论文地址:https://arxiv.org/pdf/2112.09332.pdf
一、简介
NLP\text{NLP}NLP中一个日益严峻的挑战是long-form question-answering(LFQA)\text{long-form question-answering(LFQA)}long-form question-answering(LFQA),其需要一个很长的答案来回答开放域的问题。LFQA\text{LFQA}LFQA系统有可能成为人们了解世界的主要方式之一,但是目前还落后于人类的表现。现有的工作倾向于该任务的两个核心组件:信息检索与合成。
本文利用这些组件的现有解决方案:将文档检索交给Microsoft Bing Web Search API\text{Microsoft Bing Web Search API}Microsoft Bing Web Search API,通过利用无监督预训练以及微调GPT-3\text{GPT-3}GPT-3来实现高质量的合成。本文并不是尝试改善一些原始材料,而是专注在使用更faithful\text{faithful}faithful的训练目标将其合并。遵循Stiennon et al\text{Stiennon et al}Stiennon et al的工作,使用人类反馈来直接优化答案质量,这可以使系统实现与人类相当的效果。
本文的两个主要贡献:
- 创建了一个基于文本的网页浏览环境,微调后的语言模型可以与该环境交互。这使得我们可以以端到端的形式使用通用的方法(例如模仿学习和强化学习)来改善检索与合成。
- 使用参考资料(references)\text{(references)}(references)来生成答案:模型在进行浏览时从网页中提取段落。这对于让标注者判断答案的事实准确性来说至关重要。
本文模型主要被训练来回答来自ELI5\text{ELI5}ELI5的问题,这是一个从"Explain Like I’m Five" reddit\text{reddit}reddit板块采样问题的数据集。本文还收集了两种额外类型的数据:使用网络浏览器回答问题的人类演示数据(demonstrations)\text{(demonstrations)}(demonstrations);相同问题两个模型生成答案的比较数据(comparisions)\text{(comparisions)}(comparisions)。评判答案的标准是事实的准确性、连贯性和整体有用性。
本文以四种方式使用该数据:使用演示数据进行行为克隆(监督微调)、使用比较数据训练奖励模型、针对奖励模型的强化学习、针对奖励模型的拒绝采样。本文最优的模型是合并了行为克隆(behavior cloning)和拒绝采样(rejection sampling)。
本文以三种不同的方式来评估最优模型。首先,针对部分问题比较了模型生成的答案与人类撰写的答案。在56%的时间里模型的答案是首选。其次,比较模型生成的答案与由ELI5\text{ELI5}ELI5数据集提供的最高投票答案。模型生成的答案在69%的时间里是首选。第三,在TruthfulQA\text{TruthfulQA}TruthfulQA上评估了模型。本文的模型能回答对75%的问题,并且在54%的情况下都是真实且包含信息的,超越了基础模型GPT-3\text{GPT-3}GPT-3,但是没有达到人类的表现。
二、环境设计


