基于GPT-3.5的chatGPT热度才稍稍减退没多久,GPT-4又来了,文新一言的发布会也槽点满满,差距似乎越来越大了。
chatGPT到底厉害在哪?为什么突然就爆火了呢?
它的爆火,一方面,和它的出现形态有关,另一方面,当然和它的技术有关。
从形态上看
在过去的几年里,AI其实在各领域都有长足的发展。但是这些领域都过于小众。只有圈内的人了解。在这个领域内,人工智能的发展对于普通人而言,人工智能还是一个遥远而又看不见也摸不着的概念。
当然,这也和AI的发展状态有关。决策式AI,通常需要在特定领域的大量数据训练,用于辅助人类决策,使用场景上通常在企业端。而生成式AI则可以生成文字、音频、多媒体等各类内容,这些内容是可以被普通人所感知的。
去年,AI绘图工具——Midjourney创作的《太空歌剧院》(“Théatre D’Opéra Spatial),在美国科罗拉多州博览会艺术比赛上,获得了“ 数字艺术/数字修饰照片”一等奖。

生成式AI创作的内容跨越了圈层和阶级,超越了种族隔阂,消融了文化差异,不再是小众领域的曲高和寡,而是老少皆宜的雅俗共赏。
而chatGPT采用对话的模式,以更低的门槛让普通人也能体验,更加感觉像人们理想中的通用人工智能。这让很多普通人第一次真正的感知到了人工智能的存在。
所谓人们理想中的通用人工智能,也就是更像人类。那么到底chatGPT是如何做到更像人的呢?这就得从技术上解读了。
从技术上看
从表现上看,chatGPT的核心能力在于三点,第一,它能理解人类的语言;第二,它能输出人类想要的结果;第三,它能从人类的反馈中不断学习,自我进化。
这得益于NLP技术的发展以及大语言模型(LLM)的诞生。
Google在2017年发表了论文《Attention is all your need》,在Transformer框架中引入了注意力的概念,简单来说,这是模拟人类在接受信息时,把有限的注意力集中到重点之上的思路,有助于在长文本中,理解距离较远的词之间的联系。
OpenAI基于Transformer框架推出了生成式预训练模型(Generative Pre-trained Transformers (GPT)),并且每年一迭代,在GPT3推出的时候,其能力已经超乎很多人想象。chatGPT是基于GPT3.5做的微调,在对话方面做了进一步强化。
而GPT4,则在文字输入限制(提升至2.5万字)、回答准确性、风格变化等方面又有了巨大提升。
数据玩家通过这两天的研究,认为chatGPT的在已有技术的基础上,升级的核心主要在于两点:
- 训练方法:生成式预训练+Prompting(提示),使得训练的过程大大加速
- 训练策略:通过基于人类的反馈的强化学习来进行训练。也就是,终于把强化学习用到了NLP领域
我们知道,训练AI其实是和教育人类的小孩类似的。当AI犯错时,你要提醒他什么是对的,这个过程需要大量的人工标注来实现。
在以往的决策式AI训练中,海量的人工标注数据是训练AI的基础。类似图像识别、自动驾驶、金融领域的信贷风控等,都依赖于大量的样本标注数据。标注的工作需要大量的人力投入,因此,模型的训练成本也很高。
大语言模型LLM的训练方式改变了,直接喂给AI海量的文本,让它自己学。扣掉一些词让它做完形填空(BERT模式),或者让它看了上句猜下句(GPT模式)。
在这样训练之后,AI能够理解人类语言的模式,它知道一个词出现之后,他后面大概率还会出现什么词。
并且,在学习了海量的文本后,AI有了“常识”,这是通用型人工智能的一大特点,也是人类和AI的主要区别之一。
它学习了数理化,也熟读文史哲,它知道明星的名字,也知道现在美国总统是谁,它的的确确更像人了。
另外,从工程上,原来的训练方法(fine-tuning,微调),每更新一次参数,都需要更新模型,换句话说,要重新跑一下;而采用prompting的模式,则完全不用,只需要给AI投喂一些示例,让它自己体会。
这就是为什么你可以追问chatGPT,他会随着你的追问,越来越贴近你想要的结果。
而这个追问的方式,完全不需要你写代码,只需要对话就行,这使得chatGPT可以通过和成千上万,甚至数亿的用户对话来飞速成长,这是人类理想中通用人工智能的样子。
如果AI能够自动从人类的语言中判断一个回答好还是不好,而不用人类去标注他的回答,那将会节省非常多的标注工作量。这就是基于人类的反馈强化学习RLHF(Reinforcement Learning from Human Feedback)。
强化学习是一种训练策略,其他策略还有有监督(有标注样本)、无监督(无标注样本,主要做分类)等。
AlphaGo就是采用的强化学习,通过一个奖励/惩罚函数,来告诉AI这一步是加大获胜概率,还是减小,这样AI就可以不断的和自己对弈。
为什么NLP领域之前没采用这种方式呢?主要是因为这个奖励/惩罚函数太难设计了。
人类针对一个回答可能给出非常多种的评价。比如说:不错、还行、挺好的、很好、太棒了、和我想的一样;或者:这不是我想要的结果、错了、这样不对、还可以更好、我觉得你没有理解我的意思……
这些反馈几乎是难以穷尽的。除非真的找一堆人,来针对AI给出的N种回答,量化的选择自己喜欢哪一种,不喜欢哪一种。
不就是人嘛,不就是钱嘛,OpenAI不差钱,自然也不差人。

