前言
随着『GPT4多模态/Microsoft 365 Copilot/Github Copilot X/ChatGPT插件』的推出,绝大部分公司的技术 产品 服务,以及绝大部分人的工作都将被革新一遍
- 类似iPhone的诞生 大家面向iOS编程 有了App Store
- 现在有了ChatGPT插件/GPT应用商店,以后很多公司 很多人面向GPT编程(很快技术人员分两种,一种懂GPT,一种不懂GPT)
然ChatGPT/GPT4基本不可能开源了,而通过前两篇文章《从LLaMA到Alpaca、BELLE、ChatLLaMA和ColossalChat》可知,国内外各大公司、研究者推出了很多类ChatGPT开源项目,比如LLaMA、BLOOM
本文则侧重
- ChatGLM
- 垂直领域的ChatGPT等,比如ChatDoctor
毕竟,虽然LLaMA这些模型的通用能力很强,然应用在垂直领域的话,还得再加上各个垂直方向的预料加以训练,由此便诞生了以LLaMA为底层模型的比如ChatDoctor,且可以预见的是,垂直领域的ChatGPT,今年会诞生一大批
第五部分 国内的GLM与类ChatGPT项目ChatGLM-6B
5.1 GLM: General Language Model Pretraining with Autoregressive Blank Infilling
在2022年上半年,当时主流的预训练框架可以分为三种:
- autoregressive,自回归模型的代表是单向的GPT,本质上是一个从左到右的语言模型,常用于无条件生成任务(unconditional generation),缺点是无法利用到下文的信息
- autoencoding,自编码模型是通过某个降噪目标(如掩码语言模型,简单理解就是通过挖洞,训练模型做完形填空的能力)训练的语言编码器,如双向的BERT、ALBERT、RoBERTa、DeBERTa
自编码模型擅长自然语言理解任务(natural language understanding tasks),常被用来生成句子的上下文表示,缺点是不适合生成任务 - encoder-decoder,则是一个完整的Transformer结构,包含一个编码器和一个解码器,以T5、BART为代表,常用于有条件的生成任务 (conditional generation)
细致来说,T5的编码器中的注意力是双向,解码器中的注意力是单向的,因此可同时应用于自然语言理解任务和生成任务。但T5为了达到和RoBERTa和DeBERTa相似的性能,往往需要更多的参数量
这三种预训练模型各自称霸一方,那么问题来了,可否结合三种预训练模型,以成天下之一统?这便是2022年5月发表的这篇论文《GLM: General Language Model Pretraining with Autoregressive Blank Infilling》的出发点,它提出了GLM架构(这是张义策关于GLM论文的解读之一,下面三小节的内容主要参考自该篇解读)
5.1.1 如何将生成模型GPT和掩码语言模型BERT结合在一起
首先,考虑到三类预训练模型的训练目标
- GPT的训练目标是从左到右的文本生成
- BERT的训练目标是对文本进行随机掩码,然后预测被掩码的词
- T5则是接受一段文本,从左到右的生成另一段文本
为了大一统,我们必须在结构和训练目标上兼容这三种预训练模型。如何实现呢?文章给出的解决方法
- 结构上,只需要GLM中同时存在单向注意力和双向注意力即可
在原本的Transformer模型中,这两种注意力机制是通过修改attention mask实现的
当attention_mask是全1矩阵的时候,这时注意力是双向的
当attention_mask是三角矩阵的时候(如下图),注意力就是单向
类似地,我们可以在只使用Transformer编码器的情况下,自定义attention mask来兼容三种模型结构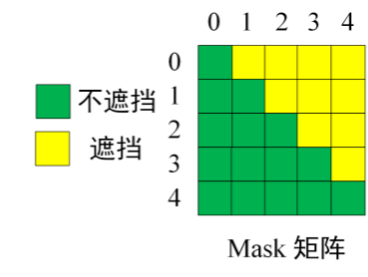
