过去十年中,通过“深度学习+大算力”从而获得训练模型是实现人工智能的主流技术途径。由于深度学习、数据和算力这三个要素都已具备,全世界掀起了“大炼模型”的热潮,也催生了大批人工智能企业。
大模型是人工智能的发展趋势和未来
大模型,又称为预训练模型、基础模型等,是“大算力+强算法”结合的产物。大模型通常是在大规模无标注数据上进行训练,学习出一种特征和规则。基于大模型进行应用开发时,将大模型进行微调,如在下游特定任务上的小规模有标注数据进行二次训练,或者不进行微调,就可以完成多个应用场景的任务。
迁移学习是预训练技术的主要思想。当目标场景的数据不足时,首先在数据量庞大 的公开数据集上训练基于深度神经网络的 AI 模型,然后将其迁移到目标场景中,通 过目标场景中的小数据集进行微调,使模型达到需要的性能。在这一过程中,这种在公开数据集训练过的深层网络模型,即为“预训练模型”。使用预训练模型很大程度上降低了下游任务模型对标注数据数量的要求,从而可以很好地处理一些难以获得大量标注数据的新场景。大模型正是人工智能发展的趋势和未来。

ChatGPT是大模型的直接产品
单点工具往往是基于大模型产生的能实际应用的产品。ChatGPT就是在GPT-3.5模型的基础上,产生出的能“对话”的AI系统。
2022年11月30日, OpenAI发布ChatGPT,一款人工智能技术驱动的自然语言处理工具,能够通过学习和理解人类的语言来进行对话和互动,甚至能完成撰写邮件、视频脚本、文案、翻译、代码等任务。ChatGPT对搜索领域或带来巨大冲击。由于ChatGPT能够与用户进行交流明确需求并具备文本生成能力进行回复,其相对于传统搜索引擎在输入端和输出端都具有难以替代的优势。
因而ChatGPT可能对搜索带来一个重大变化:用户将会转向聊天机器人寻求帮助,而不是通过谷歌提供的网站进行过滤。同时,技术上,ChatGPT也可能会降低搜索引擎的门槛。可以说,ChatGPT已经真真切切地改变了搜索领域,对众多科技公司产生了巨大的挑战。
AI大模型里程碑式的胜利
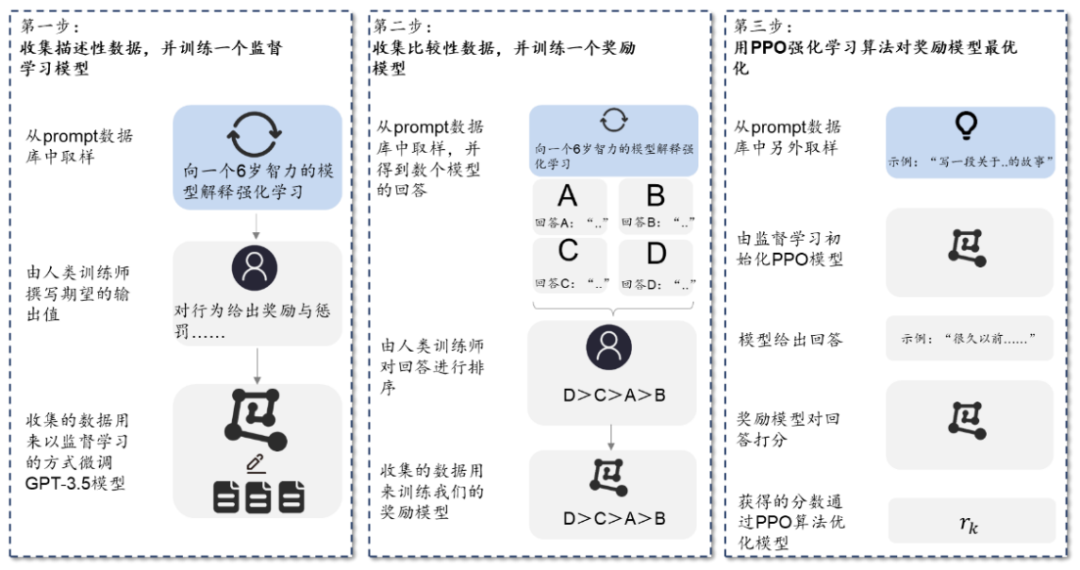
ChatGPT采用监督学习+奖励模型进行语言模型训练。ChatGPT使用来自人类反馈的强化 学习 (RLHF) 来训练该模型。首先使用监督微调训练了一个初始模型:人类AI训练员提供对话,他们在对话中扮演双方——用户和AI助手。其次,ChatGPT让标记者可以访问模型编写的建议,以帮助他们撰写回复。最后,ChatGPT将这个新的对话数据集与原有数据集混合,将其转换为对话格式。具体来看,主要包括三个步骤:
资料来源:OpenAI 官网、华泰研究
1)第一阶段:训练监督策略模型。在ChatGPT模型的训练过程中,需要标记者的参与监 督过程。首先,ChatGPT会从问题数据集中随机抽取若干问题并向模型解释强化学习机制, 其次标记者通过给予特定奖励或惩罚引导AI行为,最后通过监督学习将这一条数据用于微调GPT3.5模型。
2)第二阶段:训练奖励模型。这一阶段的主要目标,在于借助标记者的人工标注,训练出合意的奖励模型,为监督策略建立评价标准。训练奖励模型的过程同样可以分为三步:1、抽样出一个问题及其对应的几个模型输出结果;2、标记员将这几个结果按质量排序;3、将排序后的这套数据结果用于训练奖励模型。
3)第三阶段:采用近端策略优化进行强化学习。近端策略优化(Proximal Policy Optimization)是一种强化学习算法,核心思路在于将Policy Gradient中On-policy的训练过程转化为Off-policy,即将在线学习转化为离线学习。具体来说,也就是先通过监督学习策略生成PPO模型,经过奖励机制反馈最优结果后,再将结果用于优化和迭代原有的PPO模型参数。往复多次第二阶段和第三阶段,从而得到参数质量越来越高的ChatGPT模型。
ChatGPT离不开大算力支持
