目录
- 1、Stream API
- 2、ParallelStreams执行原理
- 3、ParallelStreams注意事项
前言:
并行编程势不可挡,Java从1.7开始就提供了Fork/Join 支持并行处理。java1.8 进一步加强。
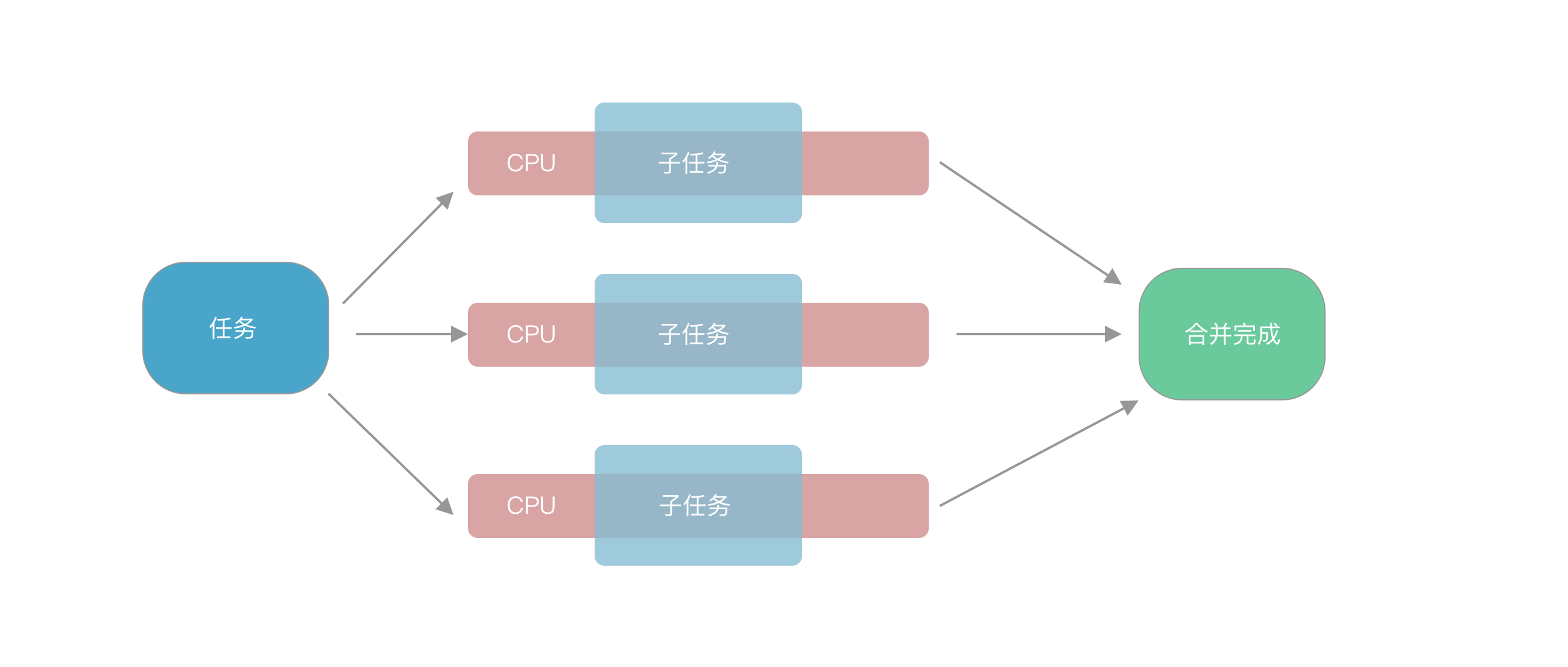
并行处理就是将任务拆分子任务,分发给多个处理器同时处理,之后合并。
1、Stream API
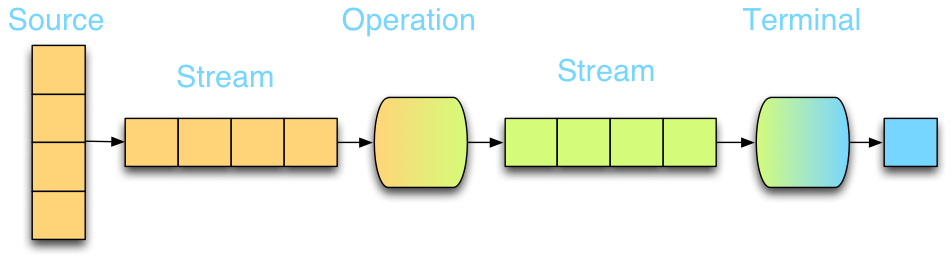
Java 8 引入了许多特性,Stream API是其中重要的一部分。区别 InputStream OutputStream,Stream API 是处理对象流而不是字节流。
执行原理如下,流分串行和并行两种执行方式
// 串行执行流 stream().filter(e -> e > 10).count(); // 并行执行流 .parallelStream().filter(e -> e > 10).count()
2、ParallelStreams执行原理
并行执行时,java将流划分为多个子流,分散在不同CPU并行处理,然后进行合并。
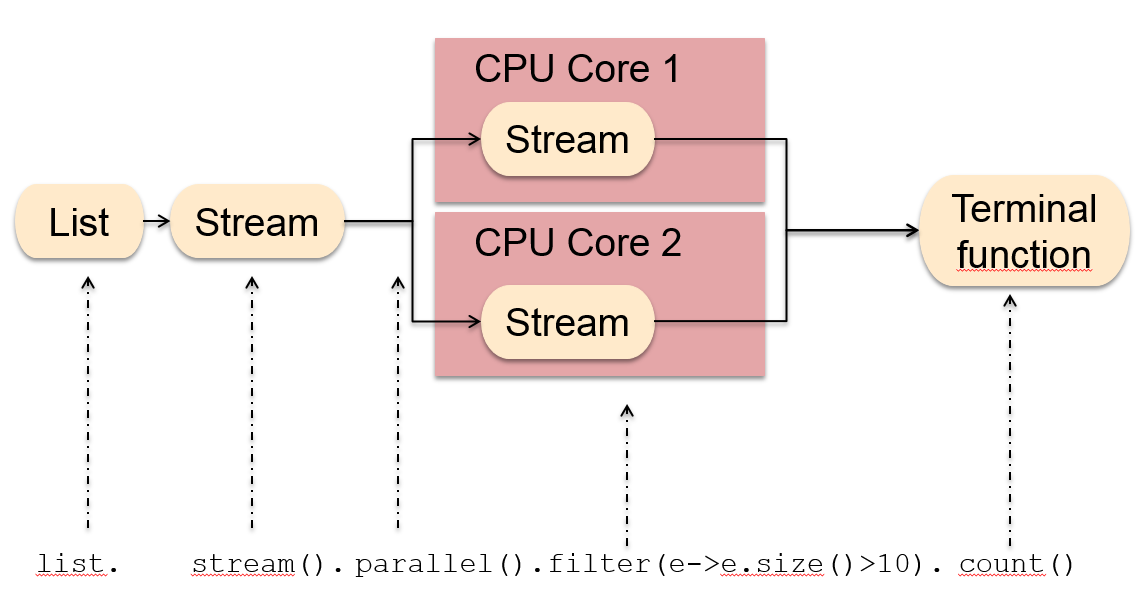
并行一定比串行更快吗?这不一定,取决于两方面条件:
- 处理器核心数量,并行处理核心数越多自然处理效率会更高。
- 处理的数据量越大,优势越强。这也很好理解,比如十个人干一个人就能完成的活儿会比它自己干更便宜?
3、ParallelStreams注意事项
使用并行流时,不要使用collectors.groupingBy,collectors.toMap,替代为
collectors.groupingByConcurrent , collectors.toConcurrentMap,或直接使用串行流。
原因,并行流执行时,通过操作Key来合并多个map的操作比较昂贵。详细大家可以查看官网介绍。

https://docs.oracle.com/javase/tutorial/collections/streams/parallelism.html#concurrent_reduction