- 训练目标上,这篇文章提出一个自回归空格填充的任务(Autoregressive Blank Infifilling),来兼容三种预训练目标
自回归填充有些类似掩码语言模型,首先采样输入文本中部分片段,将其替换为[MASK]标记,然后预测[MASK]所对应的文本片段,与掩码语言模型不同的是,预测的过程是采用自回归的方式
具体来说,
当被掩码的片段长度为1的时候,空格填充任务等价于掩码语言建模,类似BERT
4.1.2 如何理解GLM的自回归空格填充任务
假设原始的文本序列为

- 我们要根据第一个
- 我们从开始标记
在GLM中,位置向量有两个,一个 用来记录Part A中的相对顺序,一个 用来记录被掩码的文本片段(简称为Part B)中的相对顺序 - 此外,还需要通过自定义自注意掩码(attention mask)来达到以下目的:
需要说明的是,Part B包含所有被掩码的文本片段,但是文本片段的相对顺序是随机打乱的
5.1.3 GLM的预训练和微调
作者使用了两个预训练目标来优化GLM,两个目标交替进行:
- 文档级别的预测/生成:从文档中随机采样一个文本片段进行掩码,片段的长度为文档长度的50%-100%
- 句子级别的预测/生成:从文档中随机掩码若干文本片段,每个文本片段必须为完整的句子,被掩码的词数量为整个文档长度的15%
尽管GLM是BERT、GPT、T5三者的结合,但是在预训练时,为了适应预训练的目标,作者还是选择掩码较长的文本片段,以确保GLM的文本生成能力,并在微调的时候将自然语言理解任务也转化为生成任务,如情感分类任务转化为填充空白的任务
- 输入:{Sentence},prompt:It is really

此外,模型架构层面,除了整体基于Transformer之外
- 重新排列了层归一化和残差连接的顺序
- 针对token的输出预测使用单一线性层
- 用GeLU替换ReLU激活函数
5.2 GLM-130B:国内为数不多的可比肩GPT3的大模型之一
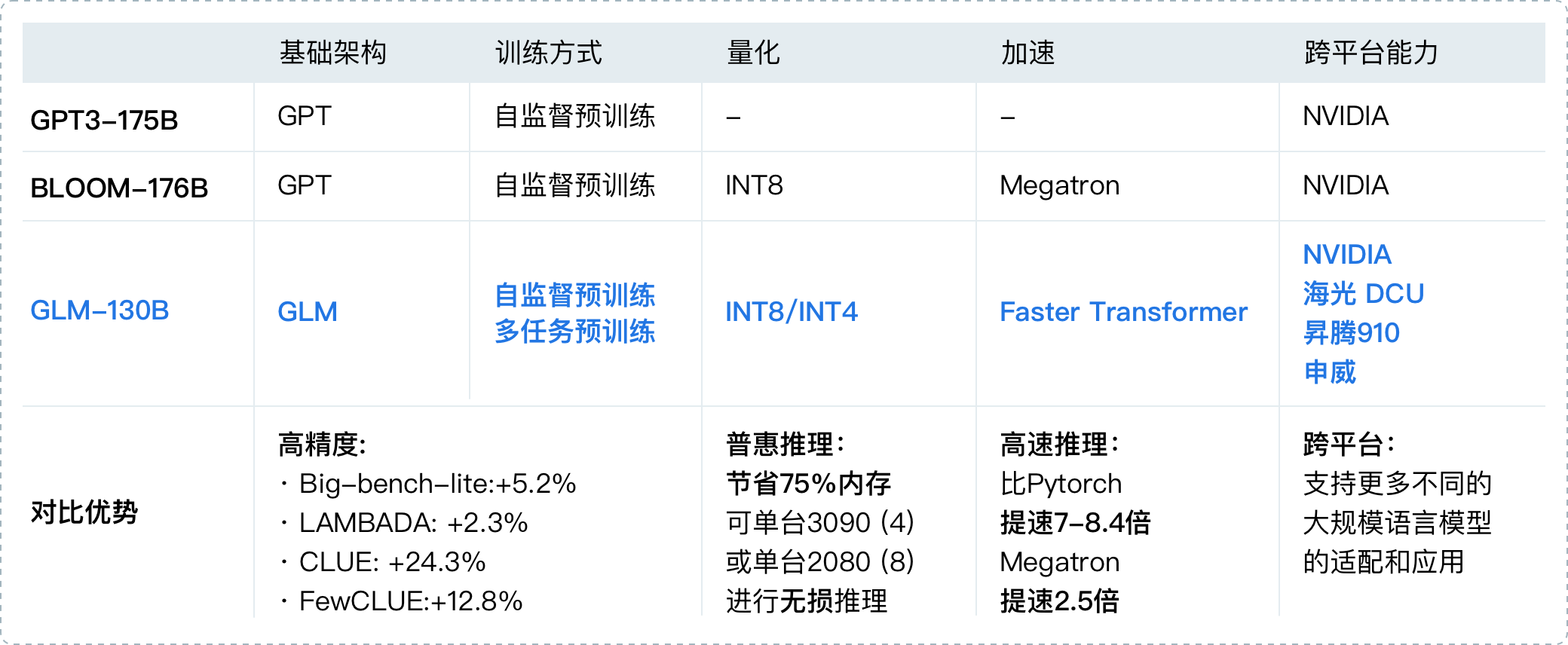
2022年8月,清华背景的智谱AI基于GLM框架,正式推出拥有1300亿参数的中英双语稠密模型 GLM-130B(论文地址、代码地址,论文解读之一,GLM-130B is trained on a cluster of 96 DGX-A100 GPU (8×40G) servers with a 60-day,可以较好的支持2048个token的上下文窗口)
其在一些任务上的表现优于GPT3-175B,是国内与2020年5月的GPT3在综合能力上差不多的模型之一(即便放到23年年初也并不多),这是它的一些重要特点
5.3 类ChatGPT开源项目ChatGLM-6B的训练框架与部署步骤
5.3.1 ChatGLM-6B的训练框架
ChatGLM-6B(介绍页面、代码地址),是智谱 AI 开源、支持中英双语的对话语言模型,其
- 基于General Language Model(GLM)架构,具有62亿参数,无量化下占用显存13G,INT8量化级别下支持在单张11G显存的 2080Ti 上进行推理使用(因为INT8下占用显存10G,而INT4下最低只需 6GB显存)
这里需要解释下的是,INT8量化是一种将深度学习模型中的权重和激活值从32位浮点数(FP32)减少到8位整数(INT8)的技术。这种技术可以降低模型的内存占用和计算复杂度,从而减少计算资源需求,提高推理速度,同时降低能耗
量化的过程通常包括以下几个步骤:
1 量化范围选择:确定权重和激活值的最小值和最大值
2 量化映射:根据范围将32位浮点数映射到8位整数
3 反量化:将8位整数转换回浮点数,用于计算 - ChatGLM-6B参考了 ChatGPT 的训练思路,在千亿基座模型GLM-130B中注入了代码预训练,通过监督微调(Supervised Fine-Tuning)、反馈自助(Feedback Bootstrap)、人类反馈强化学习(Reinforcement Learning from Human Feedback)等方式等技术实现人类意图对齐,并针对中文问答和对话进行优化
