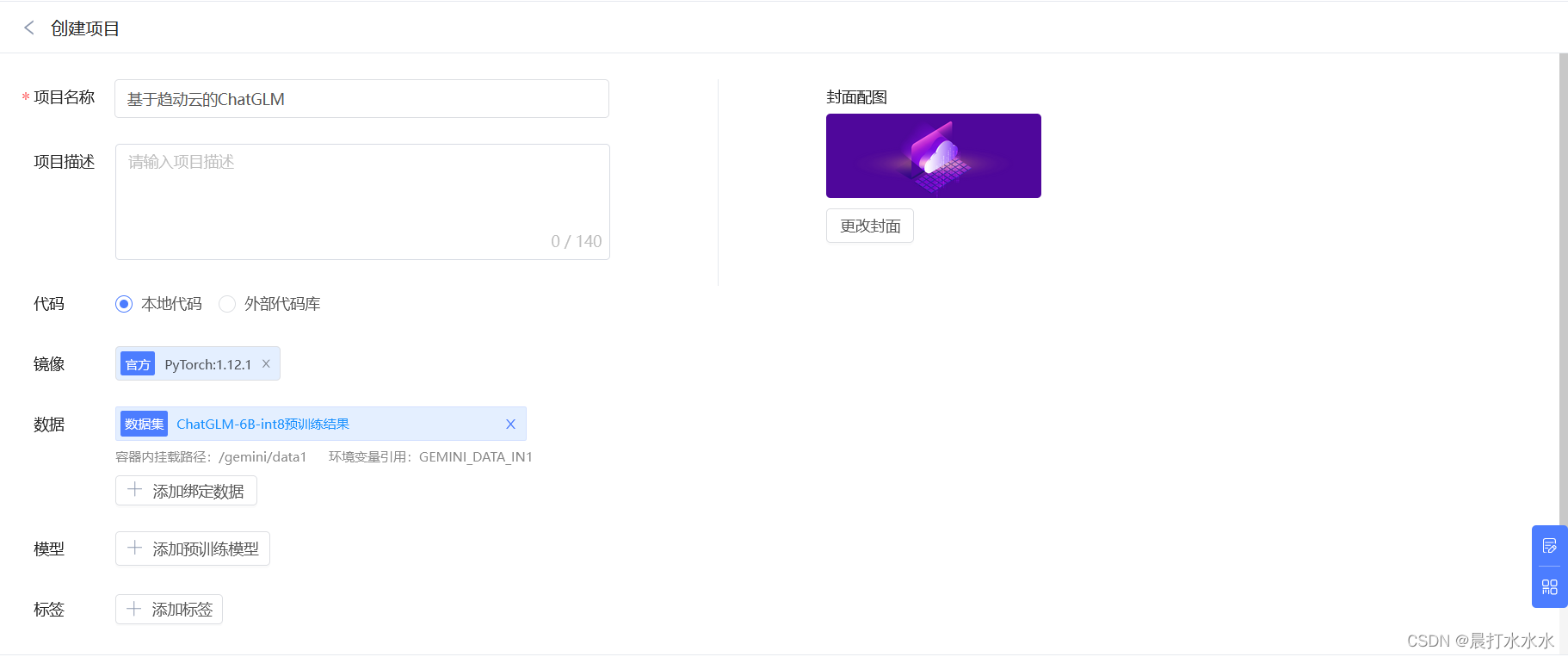
数据集选择“公开”里面的ChatGLM-6B-int8预训练结果

弹出上传代码 界面,选择暂不上传就行
目前我已将项目公开,大家可以再公开这里找到

进入项目后,选择“开发”,然后选择显存大于9G的配置,我选的是B1.large(B1.medium运存稍微有点不够),将最长运行时间选为“不限制”(这样你就可以手动开关项目啦~),最后点“确定”,等待开发环境运行即可!!!

