目录
- 1. 配置阶段
- 1.1 依赖引入
- 1.2 配置application.yml文件
- 1.3 注解添加
- 2 使用
- 2.1 生成回答
- 2.1.1 测试
- 2.2 生成图片
- 2.2.1 测试
- 2.3 下载图片
- 2.3.1 测试
- 2.4 生成流式回答
- 2.4.1 流式回答输出到IDEA控制台
- 2.4.2 流式回答输出到浏览器页面
- 3 AI助手展示
1. 配置阶段
1.1 依赖引入
pom.xml中引入依赖(当前最新版本为1.1.3,可前往Github页面查看当前最新版本)
<dependency><groupId>io.github.asleepyfish</groupId><artifactId>chatgpt</artifactId><version>1.1.3</version></dependency>
1.2 配置application.yml文件
在application.yml文件中配置相关参数(Optional为可选参数)
| 参数 | 解释 |
|---|---|
| token | 申请的API KEYS |
| proxy-host | 代理的ip |
| proxy-port | 代理的端口 |
| model (Optional) | model可填可不填,默认即text-davinci-003 |
| chat-model (Optional) | 可填可不填,默认即gpt-3.5-turbo (ChatGPT当前最强模型,生成回答使用的就是这个模型) |
| retries (Optional) | 指的是当chatgpt第一次请求回答失败时,重新请求的次数(增加该参数的原因是因为大量访问的原因,在某一个时刻,chatgpt服务将处于无法访问的情况,不填的默认值为5) |