- 最终经过约 1T 标识符的中英双语训练,生成符合人类偏好的回答
虽尚有很多不足(比如因为6B的大小限制,导致模型的记忆能力、编码、推理能力皆有限),但在6B这个参数量级下不错了,部署也非常简单,我七月在线的同事朝阳花了一两个小时即部署好了(主要时间花在模型下载上,实际的部署操作很快)
5.3.2 ChatGLM-6B的部署步骤
以下是具体的部署过程
- 硬件配置
本次实验用的七月的GPU服务器(专门为七月集/高/论文/VIP学员配置的),显存大小为16G的P100,具体配置如下:
CPU&内存:28核(vCPU)112 GB
操作系统:Ubuntu_64
GPU:NVIDIA Tesla P100
显存:16G - 配置环境
建议最好自己新建一个conda环境
pip install -r requirements.txt
特别注意torch版本不低于1.10(这里安装的1.10),transformers为4.27.1
torch的安装命令可以参考pytorch官网:https://pytorch.org/
这里使用的pip命令安装的,命令如下
pip install torch==1.10.0+cu102 torchvision==0.11.0+cu102 torchaudio==0 - 下载项目仓库
git clone https://github.com/THUDM/ChatGLM-6B
cd ChatGLM-6B - 下载ChatGLM-6B模型文件
具体而言,较大的8个模型文件可以从这里下载(下载速度快):清华大学云盘
其他的小文件可以从这里下载(点击红框的下载按钮即可):THUDM/chatglm-6b · Hugging Face

注意这里都下载在了/data/chatglm-6b下,在后面执行代码的时候需要将文件中的模型文件路径改为自己的 - 推理与部署
可运行的方式有多种
特别注意:运行代码前请检查模型文件路径是否正确,这里均改为了/data/chatglm-6b
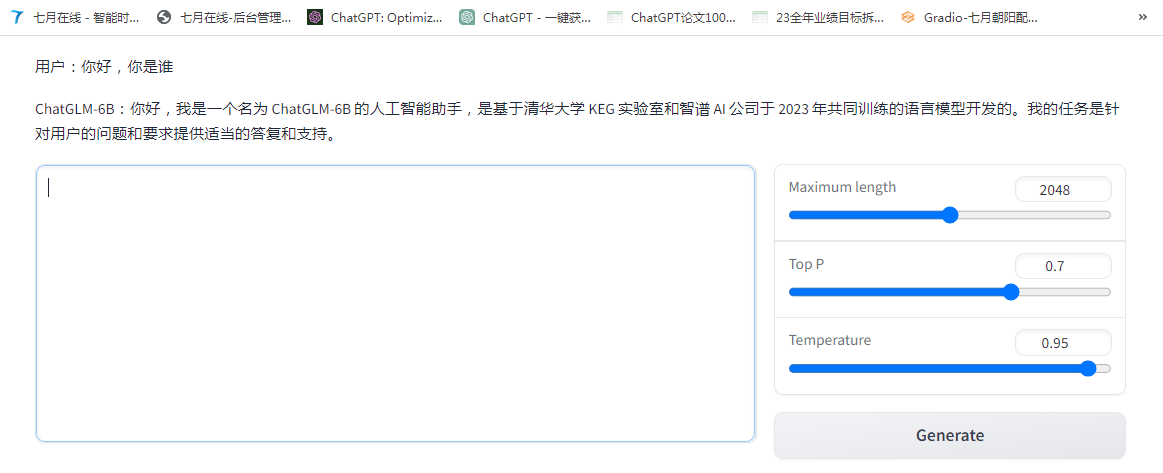
代码运行demo
运行之后 如下截图所示from transformers import AutoTokenizer, AutoModel tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True) model = AutoModel.from_pretrained("/data/chatglm-6b", trust_remote_code=True).half().cuda() model = model.eval() response, history = model.chat(tokenizer, "你好", history=[]) print(response) response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history) print(response)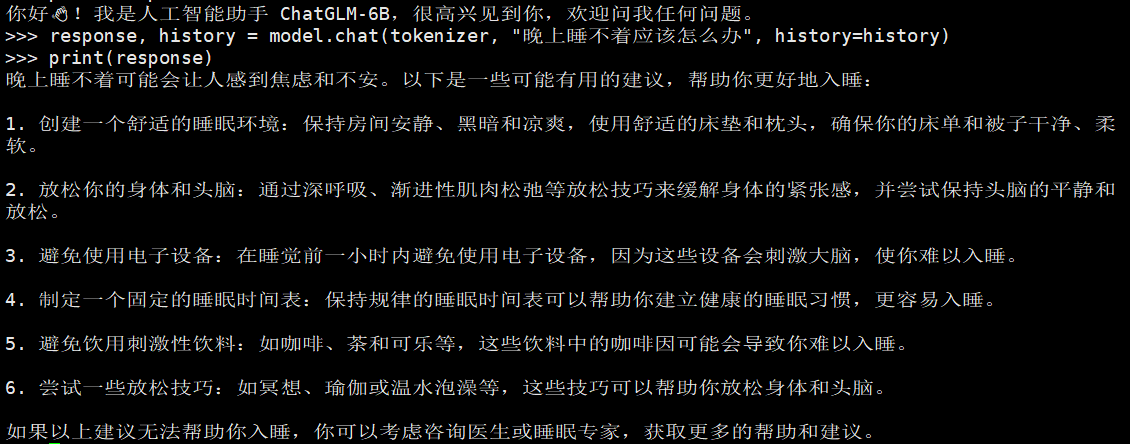
命令行 Demo
运行仓库中 cli_demo.py:
python cli_demo.py
程序会在命令行中进行交互式的对话,在命令行中输入指示并回车即可生成回复,输入 clear 可以清空对话历史,输入 stop 终止程序
基于Gradio的网页版demo
运行web_demo.py即可(注意可以设置share=True,便于公网访问):python web_demo.py(注意运行前确认下模型文件路径)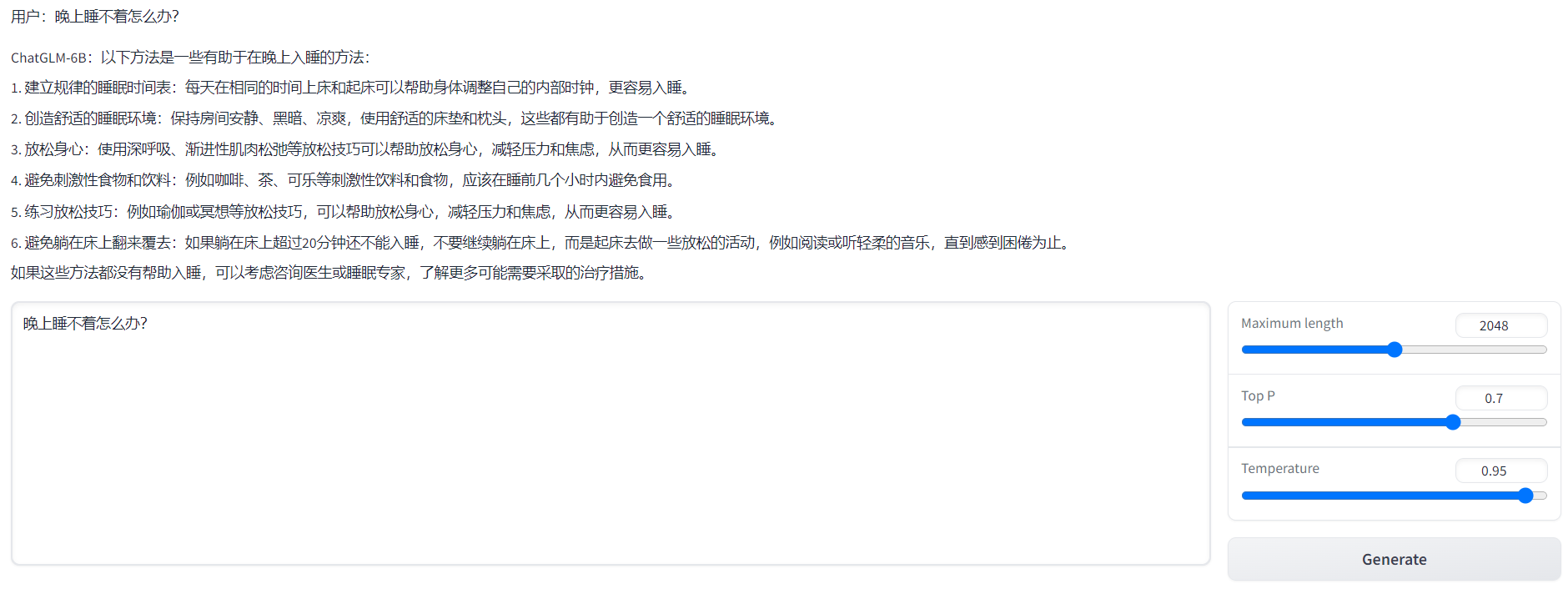
基于streamlit网页版 Demo
pip install streamlit
pip install streamlit-chat
streamlit run web_demo2.py --server.port 6006(可以将6006端口放出,便于公网访问)
