学习目标:算法学习-Day16 题库: 洛谷题库 每天保持发布一篇Java或C算法题解! 题目: 给定一个数组,输出其中第二小的整数(相等的整数只计算一次)。 输入格式: 第一行,一个整数 n(1≤n≤100),表示数组长度。 第二行,n 个绝对值小于 100 的整数。 输出格式: 一行。如果该数组存在第二小整数,则输出 继续阅读
Search Results for: 算法成长之路
查询到最新的12条
算法程序设计 之 循环赛日程表(2/8)
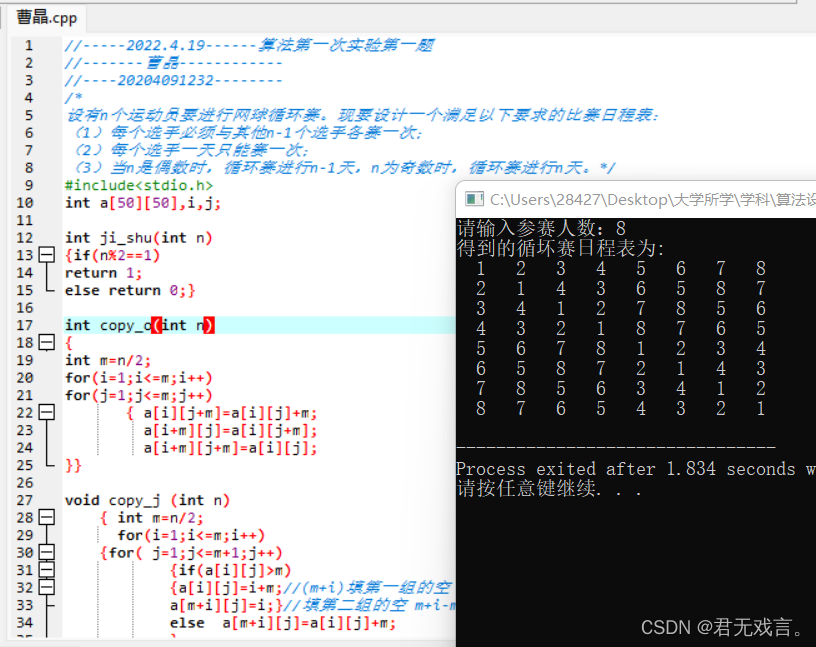
一、实验目的: 理解并掌握分治算法的基本思想和设计步骤。 二、实验内容 设有n个运动员要进行网球循环赛。现要设计一个满足以下要求的比赛日程表: (1)每个选手必须与其他n-1个选手各赛一次; (2)每个选手一天只能赛一次; (3)当n是偶数时,循环赛进行n-1天,n为奇数时,循环赛进行n天。 程序代码࿱ 继续阅读
与其降低你的开支,不如去尝试增加你的收入!

无论是短视频还是朋友圈,算法不断的给我推荐焦虑、裁员、失业、优化、淘汰等话题,我有时候做梦也会梦到失业,醒了之后发现,我已经失业11个月了。失业不代表没有工作可做,失业也不代表没有收入来源,逐步成为非常规劳动者,才是我们的出路之一,跳出固化的圈子之后,不再讨论工资,也不再扯升职。更多是去讨论机会,是未来和保障。在更换了新的赛道后,一开始,根本没想到自己能坚持这么久,我从没有给自己定的目标,就是一个随心所欲的过程。每期作品都能见证自己的成长,也能帮助到更多的粉丝,也能产生还不错的收 继续阅读
Java中Lambda表达式的进化之路详解
目录 Lambda表达式的进化之路 为什么要使用Lambda表达式 Lambda表达式的注意点 下面是Lambda表达式的实现过程 1.最开始使用的是定义外部实现类来完成接口 2.开始使用静态内部类来实现 3.使用局部内部类使用 继续阅读
RSA加密算法Python实现
本文将从RSA加密算法的基本原理、Python实现RSA加密算法的步骤、实现过程中可能出现的问题、代码示例等多个方面对RSA加密算法Python实现进行详细阐述。 一、RSA加密算法基本原理 RSA加密算法是一种公钥加密算法,由三位数学家Rivest、Shamir和Adleman于1978年提出,RSA算法是目前最流行的公钥加密算法之一。它的安全性基于大数质因数分解的难度。 RSA的基本原理如下: 选择两个大质数p,q。 计算N=p*q。 计算phi(N)= 继续阅读
搜索神器Perplexity的详细使用方法(持续更新)
大家好,我是herosunly。985院校硕士毕业,现担任算法研究员一职,热衷于机器学习算法研究与应用。曾获得阿里云天池比赛第一名,科大讯飞比赛第三名,CCF比赛第四名。拥有多项发明专利。对机器学习和深度学习拥有自己独到的见解。曾经辅导过若干个非计算机专业的学生进入到算法行业就业。希望和大家一起成长进步。 本文主要介绍了Perplexity的详细使用方法,希望对新手有所帮助。需要说明的是,Perplexity不需要上网工具,很方便新手和小白上手使用。Perplexity的官网链接为:h 继续阅读
基于改进多目标灰狼优化算法的考虑V2G技术的风、光、荷、储微网多目标日前优化调度研究(Matlab代码实现)