第二步:搭建环境
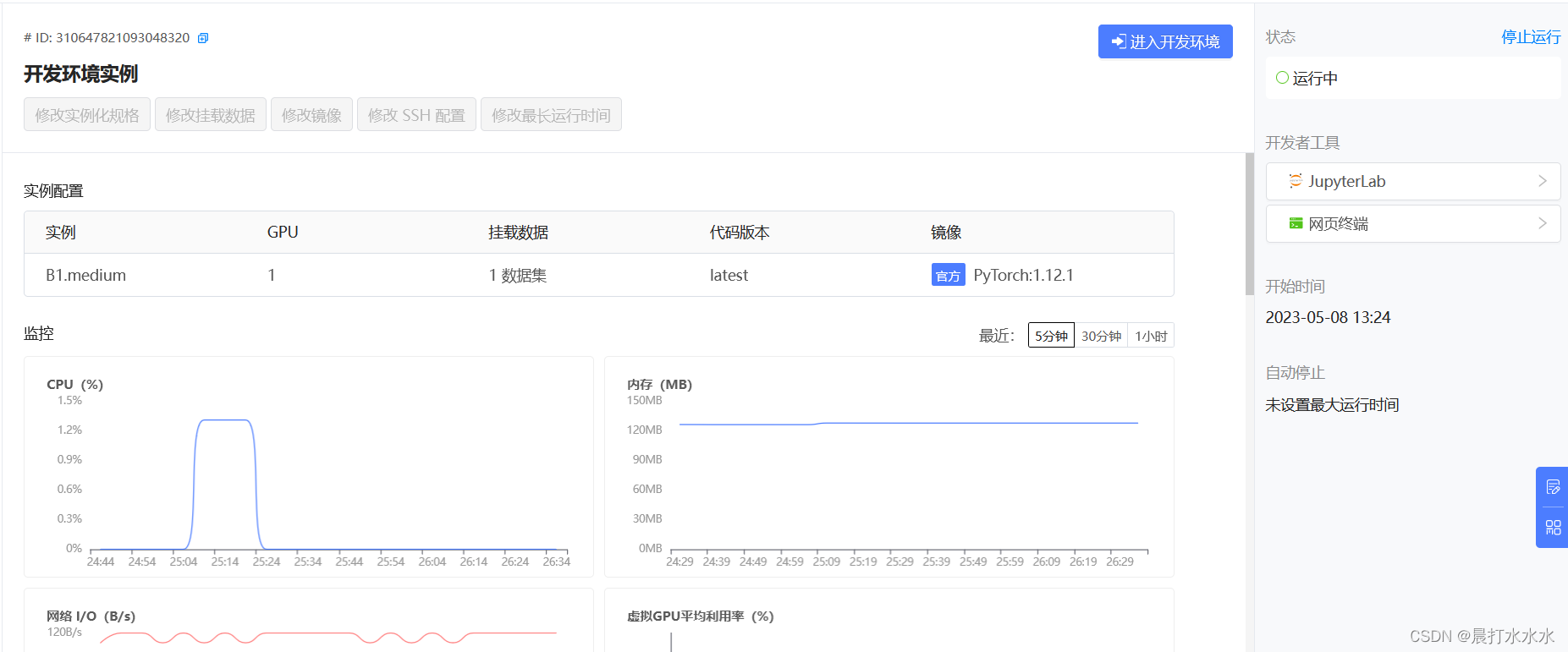
有图显示表面可以用了,点“进入开发环境”
创建一个.ipynb文件
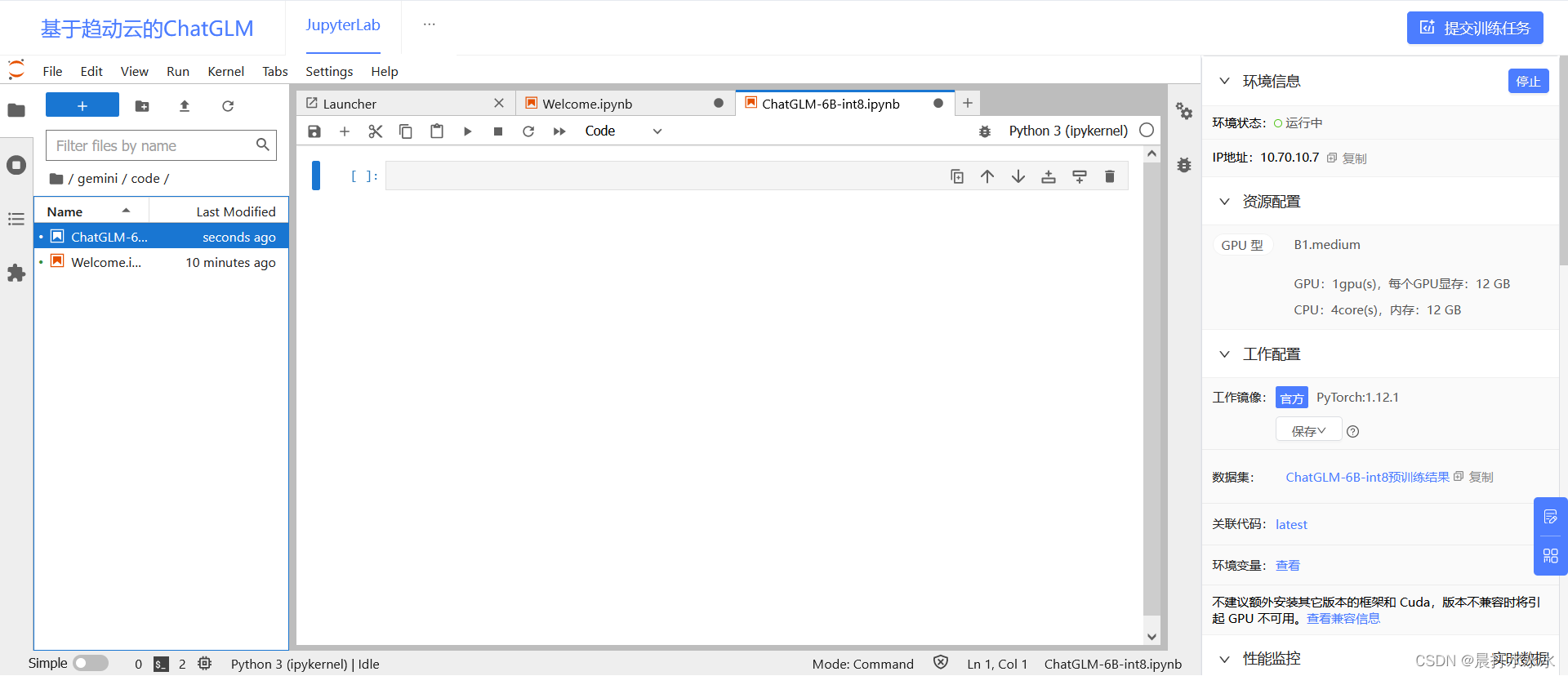
在省略号这里点“网页终端”
进入终端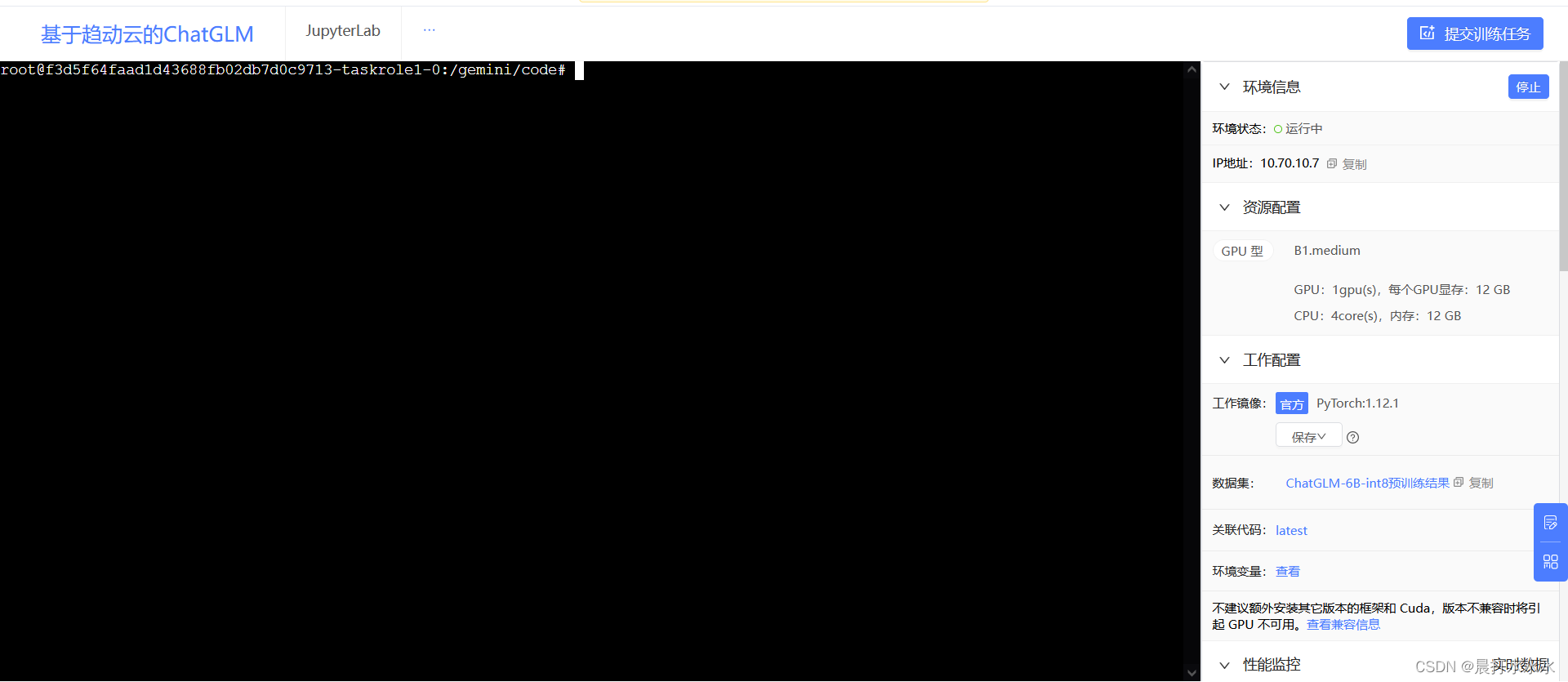
在github找到ChatGLM,点击requirements.txt查看环境GitHub - THUDM/ChatGLM-6B: ChatGLM-6B: An Open Bilingual Dialogue Language Model | 开源双语对话语言模型![]() https://github.com/THUDM/ChatGLM-6B