像先前REALM\text{REALM}REALM和RAG\text{RAG}RAG这样的问答工作主要专注在对于给定的query来改善文档检索。相反,对于这个部分本文使用了熟悉的现有方法:一个现代搜索引擎(Bing)。其有两个主要的优势:首先,现代搜索引擎已经非常强劲,索引了大量的最新文档。其次,使用一个搜索引擎来回答问题可以使我们专注在较高层面的任务。
本文了一个基于文本的网页浏览环境。语言模型会被提示撰写一个环境当前状态的摘要,包括问题、当前页面中位于当前光标的文本、以及一些其他信息(如图1b)。为了完成该目标,模型必须要完成表1中给出的命令之一,即执行Bing搜索、点击链接或者滚动屏幕等。然后在一个新的上下文重复这个过程。
当模型正在浏览时,其能够采用的动作之一是从当前页面抽取一个引用。当执行该操作时,页面标题、域名和摘要会被记录下来用作后面的引用。直至模型发出结束浏览的命令、达到操作的最大数量、或者达到引用的最大长度是结束。此时,只要模型至少有一个引用,模型就会使用问题和引用提示组成最终的答案。
三、方法
1. 数据收集
人类的指导是本文方法的核心。一个预训练语言模型并不能使用基于文本的流量器,因为其不知道有效命令的形式。因此我们收集了人类使用浏览器回答问题的样例,这样的数据称为演示数据(demonstrations)\text{(demonstrations)}(demonstrations)。然而,在独立的演示数据上进行训练并不能直接优化答案质量,并且不太可能带来超越人类的表现。因此,我们收集了模型针对相同问题生成的答案对,并要求人类来选择哪个更好,该数据称为比较数据(comparisons)\text{(comparisons)}(comparisons)。
对于演示数据和比较数据,绝大多数的问题都是来自于ELI5\text{ELI5}ELI5,其是一个long-form问题数据集。为了多样性和实验性,我们也混合了其他源的少量问题,例如TriviaQA\text{TriviaQA}TriviaQA。总的来说,收集了6000个演示数据,92%的问题来自ELI5\text{ELI5}ELI5;收集了21500个比较数据,98%的问题来自于ELI5\text{ELI5}ELI5。
为了方便人类提供演示数据,我们设计一个环境的图形化用户接口(图1a)。其本质上还是展示了基于文本接口的相同信息,并允许任何有效的行动被执行,但是对人类更友好。对于比较数据,我们设计了一个类似的接口,允许提供辅助注释和比较评分,尽管在训练时仅使用最终的比较评分(更好、更差或者相当)。
对于演示数据和比较数据,我们强调答案应该是相关的、连贯的、并且有值得信赖的参考资料支持。
2. 训练
本文方法中预训练模型的使用至关重要,因为其具有成功使用本文环境回答问题所需要的许多潜在能力,例如阅读理解、答案合成、语言模型的zero-shot\text{zero-shot}zero-shot能力。因此,微调的模型来自于GPT-3\text{GPT-3}GPT-3家族,包含760M,13B,175B\text{760M,13B,175B}760M,13B,175B模型尺寸。
基于这些模型,使用四个主要的训练方法:
- 行为克隆(Behavior cloning,BC)\text{(Behavior cloning,BC)}(Behavior cloning,BC)。使用监督学习的方法在演示数据上进行微调,以人类标注者发出的命令为标签;