Map<String, List<Person>> byGender = roster .stream() .collect(Collectors.groupingBy(Person::getGender)); ConcurrentMap<String, List<Person>> byGender = roster .parallelStream() .collect(Collectors.groupingByConcurrent(Person::getGender));
ParallelStreams 默认使用 ForkJoinPool.commonPool()线程池。
注意:默认情况下,你写的 ParallelStreams 都是通过该线程池调度执行,整个应用程序都共享这个线程池。
看一个例子,我们查询一批新闻数据,可以利用并行化来处理远程新闻下载。
public List<News> queryNews(Stream<String> ids) {
return ids.parallel()
.map(this::getNews) // 网络操作,新闻下载
.collect(toList());
}
因为是网络操作,存在很多不确定性,假如某个任务运行时间较长,导致线程池资源占据,阻塞其它线程,这样就阻止了其他的并行流任务正常进行。
如果解决这个问题的其中一种方式,进行线程池隔离。那么如何自定义并行流的线程池呢?
ForkJoinPool 构造参数我们默认设置为CPU核心数。
ForkJoinPool customThreadPool = new ForkJoinPool(4); long actualTotal = customThreadPool .submit(() -> roster.parallelStream().reduce(0, Integer::sum)).get();
总结:
Java 1.8 提供的Stream API简化了代码,很好用。不过在使用过程中应该注意以上问题。
到此这篇关于Java8 中的并行流 ParallelStreams的文章就介绍到这了,更多相关Java8 ParallelStreams内容请搜索服务器之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持服务器之家!
原文链接:https://www.onlythinking.com/2020/06/05/%E4%BD%A0%E5%9C%A8%E4%BD%BF%E7%94%A8java-8-parallel-streams-%E5%90%97%EF%BC%9F/
本文链接:https://my.lmcjl.com/post/7779.html
4 评论