大模型训练需要大算力支持,ChatGPT坐拥丰富算力资源。从大模型自身的发展过程来看,参数量的变化是一个非常值得关注的指标。从最早的ResNet、Inception等模型,到如今的GPT,模型参数量不断增长。2018年前后OpenAI先后推出Transformer和GPT-1模型,参数量来到1亿级别。随后谷歌提出3亿参数的BERT模型,参数量再次增长。2019、2020年OpenAI加速追赶,陆续迭代出GPT-2、GPT-3模型,参数量分别为15亿、1750亿,实现模型体量质的飞跃。另一方面,参数运算需要大规模并行计算的支持, 核心难点在于内存交换效率,取决于底层GPU内存容量。
OpenAI预计人工智能科学研究要想取得突破,所需要消耗的计算资源每3~4个月就要翻一倍,资金也需要通过指数级增长获得匹配。
在算力方面,GPT-3.5在微软Azure AI超算基础设施(由GPU组成的高带宽集群)上进行训练,总算力消耗约3640PF-days(即每秒一千万亿次计算,运行3640天)。
在大数据方面,GPT-2用于训练的数据取自于Reddit上高赞的文章,数据集共有约800万篇文章,累计体积约40G;GPT-3模型的神经网络是在超过45TB的文本上进行训练的,数据相当于整个维基百科英文版的160倍。
按照量子位给出的数据,将一个大型语言模型(LLM)训练到GPT-3级的成本高达460万美元。
就ChatGPT而言,需要TB级的运算训练库,甚至是P-Flops级的算力。需要7~8个投资规模30亿、算力500P的数据中心才能支撑运行。就目前的服务器处理能力来看,大概是几十到几百台GPU级别的服务器的体量才能够实现,而且需要几日甚至几十日的训练,它的算力需求非常惊人。
国内布局ChatGPT引爆算力需求
随着ChatGPT火遍全球,国内互联网厂商陆续布局ChatGPT类似产品,或将加大核心城市IDC算力供给缺口。据艾瑞咨询,2021年国内IDC行业下游客户占比中,互联网厂商居首位,占比为60%;其次为金融业,占比为20%;政府机关占比10%,位列第三。而目前国内布局ChatGPT类似模型的企业同样以互联网厂商为主,如百度宣布旗下大模型产品“文心一言”将于2022年3月内测、京东于2023年2月10日宣布推出产业版ChatGPT:ChatJD。另一方面,国内互联网厂商大多聚集在北京、上海、深圳、杭州等国内核心城市,在可靠性、安全性及网络延迟等性能要求下,或将加大对本地IDC算力需求,国内核心城市IDC算力供给缺口或将加大。
而与需求相对应的是,我国智能算力规模保持快速增长。IDC报告显示,2022年人工智能算力规模达到每秒268百亿亿次浮点运算,超过通用算力规模,预计未来5年中国人工智能算力规模的年复合增长率将达52.3%。
在此背景下,随着国内厂商相继布局ChatGPT类似模型,算力需求或将持续释放,对于承接ChatGPT引爆的算力需求,思腾合力早有布局。
思腾合力一直专注于人工智能领域,提供云计算、AI服务器、AI工作站、系统集成、产品定制、软件开发、边缘计算等产品和整体解决方案,致力于成为行业领先的人工智能基础架构解决方案商。2021年,思腾合力乘势打造人工智能产业园,承接京津冀一体化乃至全国AI智能高科技企业入驻,通过资源整合、创新创业,打造AI智能产业链聚集区。
公司深耕高性能计算领域多年,已经打造出了一套完全自主软硬件结合的产品生态。全面覆盖云、边、端各层级算力需求,激活数据活力,充分释放数字潜能。对于ChatGPT推动的AI开发范式的转变。思腾合力将充分发挥IT架构优势,提升对数据价值的挖掘能力,支撑新旧范式的结合与转换。
思腾合力将在算力服务上持续精进,充分承接中国ChatGPT产品的算力需求,相辅相成,互相成就,聚力造就中国AI产业的大发展。
本文链接:https://my.lmcjl.com/post/12237.html
4 评论