https://github.com/THUDM/ChatGLM-6B
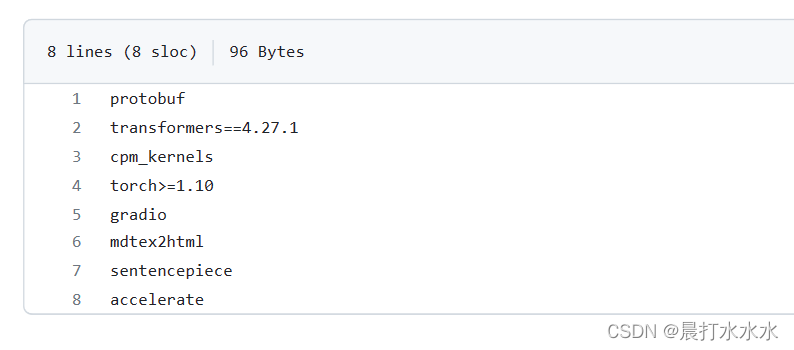
我是在pypi里面下了源文件,装在新建的/download文件夹里面了

然后一个个安装文件即可 (这里只演示一个)

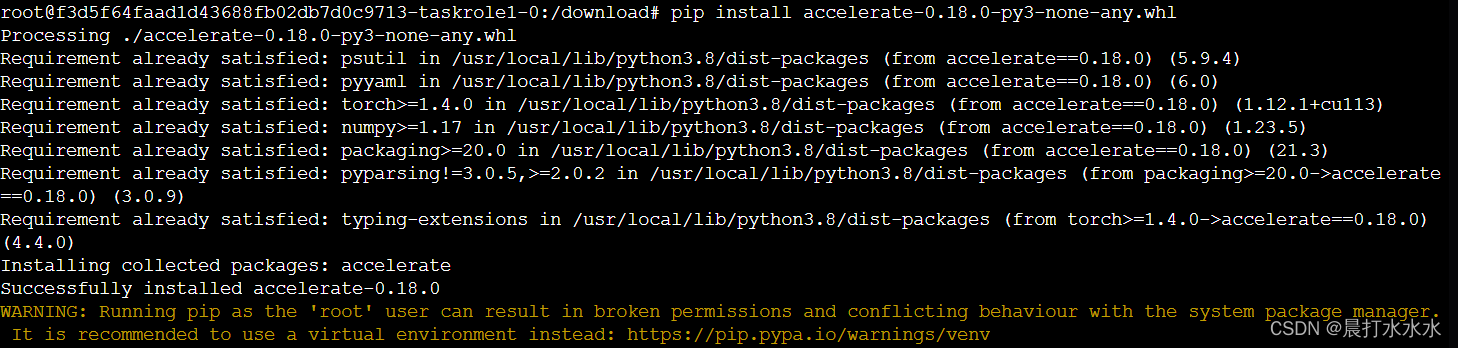
在公开项目里面所有环境我已经配好,大家可以直接调用
第三步:运行代码
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("/gemini/data-1/ChatGLM-6B-int8", trust_remote_code=True)
model = AutoModel.from_pretrained("/gemini/data-1/ChatGLM-6B-int8", trust_remote_code=True).half().cuda()
model = model.eval()
response, history = model.chat(tokenizer, "你好", history=[])
print(response)
继续输入
response, history = model.chat(tokenizer, "武汉有什么好玩的地方?", history=history)
print(response)
可以看到在趋动云平台部署ChatGLM-6B-int8非常成功!!!
本文链接:https://my.lmcjl.com/post/5107.html
4 评论