默认情况下,模型以 FP16 精度加载,运行上述代码需要大概 13GB 显存。如果显存有限,还可以考虑模型量化,目前支持4/8 bit 量化
此外,据介绍,GLM团队正在内测130B参数的ChatGLM,相信从6B到130B,效果应该能提升很多
5.4 如何微调ChatGLM-6B:针对各种数据集通过LoRA或P-Tuning v2
5.4.1 通过Stanford Alpaca的52K数据集基于LoRA(PEFT库)微调ChatGLM-6B
从上文可知,Stanford Alpaca的52K数据集是通过Self Instruct方式提示GPT3对应的API产生的指令数据,然后通过这批指令数据微调Meta的LLaMA 7B
而GitHub上的这个微调ChatGLM-6B项目(作者:mymusise),则基于Stanford Alpaca的52K数据集通过LoRA(low-rank adaptation)的方式微调ChatGLM-6B
如上一篇文章所说,Huggingface公司推出的PEFT(Parameter-Efficient Fine-Tuning)库便封装了LoRA这个方法,具体而言,通过PEFT-LoRA微调ChatGLM-6B的具体步骤如下
- 第一步,配置环境与准备
先下载项目仓库
git clone https://github.com/mymusise/ChatGLM-Tuning.git
创建一个python3.8的环境
conda create -n torch1.13 python==3.8
conda activate torch1.13
根据requirements.txt配置环境
pip install bitsandbytes==0.37.1
安装1.13,cuda11.6(torch官网命令)
pip install torch==1.13.1+cu116 torchvision==0.14.1+cu116 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu116
安装其他的包
遇到冲突问题:icetk 0.0.5 has requirement protobuf<3.19, but you have protobuf 3.19.5.pip install accelerate==0.17.1 pip install tensorboard==2.10 pip install protobuf==3.19.5 pip install transformers==4.27.1 pip install icetk pip install cpm_kernels==1.0.11 pip install datasets==2.10.1 pip install git+https://github.com/huggingface/peft.git # 最新版本 >=0.3.0.dev0
最后装了3.18.3的protobuf,发现没有问题
模型文件准备
模型文件在前面基于ChatGLM-6B的部署中已经准备好了,注意路径修改正确即可 - 第二步,数据准备
项目中提供了数据,数据来源为 Stanford Alpaca 项目的用于微调模型的52K数据,数据生成过程可详见:https://github.com/tatsu-lab/stanford_alpaca#data-release
alpaca_data.json,包含用于微调羊驼模型的 52K 指令数据,这个 JSON 文件是一个字典列表,每个字典包含以下字段:
instruction: str,描述了模型应该执行的任务,52K 条指令中的每一条都是唯一的
input: str,任务的可选上下文或输入。例如,当指令是“总结以下文章”时,输入就是文章,大约 40% 的示例有输入
output: str,由 text-davinci-003 生成的指令的答案