| session-expiration-time (Optional) | (单位(min))为这个会话在多久不访问后被销毁,这个值不填的时候,即表示所有问答处于同一个会话之下,相同user的会话永不销毁(增加请求消耗) |
例:
chatgpt:token: sk-xxxxxxxxxxxxxxxproxy-host: 127.0.0.1proxy-port: xxxxsession-expiration-time: 30
其中token、proxy-host、proxy-port是必填的
上面的session-expiration-time参数很重要,是用来表示这个会话在多久不访问后被销毁,从而实现联系上下文的连续对话。
实现方式是通过ChatCompletionRequest中的user来区分某个会话,而session-expiration-time表示这个会话在多久不访问后被销毁。
如果这里看不懂请看2.1节示例
1.3 注解添加
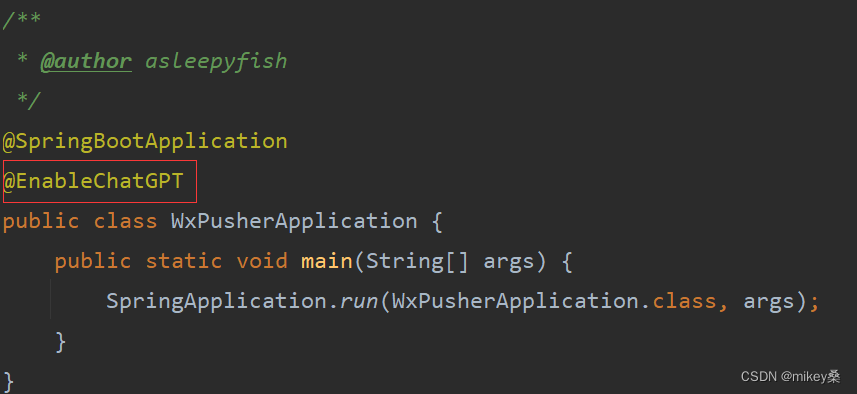
启动类上加入图中的注解则将服务注入到Spring中。
2 使用
2.1 生成回答
提供了工具类OpenAiUtils,里面提供了相关方法进行调用。
其中最简单的使用方法是:
OpenAiUtils.createChatCompletion(content);// 不建议使用
入参content即输入的问题的字符串。但是不建议使用。
这里建议使用下面的方式,通过传入user的值,再结合session-expiration-time参数,可以实现指定某次会话,或者某个用户的连续对话。
OpenAiUtils.createChatCompletion(content, user);// 建议使用
还提供一个通用的静态方法是