- 奖励模型(Reward modeling,RM)\text{(Reward modeling,RM)}(Reward modeling,RM)。基于BC\text{BC}BC模型,训练一个输入为问题和带有参考资料的答案,输出为标量奖励的模型。遵循
Stiennon et al.,奖励代表一个Elo\text{Elo}Elo分数,两个分数之间的差异表示人类标注者更喜欢其中一个的概率的logit。奖励模型将比较数据集作为标签,使用交叉熵进行训练。 - 强化学习(Reinforcement learning,RL)\text{(Reinforcement learning,RL)}(Reinforcement learning,RL)。再一次遵循
Stiennon et al.,使用PPO\text{PPO}PPO在本文的环境中微调BC\text{BC}BC模型。对于环境的奖励,在每一阶段结束时获得一个奖励模型分数,并将其添加至BC\text{BC}BC模型在每个token上的KL\text{KL}KL散度惩罚项,用来缓解奖励模型的过度优化。 - 拒绝采样(Rejection sample)\text{(Rejection sample)}(Rejection sample)。从BC\text{BC}BC模型或者RL\text{RL}RL模型中采样固定数量的答案(4,16或者64),然后选择一个奖励模型排名最高的答案。我们使用这个作为优化奖励模型的可选方法,其不需要额外的训练,而是要更多的推理时间。
四、评估
评估主要集中在三个WebGPT\text{WebGPT}WebGPT模型上,每个模型都经过了行为克隆训练,并在相同大小的奖励模型上进行拒绝采样:760M best-of-4\text{760M best-of-4}760M best-of-4模型、13B best-of-16\text{13B best-of-16}13B best-of-16模型、175B best-of-64\text{175B best-of-64}175B best-of-64模型。为了简单起见排除RL\text{RL}RL,因为其在和拒绝采样相结合时并不能提供显著的改善。
使用采样温度0.8评估了所有的WebGPT\text{WebGPT}WebGPT,并使用人工评估进行了调整,浏览动作的最大数量为100。
1. ELI5\text{ELI5}ELI5

以两种不同的方式在ELI5\text{ELI5}ELI5测试集上评估WebGPT\text{WebGPT}WebGPT:
- 比较模型生成的答案和使用网络浏览环境的人工撰写的答案。
- 比较模型生成的答案和来自ELI5\text{ELI5}ELI5数据集的参考答案,参考答案来自于Reddit\text{Reddit}Reddit的最高票答案。在这个评估中,一个担忧是详细的评估准则与真实用户并不一致;另一个担忧是Reddit\text{Reddit}Reddit的答案通常不包括引用文献,这会带来盲目性。为了缓解这两个担忧,首先从模型生成的答案中剥离了所有的引用和参考文献,然后雇佣了新的承包商来评估结果,新的承包商不熟悉先前的详细准则,而是使用一个更简单的准则。
在这两种评估中,将偏好率为50%看作关键阈值。