示例如下:[{"instruction": "Give three tips for staying healthy.","input": "","output": "1.Eat a balanced diet and make sure to include plenty of fruits and vegetables. \n2. Exercise regularly to keep your body active and strong. \n3. Get enough sleep and maintain a consistent sleep schedule."},{"instruction": "What are the three primary colors?","input": "","output": "The three primary colors are red, blue, and yellow."}, ... ] - 第三步,数据处理
运行 cover_alpaca2jsonl.py 文件
python cover_alpaca2jsonl.py \ --data_path data/alpaca_data.json \ --save_path data/alpaca_data.jsonl \
处理后的文件示例如下:
运行 tokenize_dataset_rows.py 文件,注意:修改tokenize_dataset_rows中的model_name为自己的文件路径 :/data/chatglm-6b {"text": "### Instruction:\nGive three tips for staying healthy.\n\n### Response:\n1.Eat a balanced diet and make sure to include plenty of fruits and vegetables. \n2. Exercise regularly to keep your body active and strong. \n3. Get enough sleep and maintain a consistent sleep schedule.\nEND\n"} {"text": "### Instruction:\nWhat are the three primary colors?\n\n### Response:\nThe three primary colors are red, blue, and yellow.\nEND\n"}python tokenize_dataset_rows.py \--jsonl_path data/alpaca_data.jsonl \--save_path data/alpaca \--max_seq_length 200 \--skip_overlength \ - 第四步,微调过程
注意:运行前修改下finetune.py 文件中模型路径:/data/chatglm-6b
Nvidia驱动报错(如没有可忽略)python finetune.py \--dataset_path data/alpaca \--lora_rank 8 \--per_device_train_batch_size 6 \--gradient_accumulation_steps 1 \--max_steps 52000 \--save_steps 1000 \--save_total_limit 2 \--learning_rate 1e-4 \--fp16 \--remove_unused_columns false \--logging_steps 50 \--output_dir output;
遇到问题,说明Nvidia驱动太老,需要更新驱动