public static List<String> createChatCompletion(ChatCompletionRequest chatCompletionRequest) {...}
入参ChatCompletionRequest 里包含模型的一些可调参数。
OpenAiUtils类中还提供了多个可供选择的静态方法,可以自行查看。
上述方法的返回参数是一个list,是因为调整参数返回答案n可以一次性返回多条不同的解答(n为ChatCompletionRequest类中一个参数)。
2.1.1 测试
测试代码:
@PostMapping("/chatTest")
public List<String> chatTest(String content) {return OpenAiUtils.createChatCompletion(content, "testUser");
}
Post请求
返回结果:
["\n\nJava序列化是将Java对象转换为字节序列的过程,以便在网络上传输或将其保存到磁盘上。Java提供了两种序列化方式:\n\n1. 基于Serializable接口的序列化\n\nSerializable接口是Java提供的一个标记接口,用于标记一个类可以被序列化。如果一个类实现了Serializable接口,那么它的所有非瞬态字段都会被序列化。序列化的过程可以通过ObjectOutputStream类来实现,反序列化的过程可以通过ObjectInputStream类来实现。\n\n2. 基于Externalizable接口的序列化\n\nExternalizable接口也是Java提供的一个标记接口,用于标记一个类可以被序列化。与Serializable接口不同的是,Externalizable接口需要实现writeExternal和readExternal方法,这两个方法分别用于序列化和反序列化。在序列化的过程中,只有被writeExternal方法显式写入的字段才会被序列化,而在反序列化的过程中,只有被readExternal方法显式读取的字段才会被反序列化。\n\n总的来说,基于Serializable接口的序列化更加简单,但是它会序列化所有非瞬态字段,包括一些不需要序列化的字段,而基于Externalizable接口的序列化可以更加灵活地控制序列化的过程。"
]
返回结果:
["是的,Java中有很多高效的序列化框架,以下是一些常用的序列化框架:\n\n1. Protobuf\n\nProtobuf是Google开发的一种高效的序列化框架,它可以将结构化数据序列化为二进制格式,支持多种编程语言。相比于Java自带的序列化方式,Protobuf序列化后的数据更小,解析速度更快。\n\n2. Kryo\n\nKryo是一个快速、高效的Java序列化框架,它可以将Java对象序列化为字节数组,支持多种数据类型。Kryo序列化的速度比Java自带的序列化方式快很多,序列化后的数据也更小。\n\n3. FST\n\nFST是一个高性能的Java序列化框架,它可以将Java对象序列化为字节数组,支持多种数据类型。FST序列化的速度比Java自带的序列化方式快很多,序列化后的数据也更小。\n\n4. Avro\n\nAvro是一个高效的数据序列化系统,它可以将结构化数据序列化为二进制格式,支持多种编程语言。Avro序列化后的数据比Java自带的序列化方式更小,解析速度也更快。\n\n总的来说,这些高效的序列化框架都比Java自带的序列化方式更快、更小、更灵活,可以根据具体的需求选择合适的框架。"
]