他们找了40个人的专职外包团队,真的开始一条条的标注,所以你看,看起来是个通用人工智能了,还是靠人堆出来的。
现在,上亿的用户正在时时刻刻为chatGPT提供着更多的数据,更多的反馈,毫无疑问,这些数据将会被用于GPT-4的开发,这个数据量级,基本上已经穷尽了人类对于特定回答可能的反应,再往后,chatGPT真的就是边聊边学了。
chatGPT将在哪些领域应用?我们会失业吗?
又该回到那个老生常谈,但又直击灵魂的问题,我们会被AI取代吗?
更具体点,我们会被chatGPT取代吗?
毫无疑问,是的。
内容创作
除了文字创作以外,有点反直觉的是,创意创作的职业有可能会更快的被取代,比如说画家,作曲家等等。
这听上去和大家以往的认知有点不太一样。
按照大家的传统认知,人类最有优势的就在于人类的创意,而创意来自于自主意识,这也是AI所不具备的。
所谓的创新和创意其实是在有限的排列组合里创作出一个人类能够感知到美的唯一组合。
这个有限的空间指的就是音符、绘画的颜色和构图等。
音符和色彩组成的空间,对人类来说并不算是有限的,几乎可以等同于无限空间,但对于AI来说,特别是对于超大算力的AI来说,是可以穷尽的有限空间。
而在一个相对有限的空间里,不断的试错,寻找最优或者次优解这种事情,AI再擅长不过了。
事实上现在有很多的画家已经把寻找灵感这件事,交给AI了。
即先尝试让AI通过给出的一个或几个关键字进行创作,从AI创作的一系列作品中挑选自己喜欢的,用来寻找灵感,再将AI的画作用自己的风格画出来。
也就是说,画家、作曲家,这类人类引以为豪的创意创作职业,已经把自己最核心的竞争优势——灵感,交给AI去处理了。
剩下的所谓作曲或者作画风格,如果要进行模仿,对于AI来说更加不在话下。

Google Deep Dream 2015年作品
诚然,大师的作品总是难以逾越的,但是对于大多数不那么著名的创作者,自己的作品比起AI来说,到底有什么更打动人心的地方呢?
咨询领域
其他的职业当然也面临同样的危机,比如咨询领域基础的法律,财务金融保险等等咨询包括在线客服针对于某些领域特定知识的解答都可以被AI很好的完成,事实上现在很多人已经在用全gt去寻找。这些领域的问题的答案而不再咨询同类
类似的还有教师,科普工作者等等
程序员
此外,程序员们似乎要被自己写出来的AI隔了自己的命,特别是面向Google编程的,只会ctrl加c,ctrl加v的程序员们。
特定功能的基础代码chatGPT可以很好的完成,并且几乎是瞬间完成。
难点在于如何把一个现实问题转化为一个编程问题,拆解成多个明确的编程模块。
这是以后程序员们应该具备的核心竞争力,也就是编程思维。
总的来看,可能会被AI替代的,仍然是这个职业里面相对不那么资深的从业者。
其实换个角度,他们即使不被AI替代,也会被更优秀的同类替代,被会使用AI的同类替代。
所以对于这一类人来说,他们与其担心AI,不如先审视一下自己。
不过大家也不用过于担心,纵观人类历史,新技术的出现固然会导致一部分人的工作被替代,但是同时也会催生出新的职业和岗位。
蒸汽机的出现使得小作坊难以为继,催生了卢德运动。