UserWarning: CUDA initialization: The NVIDIA driver on your system is too old (found version 10020). Please update your GPU driver by downloading and installing a new version from the URL: http://www.nvidia.com/Download/index.aspx Alternatively, go to: https://pytorch.org to install a PyTorch version that has been compiled with your version of the CUDA driver. (Triggered internally at ../c10/cuda/CUDAFunctions.cpp:109.)
解决:更新驱动即可,参考:Ubuntu 18.04 安装 NVIDIA 显卡驱动 - 知乎
BUG REPORT报错
参考:因为peft原因,cuda10.2报错 · Issue #108 · mymusise/ChatGLM-Tuning · GitHub
CUDA SETUP: CUDA version lower than 11 are currently not supported for LLM.int8()
考虑安装11以上的cudatooklit,参考下面链接,安装cudatooklit11.3(因为Ubuntu系统版本的原因,不能装11.6的)
Ubuntu16.04 安装cuda11.3+cudnn8.2.1 - 知乎
cudatooklit下载地址:
CUDA Toolkit 11.3 Downloads | NVIDIA 开发者
运行代码前先执行下面命令:
内存不够,考虑将per_device_train_batch_size设为1export LD_LIBRARY_PATH=/usr/local/cuda-11.3/lib64:$LD_LIBRARY_PATH export CUDA_HOME=/usr/local/cuda-11.3:$CUDA_HOME export PATH=/usr/local/cuda-11.3/bin:$PATH
报错:RuntimeError: expected scalar type Half but found Floatpython finetune.py \--dataset_path data/alpaca \--lora_rank 8 \--per_device_train_batch_size 1 \--gradient_accumulation_steps 1 \--max_steps 52000 \--save_steps 1000 \--save_total_limit 2 \--learning_rate 1e-4 \--fp16 \--remove_unused_columns false \--logging_steps 50 \--output_dir output;
https://github.com/mymusise/ChatGLM-Tuning/issues?q=is%3Aissue+is%3Aopen+RuntimeError%3A+expected+scalar+type+Half+but+found+Float
解决方法:
一种是,不启用fp16, load_in_8bit设为True,可以运行,但loss为0;
一种是,启用fp16, load_in_8bit设为False,不行,应该还是显存不够的问题,至少需要24G左右的显存
5.4.2 ChatGLM团队:通过ADGEN数据集基于P-Tuning v2微调ChatGLM-6B
此外,ChatGLM团队自身也出了一个基于P-Tuning v2的方式微调ChatGLM-6B的项目:ChatGLM-6B 模型基于 P-Tuning v2 的微调
P-Tuning v2(代码地址,论文地址)意义在于:将需要微调的参数量减少到原来的 0.1%,再通过模型量化、Gradient Checkpoint 等方法,最低只需要 7GB 显存即可运行