可以看出上述两次问答是在一次会话中的,而前面所说的参数session-expiration-time即这个user所代表的会话多久没被继续访问时的销毁时间。单位(min)
2.2 生成图片
最简单的使用方式是
OpenAiUtils.createImage(prompt);
入参表示生成图片的描述文字,还提供了一个通用的静态方法
public static List<String> createImage(CreateImageRequest createImageRequest) {...}
入参CreateImageRequest中有一些可以使用的参数,其中n表示生成图片的数量,responseFormat表示生成图片的格式,格式中分为url和b64_json两种,如果希望返回的是url,则返回的url会在生成一个小时后消失,默认值是url。
2.2.1 测试
测试代码
@Testpublic void testGenerateImg() {OpenAiUtils.createImage("英短").forEach(System.out::println);}
结果
默认情况下会生成一个url,点击去就可以看到图片。

2.3 下载图片
在3.2的基础上做了优化,直接使用responseFormat为b64_json然后解析成图片返回。简单使用方式如下:
OpenAiUtils.downloadImage(prompt, response);
通用方式如下:
public static void downloadImage(CreateImageRequest createImageRequest, HttpServletResponse response) {...}
当CreateImageRequest对象中设置的返回参数n大于1时,会将图片打包成一个zip包返回,当n等于1时直接返回图片。