但是蒸汽机普及之后,失业的人们也找到了更适合自己的工作。从整体上来看,人类在技术进步之后,更有余力去从事更加轻松的工作。
AI的出现同样催生了新的职业和岗位,比如AI标注师。AIGC时代的标注师,除了要给样本打标,还要自己创作内容给AI学习,引导AI修改回答,更要为AI创作的多个内容进行排序,以后的AI标注需求会更多样化,更加复杂。
除了催生出新岗位,AI也会赋能一些岗位,从而改变一些职业。
比如程序员不再需要写很多基础的代码,而是更多的需要利用AI去完成更大,更复杂的任务。
人均产能比原来提升了很多,但是技能更偏向于逻辑思维和问题拆解等能力。
同样,数据分析师也不再需要去做基础的数据整理、收集、整合等等工作,而是要更多的把精力放在数据的理解,业务目标的洞察上。
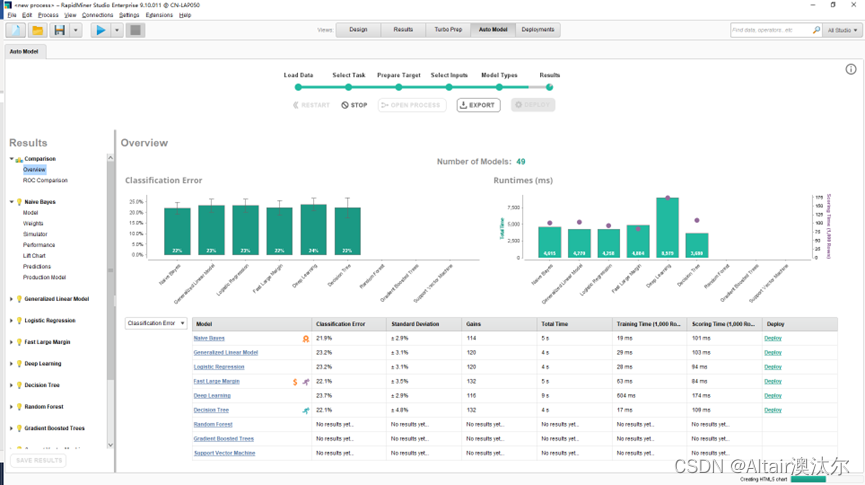
数据的整理、收集、整合,甚至建模的繁重工作,都可以由AI来完成,事实上,现在已经有不少工具支持以上功能了,比如Altair RapidMiner等产品,能够解决预测、聚类和异常值检测三大类问题,大大加快了模型的构建和验证过程。
比如Altair RapidMiner支持自动建模(Auto Model) 和自动数据准备(Turbo Prep)。我主要试用了其中的自动建模功能,它能够解决预测、聚类和异常值检测三大类问题,
可以在帮助用户评估数据的同时,为问题解决提供相关模型,并在计算完成后帮助用户比较模型结果,大大加快了模型的构建和验证过程。
自动数据准备功能中最令我印象深刻的是自动数据清洗功能(AUTO CLEANSING),包括移除低质量变量(REMOVE LOW QUALITY),替代缺失值(REPLACE MISSING),标准化(NORMALIZATION),离散化(DISCRETIZATION),哑变量编写(DUMMY ENCODING),PCA等等。

有了这样高产能的工具,程序员和数据分析师都可以从80%的重复劳动中解脱,把精力投入到实现业务价值、提升程序效率、与前端业务部门更好的沟通和协作上。“时代抛弃你的时候,连一声招呼也不会打”,那个时代已经来了,与其等着被抛弃,不如提前拥抱变化,用更好的工具完成自己耗时耗力的基础工作,从而腾出时间,改变自己的技能树,在这变革的时代中,站稳脚跟。
本文链接:https://my.lmcjl.com/post/10560.html
4 评论