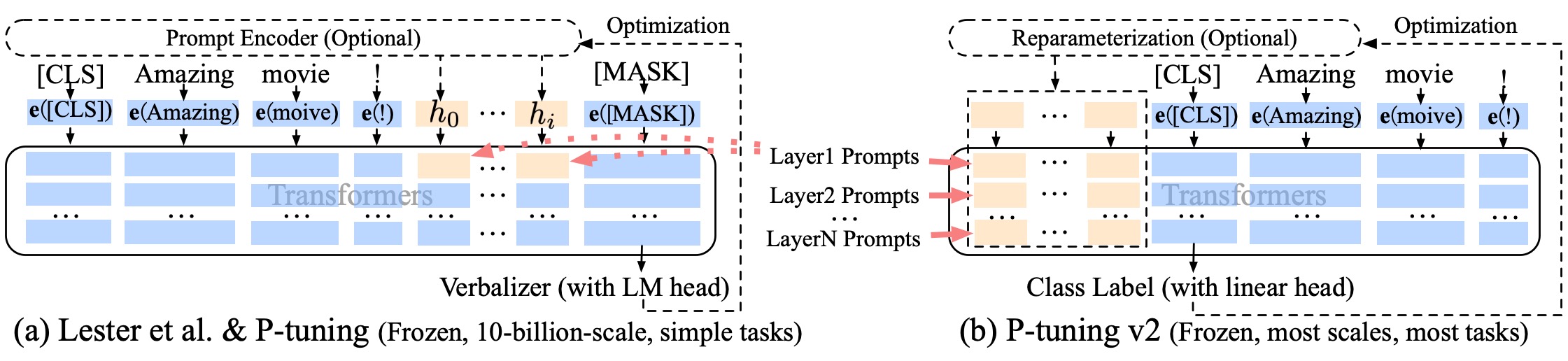
那具体怎么通过P-Tuning v2微调ChatGLM-6B呢,具体步骤如下:
- 第一步,配置环境与准备
地址:ChatGLM-6B/ptuning at main · THUDM/ChatGLM-6B · GitHub
安装以下包即可,这里直接在torch1.13的conda环境下安装的pip install rouge_chinese nltk jieba datasets - 第二步,模型文件准备
模型文件在前面基于ChatGLM-6B的部署中已经准备好了,注意路径修改正确即可
特别注意:如果你是之前下载的可能会报错,下面有详细的错误及说明 - 第三步,数据准备
ADGEN数据集的任务为根据输入(content)生成一段广告词(summary)
{
"content": "类型#上衣*版型#宽松*版型#显瘦*图案#线条*衣样式#衬衫*衣袖型#泡泡袖*衣款式#抽绳",
"summary": "这件衬衫的款式非常的宽松,利落的线条可以很好的隐藏身材上的小缺点,穿在身上有着很好的显瘦效果。领口装饰了一个可爱的抽绳,漂亮的绳结展现出了十足的个性,配合时尚的泡泡袖型,尽显女性甜美可爱的气息。"
}
从Google Drive 或者 Tsinghua Cloud 下载处理好的 ADGEN数据集,将解压后的AdvertiseGen目录放到本 ptuning 目录下即可 - 第四步,微调过程
修改train.sh文件
去掉最后的 --quantization_bit 4
注意修改模型路径,THUDM/chatglm-6b修改为/data/chatglm-6b
如果你也是在云服务器上运行,建议可以加上nohup后台命令,以免断网引起训练中断的情况修改后train.sh文件如下:
执行命令,开始微调PRE_SEQ_LEN=8 LR=1e-2CUDA_VISIBLE_DEVICES=0 nohup python -u main.py \--do_train \--train_file AdvertiseGen/train.json \--validation_file AdvertiseGen/dev.json \--prompt_column content \--response_column summary \--overwrite_cache \--model_name_or_path /data/chatglm-6b \--output_dir output/adgen-chatglm-6b-pt-$PRE_SEQ_LEN-$LR \--overwrite_output_dir \--max_source_length 64 \--max_target_length 64 \--per_device_train_batch_size 1 \--per_device_eval_batch_size 1 \--gradient_accumulation_steps 16 \--predict_with_generate \--max_steps 3000 \--logging_steps 10 \--save_steps 1000 \--learning_rate $LR \--pre_seq_len $PRE_SEQ_LEN \>> log.out 2>&1 &
bash train.sh
如果报错:'ChatGLMModel' object has no attribute 'prefix_encoder'(如没有可忽略)
解决方案:需要更新 THUDM/chatglm-6b at main 里面的几个py文件(重新下载下这几个文件就可以了)
微调过程占用大约13G的显存
微调过程loss变化情况
微调完成后,output/adgen-chatglm-6b-pt-8-1e-2路径下会生成对应的模型文件,如下(这里生成了3个):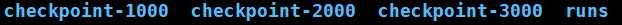
- 第五步,推理过程
只需要在加载模型的位置修改成微调后的路径即可