2.3.1 测试
测试代码
@RestController
public class ChatGPTController {@GetMapping("/downloadImage")public void downloadImage(String prompt, HttpServletResponse response) {OpenAiUtils.downloadImage(prompt, response);}
}
发送get请求,然后选择Send and Download
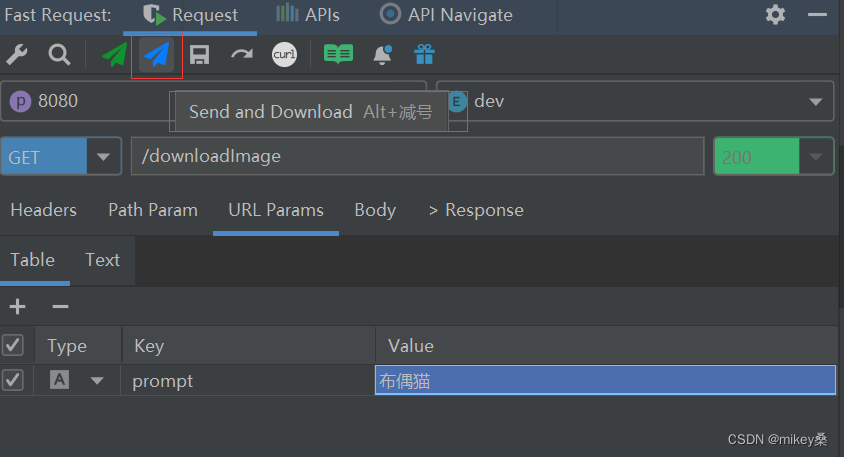
我用的get 工具是idea里面下载的插件Fast Request的,用Postman也是可以的,但是要选择 Send and Download,上图中绿色的箭头是Send,蓝色的是Send and Download。

2.4 生成流式回答
生成流式回答的方法是OpenAiUtils的createStreamChatCompletion方法,本工具类重载了同名的多个参数的方法,其中最通用的方法是
public static void createStreamChatCompletion(ChatCompletionRequest chatCompletionRequest, OutputStream os) {...}
最简单的方法是
public static void createStreamChatCompletion(String content) {...}
其中的content即本次对话的问题。
这里需要主义的是,上述第一个方法中的OutputStream os其实是一个必传的对象,上述的最简单的方法实际上是默认传递的System.out这个os对象,也就是将流式问答的结果显示到IDEA的控制台。