结果如上图所示。最优的模型(175B best-of-64\text{175B best-of-64}175B best-of-64模型)在56%的时间里,生成的答案要比人类演示者所写的答案更受欢迎。这说明使用人类反馈是必不可少的,因为仅仅通过模仿演示数据是无法超过50%的。在69%的时间里,同一模型产生的答案优于来自ELI5\text{ELI5}ELI5数据集的标准答案。这相较于Krishna et al.\text{Krishna et al.}Krishna et al.有了重大的改善,其最好的模型仅有23%的时间优于参考答案,尽管它们的计算量比本文的少很多。
虽然相较于先前的工作,在ELI5\text{ELI5}ELI5参考答案上虽然效果显著。但是,与人类演示数据进行评估更有意义,原因如下:
-
事实检测
在没有参考资料的情况下,很难评估事实的准确性。即使有搜索引擎的帮助,通常也需要专业知识。WebGPT\text{WebGPT}WebGPT和人类演示数据都是通过参考资料来提供答案。
-
客观性
太少的instructions使得人很难知道选择一个答案而不选择另一个答案的准则是什么。更详细的instructions能够带来更多的可解释性和一致性。
-
盲目性(Blinding)
即使剔除了引用和参考文献,WebGPT\text{WebGPT}WebGPT构造的答案在风格上与Reddit\text{Reddit}Reddit不同,这对于比较来说不具有盲目性。相反,WebGPT\text{WebGPT}WebGPT和人类演示者构造的答案类似,这样在评估上会更加客观。
-
答案意图
ELI5\text{ELI5}ELI5中的问题通常是为了获得原始且简洁的解释,而不是那些可以在网络上直接找到的答案。这个准则并不是我们判别答案的标准。此外,ELI5\text{ELI5}ELI5中的许多问题仅会得到一些不费力的答案。而使用人类演示数据,则很容易确保期望的意图和效果一致。
2. TruthfulQA\text{TruthfulQA}TruthfulQA
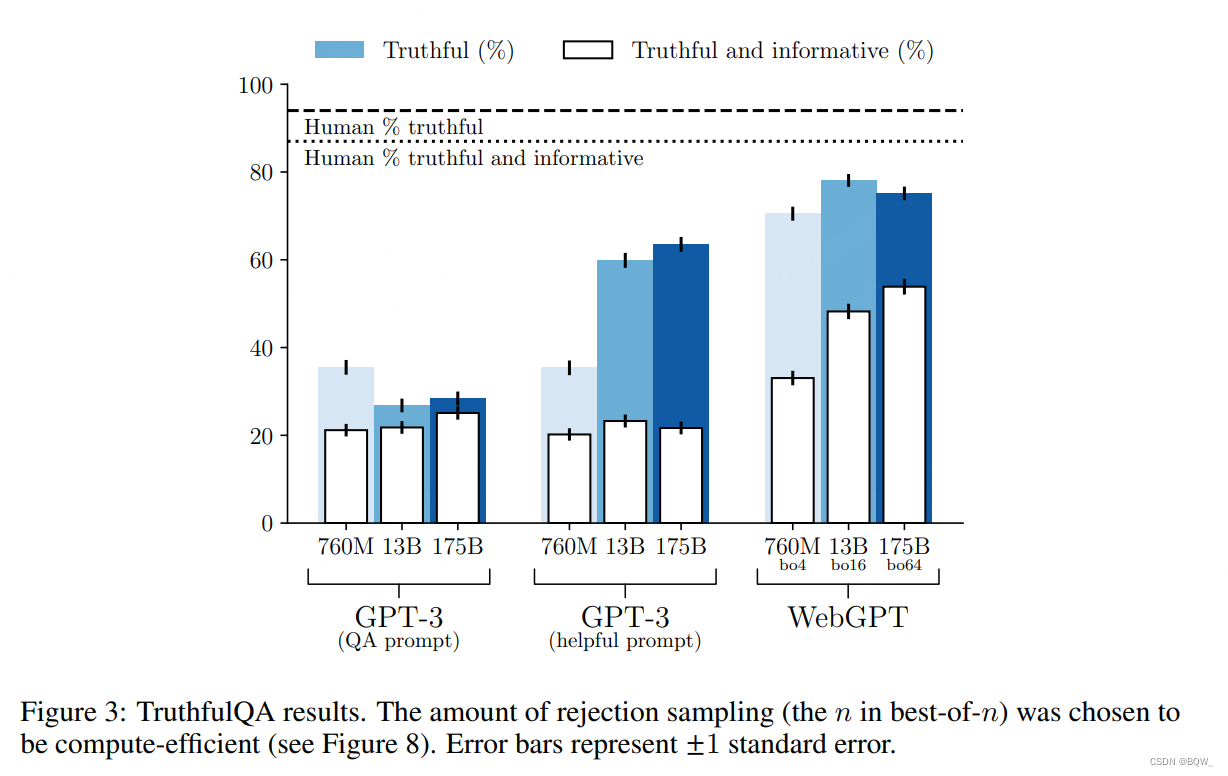
为了进一步探查WebGPT\text{WebGPT}WebGPT的能力,所以在TruthfulQA\text{TruthfulQA}TruthfulQA上评估WebGPT\text{WebGPT}WebGPT效果。TruthfulQA\text{TruthfulQA}TruthfulQA是通过对抗性构造的short-form问题数据集,若存在一些错误的概念或者知识,那么人也会在该数据集的问题上回答错误。答案的评分主要是真实性和信息量。
在TruthfulQA\text{TruthfulQA}TruthfulQA上评估了GPT-3\text{GPT-3}GPT-3(WebGPT\text{WebGPT}WebGPT的基础模型)和WebGPT\text{WebGPT}WebGPT模型本身。对于GPT-3\text{GPT-3}GPT-3,使用QA prompt\text{QA prompt}QA prompt和helpful prompt\text{helpful prompt}helpful prompt并使用自动化评估。对于WebGPT\text{WebGPT}WebGPT则使用人工评估,因为其答案已经超越了自动化评估的分布。TruthfulQA\text{TruthfulQA}TruthfulQA是一个short-form问题数据集,所以截断WebGPT\text{WebGPT}WebGPT的答案至50个token的长度,并移除后面的部分句子。