将 evaluate.sh 中的 CHECKPOINT 更改为训练时保存的 checkpoint 名称,运行以下指令进行模型推理和评测:
改这一行即可:--model_name_or_path ./output/$CHECKPOINT/checkpoint-3000
bash evaluate.sh
评测指标为中文 Rouge score 和 BLEU-4,生成的结果保存在
./output/adgen-chatglm-6b-pt-8-1e-2/generated_predictions.txt
我们可以对比下微调前后的效果
以命令行 Demo为例,只需修改cli_demo.py中的模型路径为:ptuning/out/adgen-chatglm-6b-pt-8-1e-2/checkpoint-3000,运行 cli_demo.py即可:
python cli_demo.py
用以下数据为例:
Input: 类型#上衣*材质#牛仔布*颜色#白色*风格#简约*图案#刺绣*衣样式#外套*衣款式#破洞 Label: 简约而不简单的牛仔外套,白色的衣身十分百搭。衣身多处有做旧破洞设计,打破单调乏味,增加一丝造型看点。衣身后背处有趣味刺绣装饰,丰富层次感,彰显别样时尚。 这件上衣的材质是牛仔布,颜色是白色,风格是简约,图案是刺绣,衣样式是外套,衣款式是破洞。
用户:根据输入生成一段广告词,输入为:类型#上衣*材质#牛仔布*颜色#白色*风格#简约*图案#刺绣*衣样式#外套*衣款式#破洞。
Output[微调前]:
Output[微调后]:
总结:建议使用官方提供的基于P-Tuning v2微调ChatGLM-6B的方式对自己的数据进行微调
第六部分 ChatDoctor:基于LLaMA或BART做增强
Github上有一个ChatDoctor项目(ChatDoctor: A Medical Chat Model Fine-tuned on LLaMA Model using Medical Domain Knowledge)
核心思想就是基于Meta 的LLaMA进行各种微调,具体而言主要是以下三个步骤
- 首先使用 Stanford Alpaca 提供的 52K instruction-following 数据训练了一个通用的对话模型
对于数据集构建这块,用的instruction, input, output的结构
instruction 可以是类似'你现在的身份是医生,请以这个身份跟我对话',input,output 就是问答对
实际微调时,使用的 6 个 A*100 GPU 进行,持续时间为 30 分钟
训练过程中使用的超参数如下:总的batch size 192,学习率(learning rate)设为2e-5,总共3个epoch,最大序列长度512个token,warmup ratio 0.03,无权重衰减
————————————————
至于斯坦福团队微调LLaMA 7B所用的52K指令数据咋来的呢,
说来也有趣,它是通过Self-Instruct『Self-Instruct是来自华盛顿大学Yizhong Wang等22年12月通过这篇论文《SELF-INSTRUCT: Aligning Language Model with Self Generated Instructions》提出的』提示GPT3的API拿到的
具体可以看下上一篇文章的2.2节:类ChatGPT开源项目的部署与微调 - 通过ChatGPT GenMedGPT-5k和疾病数据库生成的『患者和医生之间的5K对话数据集』,再次微调模型
- 通过HealthCareMagic-200k的患者和医生之间的真实对话进行第三轮微调
- 通过icliniq-26k的患者和医生之间的真实对话进行第四轮微调
当然,也有业内研究者基于BART-base,且利用他们自己公司的数据,微调出他们版本的ChatDoctor(截取自邓老师朋友圈)

// 待更..
本文链接:https://my.lmcjl.com/post/8410.html
4 评论