如果需要将流式问答的结果显示到其他界面可以自发的传入OutputStream os对象,这里有一个简便的方法是
public static void createStreamChatCompletion(String content, OutputStream os) {...}
只需要输入问题,和输出流对象即可。
下面将举例具体说明。(本文所有Demo的示例地址: https://github.com/asleepyfish/chatgpt-demo)
2.4.1 流式回答输出到IDEA控制台
代码如下:
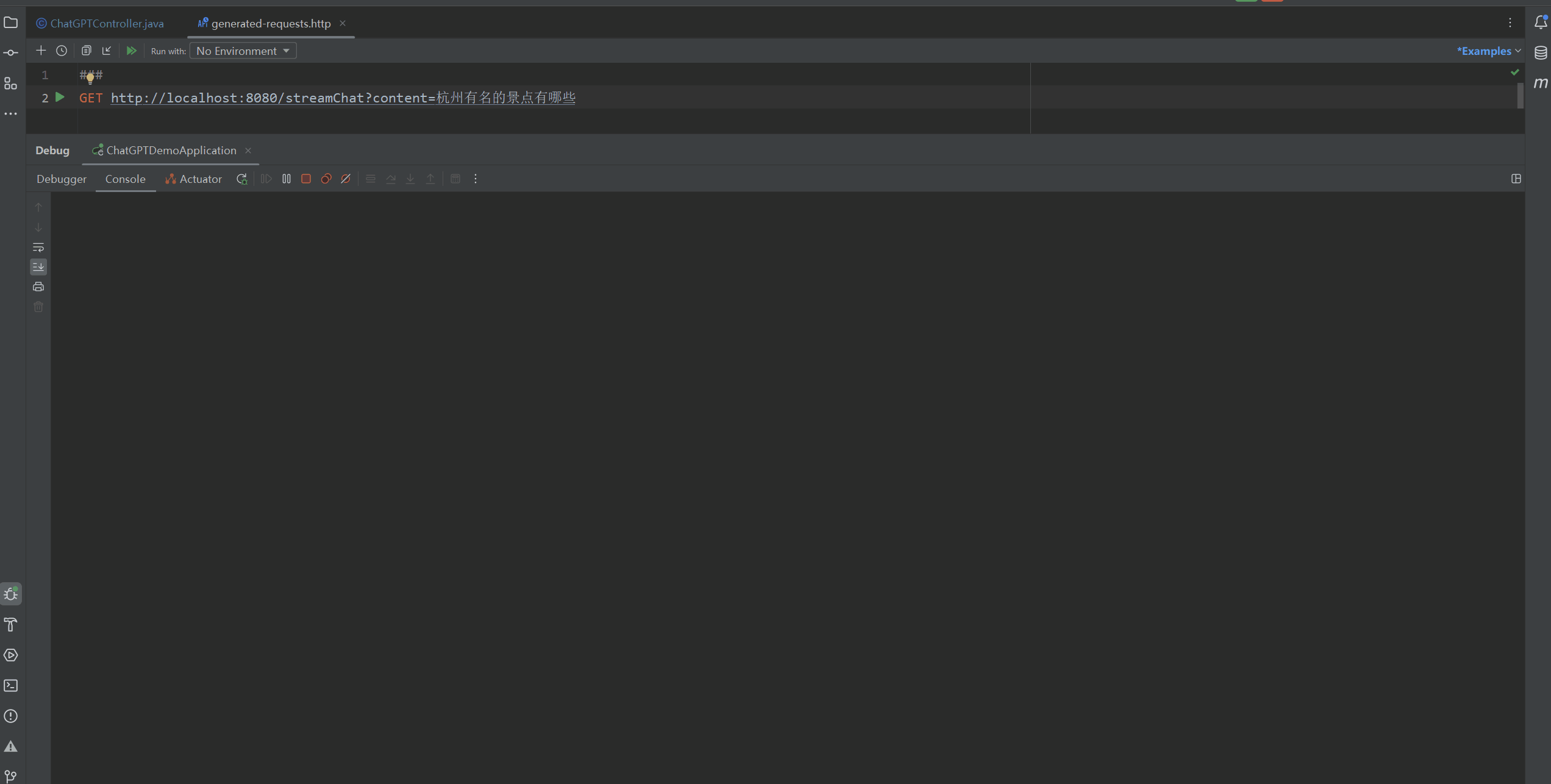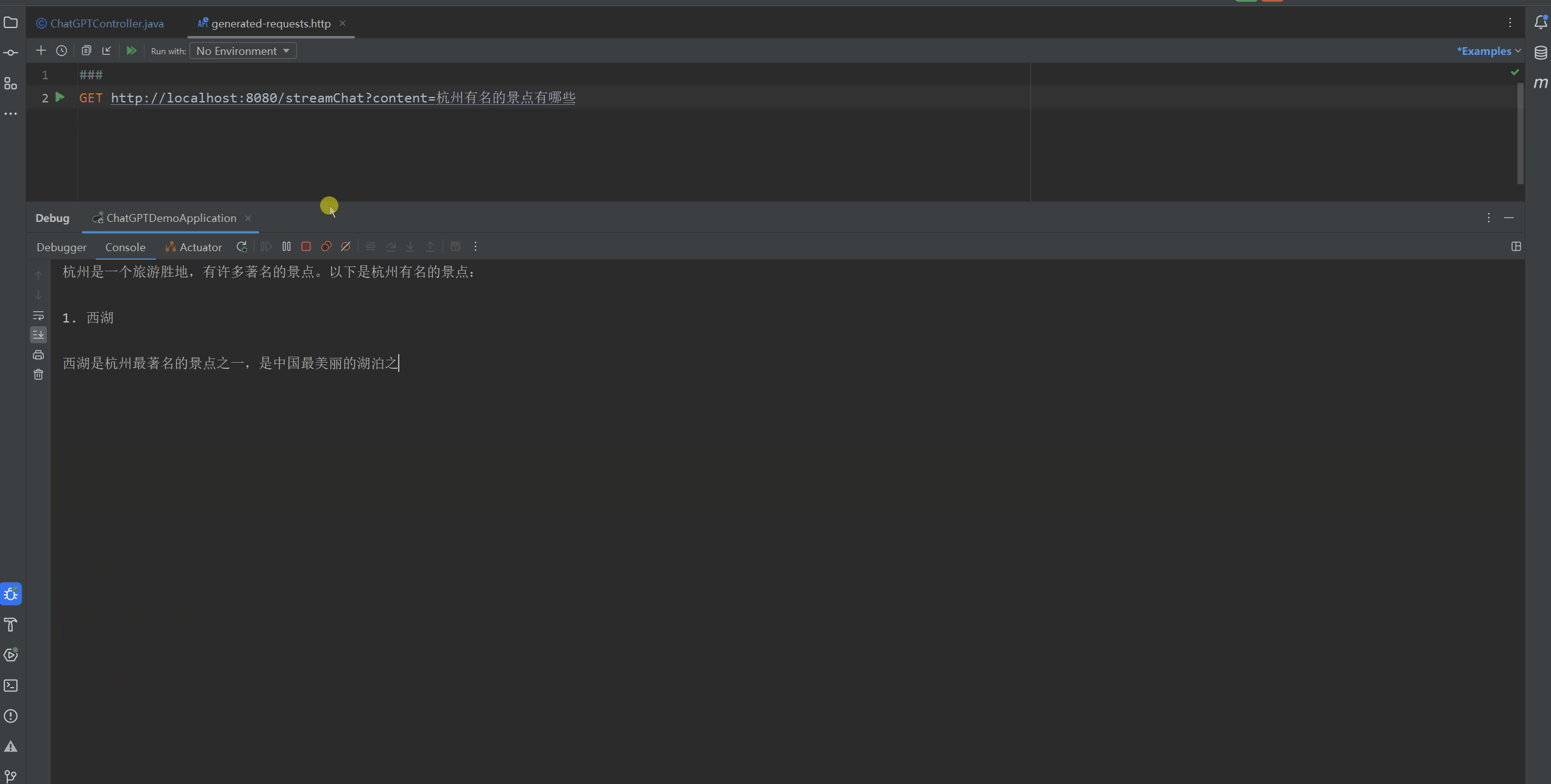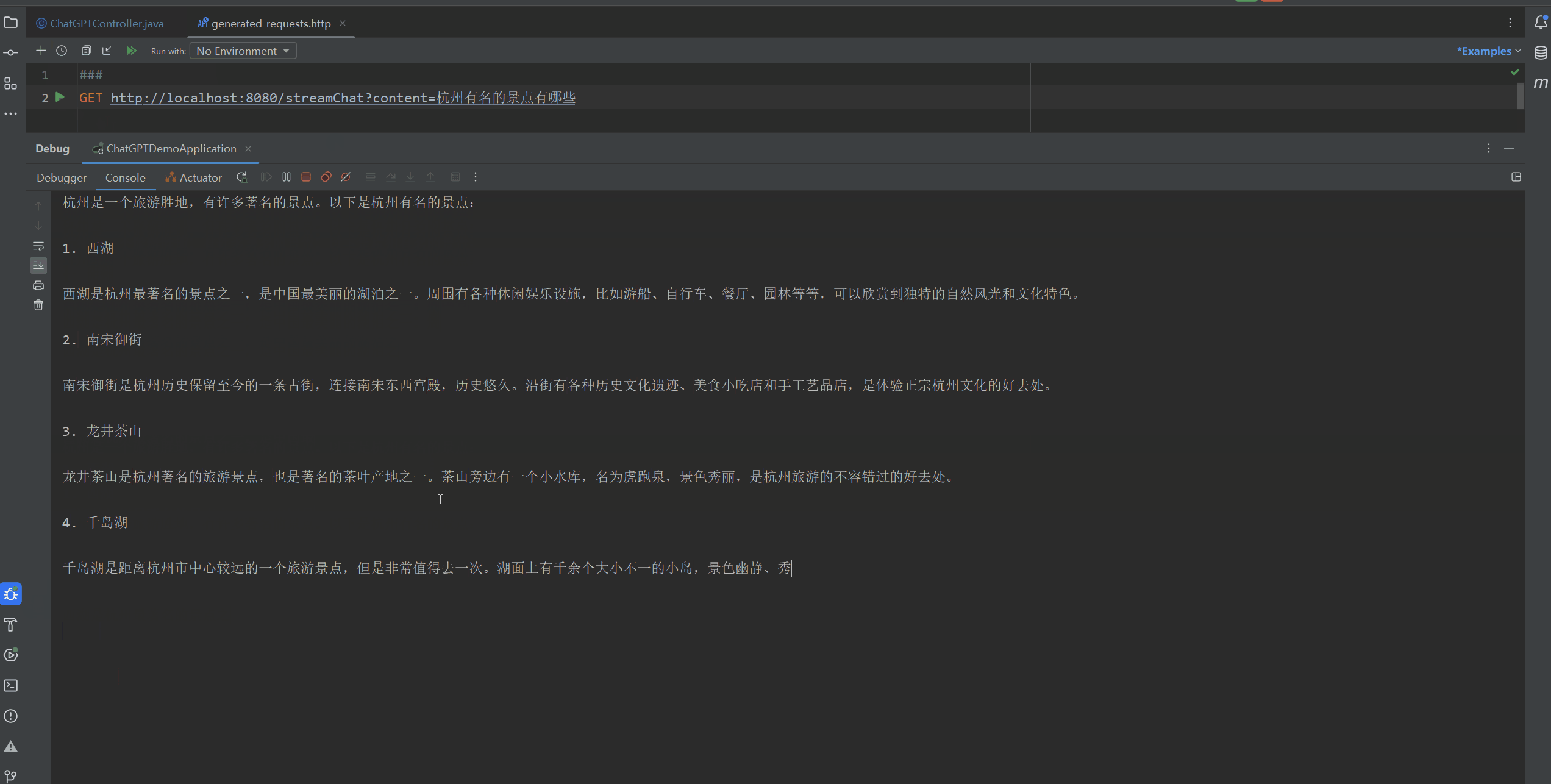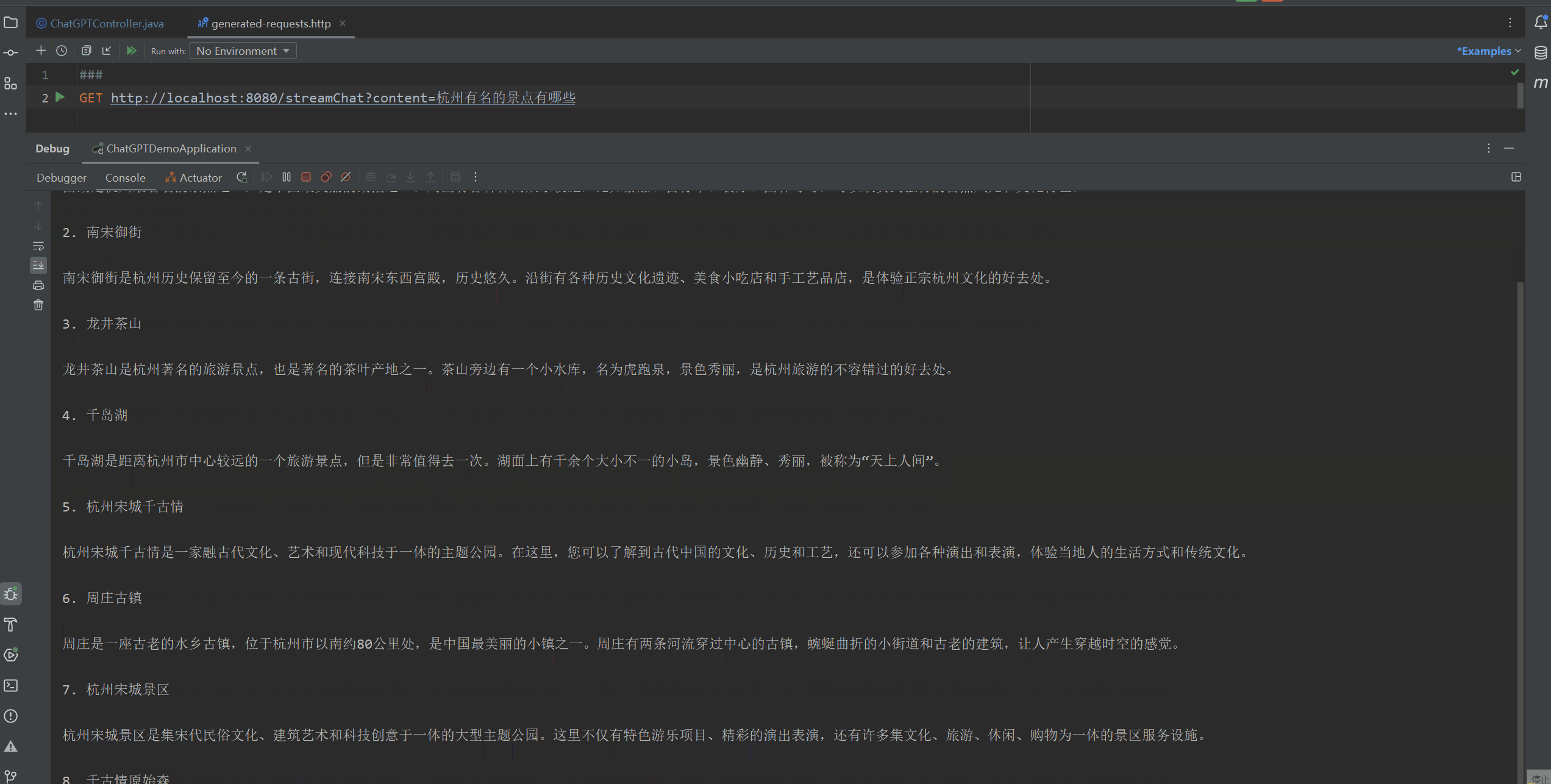
@GetMapping("/streamChat")
public void streamChat(String content) {// OpenAiUtils.createStreamChatCompletion(content, System.out);// 下面的默认和上面这句代码一样,是输出结果到控制台OpenAiUtils.createStreamChatCompletion(content);
}
然后使用Postman或者其他可以发送Get请求的工具发送请求。
本次测试的结果如下面的Gif图所示
2.4.2 流式回答输出到浏览器页面
上述的方法中输出流传入的是System.out对象,该对象实际上就是一个PrintStream对象,会把输出结果展示到控制台。