结果如上图所示。所有的WebGPT\text{WebGPT}WebGPT模型都超越了GPT-3\text{GPT-3}GPT-3模型。此外,不同于GPT-3\text{GPT-3}GPT-3,随着模型规模的增加,WebGPT\text{WebGPT}WebGPT给出的真实且信息丰富的答案比例也在增加。
五、实验
1. 训练方法比较

本文进行了一些额外的实验比较强化学习和拒绝采样以及与行为克隆的baseline。结果如上图所示,拒绝采样(Rejection sampling)\text{(Rejection sampling)}(Rejection sampling)能够提供显著的收益,175B best-of-64 BC\text{175B best-of-64 BC}175B best-of-64 BC模型相较于175B BC\text{175B BC}175B BC模型有68%的时间是首选。此外,强化学习(RL)\text{(RL)}(RL)能够带来更小的收益,175B RL\text{175B RL}175B RL模型相较于175B BC\text{175B BC}175B BC模型有58%的时间是首选。
尽管拒绝采样和强化学习都是对相同的奖励模型进行优化,这可能有几个原因来解释为什么拒绝采样优于强化学习:
- 多次尝试回答问题可能是有帮助的,只是为了利用更多的推理时计算。
- 环境是不可预测的:通过拒绝采样,模型能够查看更多的网站,并且评估它发现的信息。
- 奖励模型主要是从行为克隆和拒绝采样中收集的数据上进行训练,这可能对拒绝采样的过度优化鲁棒性强于强化学习。
- 强化学习需要超参数调整,而拒绝采样不需要。
合并强化学习和拒绝采样提供的收益并没有单独的拒绝采样更好。一个可能的原因是强化学习和拒绝采样都是针对奖励模型进行优化的,其很容易被过度优化。除此之外,强化学习减少了policy\text{policy}policy的熵,其对于探索有害。
另一个值得注意是,针对比较数据仔细调整BC\text{BC}BC baseline。使用人工评估和奖励模型分数的组合来调整BC\text{BC}BC模型的epochs数量和采样温度。仅通过这一点就消除了最初看到BC\text{BC}BC和RL\text{RL}RL的差距。
2. 规模实验
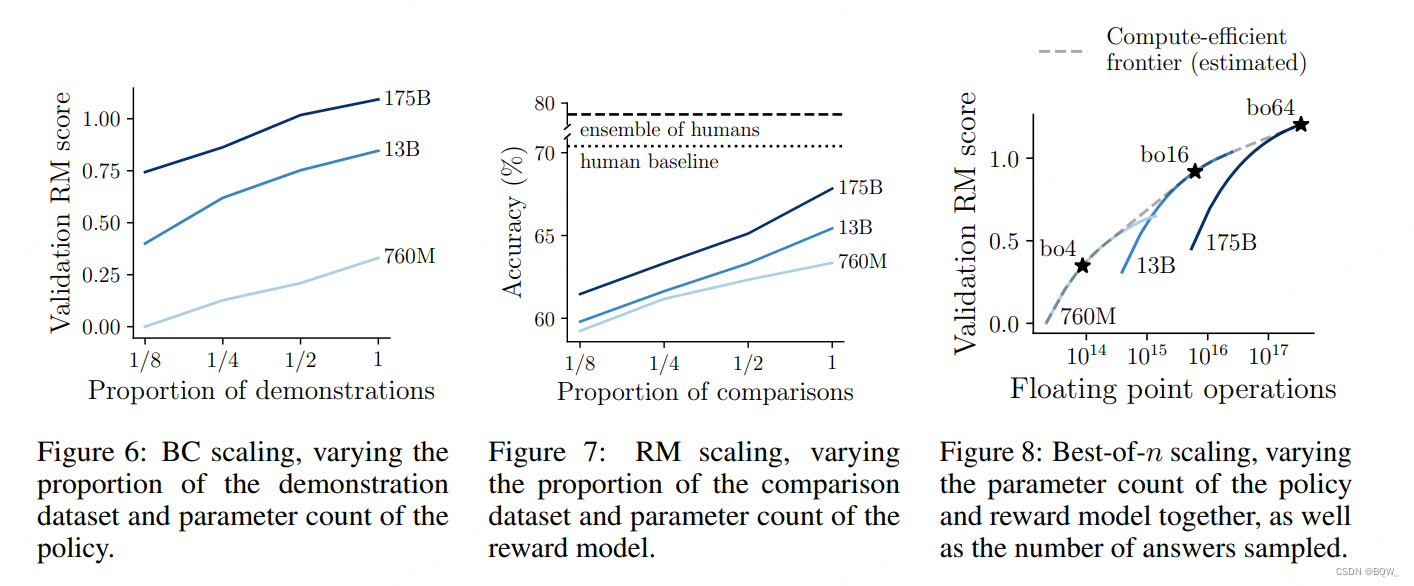
本文也研究了模型的效果随着数据集大小、模型参数量以及拒绝抽取样本量的变化。因为人工评估可能有噪音并且昂贵,这些实验使用了175B\text{175B}175B奖励模型的分数。我们发现在不使用强化学习优化奖励模型的情况下,其是一个人类偏好的优质预测器。回顾一下,奖励表示为Elo\text{Elo}Elo分数,1个点的差异代表sigmoid(1)≈73%\text{sigmoid(1)}\approx 73\%sigmoid(1)≈73%的偏好。
上图6和7展示了数据集尺寸和模型参数量的缩放趋势。对于数据集尺寸,演示数据的数量翻倍则奖励模型的分数增加0.13,比较数量翻倍则奖励模型的准确率增加1.8%。对于参数量,趋势比较嘈杂,在policy中参数量加倍则奖励模型的分数粗略增加0.09,奖励模型的参数量增加一倍则准确率提升0.4%。
对于拒绝采样,我们分析了给定推理时间计算代价的情况下如何平衡样本数量和模型参数量(上图8)。实验发现使用一定数量的拒绝采样通常是计算高效的,但也不是太多。
本文链接:https://my.lmcjl.com/post/10628.html
4 评论