如果需要将输出结果在浏览器展示,可以从前端传入一个HttpServletResponse response对象,拿到这个response以后将response.getOutputStream()这个输出流对象传入createStreamChatCompletion方法的入参中。同时,为了避免结果输出到浏览器产生乱码和支持流式输出,需要ContentType和CharacterEncoding。
具体代码如下:
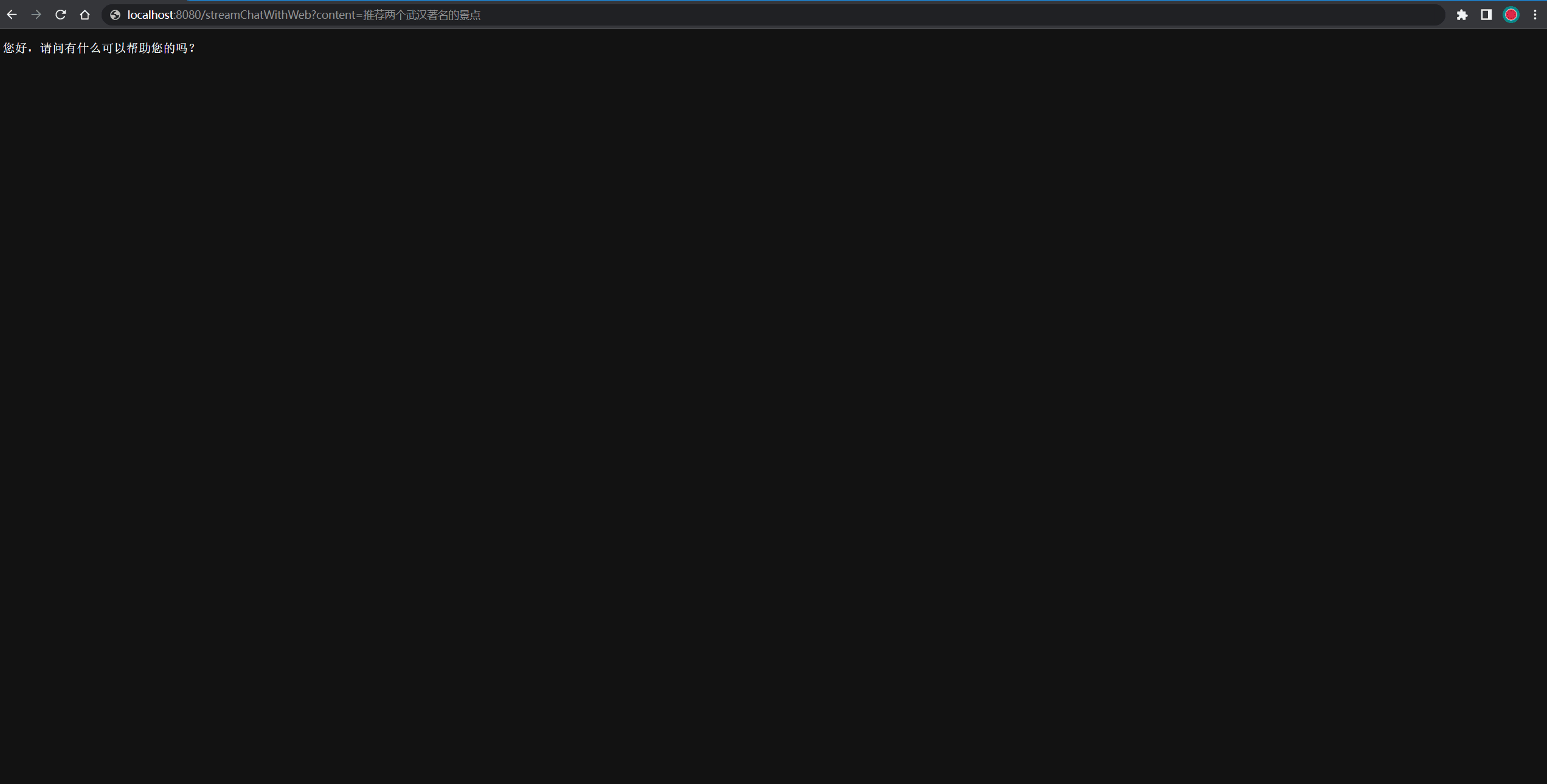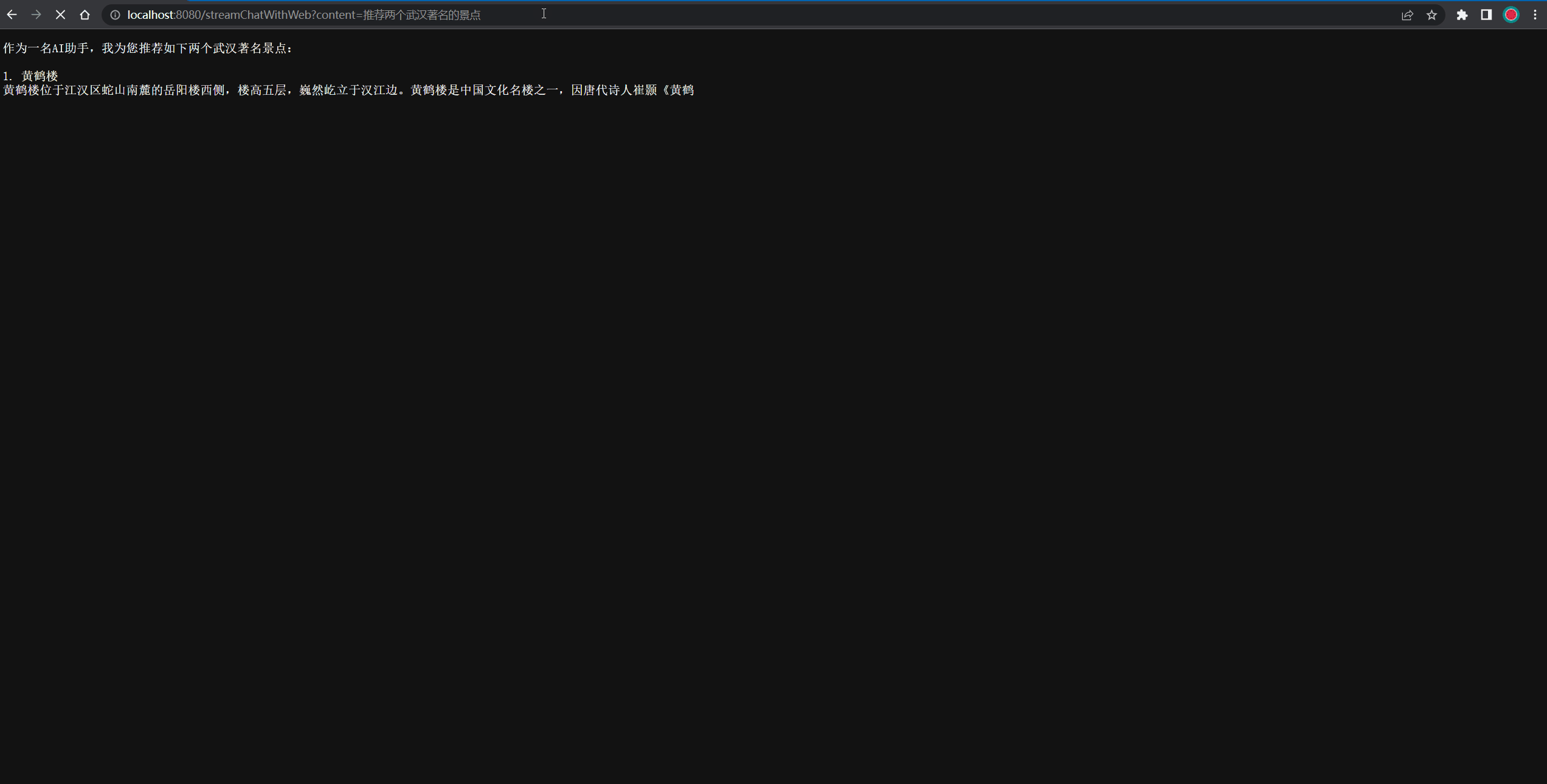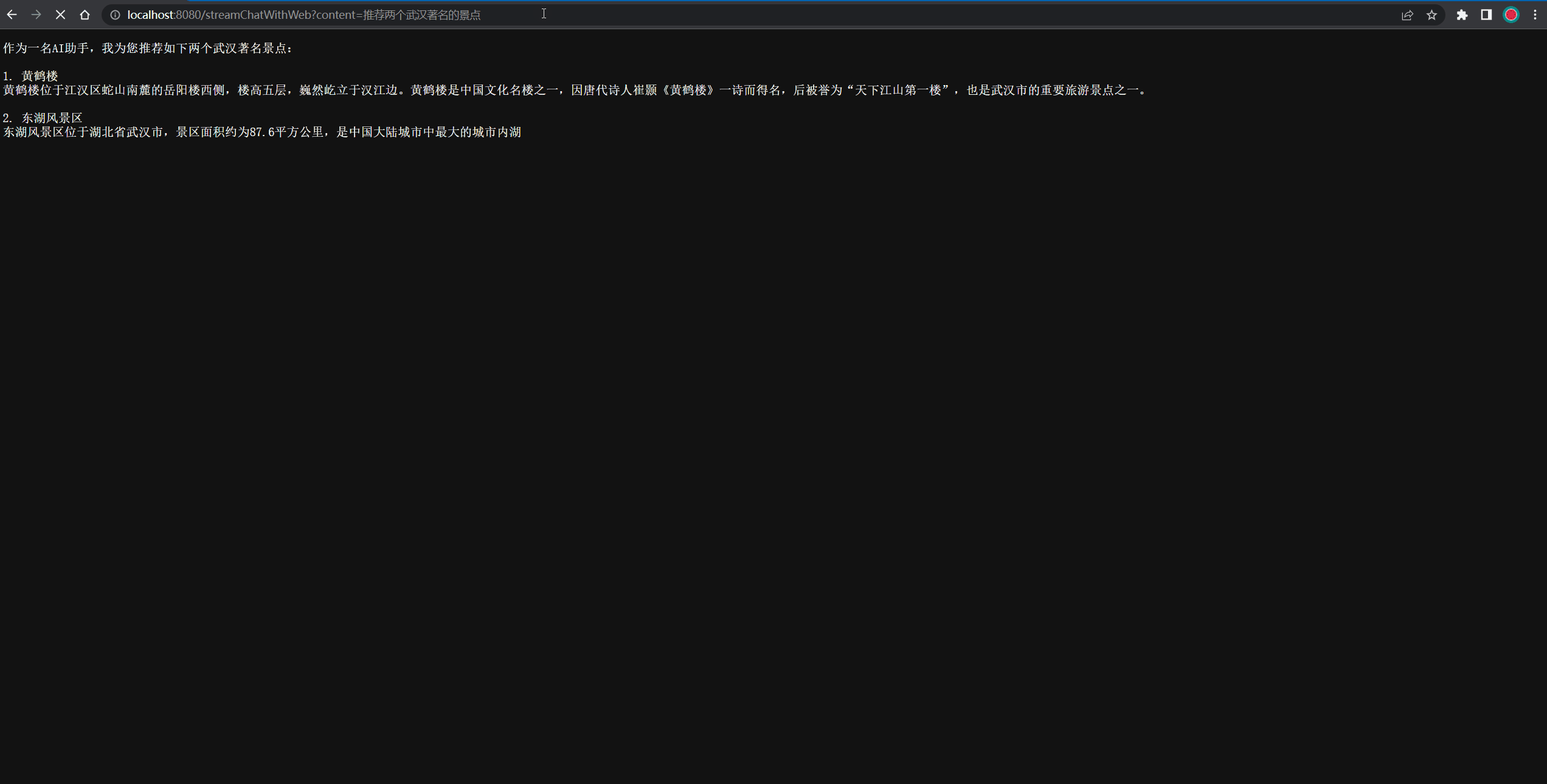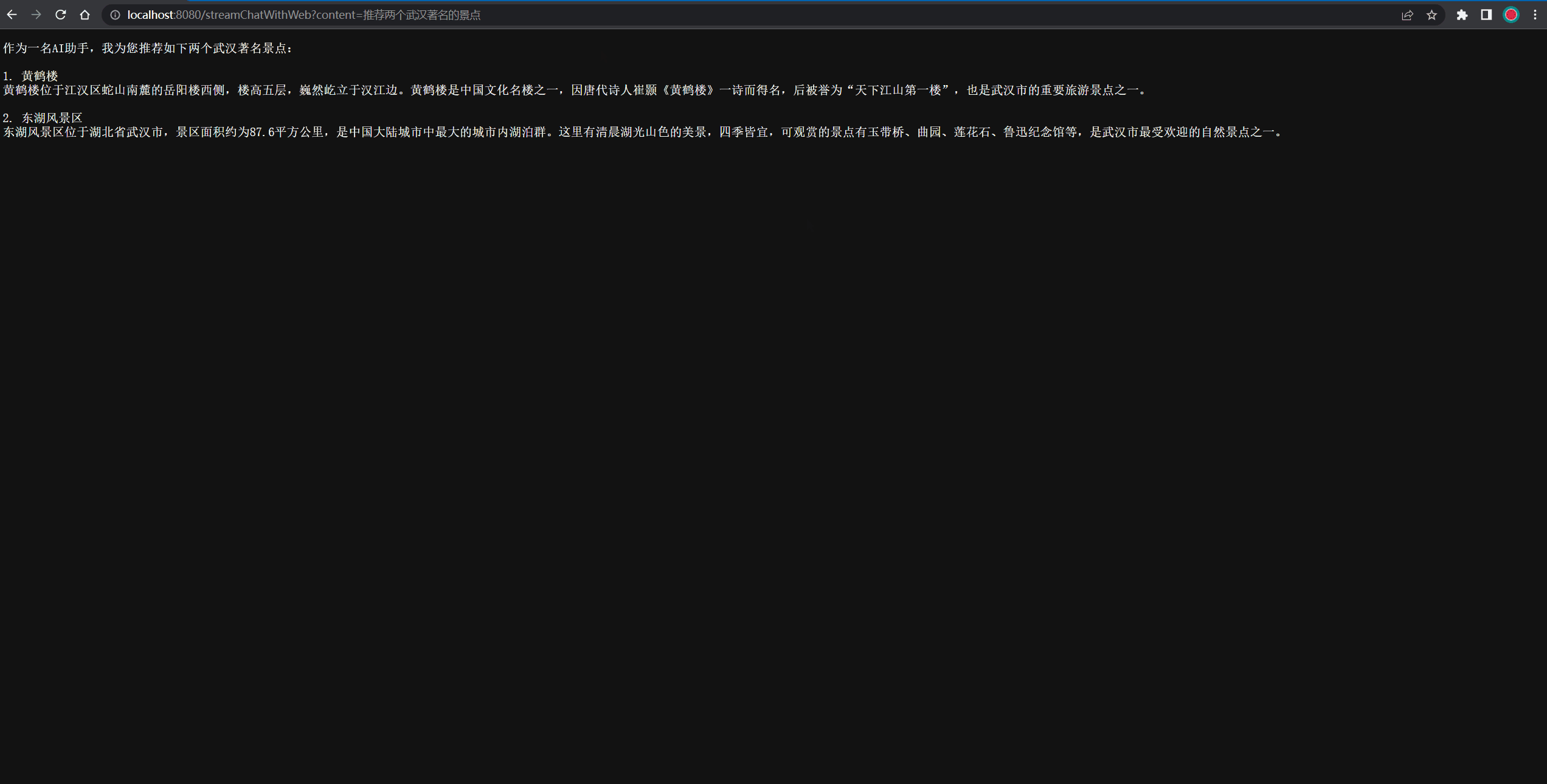
@GetMapping("/streamChatWithWeb")
public void streamChatWithWeb(String content, HttpServletResponse response) throws IOException {// 需要指定response的ContentType为流式输出,且字符编码为UTF-8response.setContentType("text/event-stream");response.setCharacterEncoding("UTF-8");OpenAiUtils.createStreamChatCompletion(content, response.getOutputStream());
}
测试结果过程的Gif图如下所示:
3 AI助手展示
接入微信公众号,AI助手可自动回复。
本文链接:https://my.lmcjl.com/post/12059.html
4 评论