💥1 概述 多目标优化表示对具备多个目标函数的问题的优化。通常的,可以将其表述为 最大化问题如下: 为了利用灰狼优化算法执行多目标优化,需要集成了两个新的部分[63]。第一个是外部存档,它负责存储到目前为止获得的非支配的 Pareto 最优解。第二个组成部分是领导者选择策略,有助于选择 α,β 和 δ 解决方案作为存档中狩猎过程的领导者。 (1)外部存档 外部存 继续阅读
什么是雪花算法?啥原理?

1、SnowFlake核心思想 SnowFlake 算法,是 Twitter 开源的分布式 ID 生成算法。 其核心思想就是:使用一个 64 bit 的 long 型的数字作为全局唯一 ID。在分布式系统中的应用十分广泛,且 ID 引入了时间戳,基本上保持自增的,后面的代码中有详细的注解。 这 64 个 bit 中,其中 1 个 bit 是不用的,然后用其中的 41 bit 作为毫秒数 继续阅读
奇舞周刊第486期:ChatGPT 的狂飙之路

奇舞推荐■ ■ ■ ChatGPT 的狂飙之路最近随着 ChatGPT 爆火出圈,网络上各种关于 ChatGPT 的争论声也不断;有些人把它当成一个更高级的聊天机器人,有人兴奋地看到了创业的风口,而另一些人对它取代人类的工作露出了不少担忧;那么它到底是推动社会不断前进的工具,还是妄图颠覆人类社会的 T-1000?本文我们来深入的探讨一下 ChatGPT 的那些事。 带你看看前端生态圈的技术趋势今年的 继续阅读
ChatGPT 使用 强化学习:Proximal Policy Optimization算法(详细图解)
ChatGPT 使用 强化学习:Proximal Policy Optimization算法 强化学习中的PPO(Proximal Policy Optimization)算法是一种高效的策略优化方法,它对于许多任务来说具有很好的性能。PPO的核心思想是限制策略更新的幅度,以实现更稳定的训练过程。接下来,我将分步骤向您介绍PPO算法。 步骤1:了解强化学习基础 首先,您需要了解强化学习的基本概念,如状态(state)、动作(action)、奖励(reward)、策略(policy)和价值函 继续阅读
【MATLAB第42期】基于MATLAB的贝叶斯优化决策树分类算法与网格搜索、随机搜索对比,含对机器学习模型的
【MATLAB第42期】基于MATLAB的贝叶斯优化决策树分类算法与网格搜索、随机搜索对比,含对机器学习模型的评估度量介绍 网格搜索、随机搜索和贝叶斯优化是寻找机器学习模型参数最佳组合、交叉验证每个参数并确定哪一个参数具有最佳性能的常用方法。 一、 评估指标 1、分类 1.1 准确性 1.2 精度 1.3 召回 1.4 F1值 1.5 F0.5值 1.6 F2值 1.7 计算评估指标的功能 2、回归 2.1 平均绝对误差 2.2 均方误差 2.3 均方根误差 二、 基于F1值执 继续阅读
java实现LRU缓存淘汰算法的方法
LRU算法:最近最少使用淘汰算法(Least Recently Used)。LRU是淘汰最长时间没有被使用的缓存(即使该缓存被访问的次数最多)。 如何实现LRU缓存淘汰算法 场景: 我们现在有这么个真实场景,我在爬取某个网站时,控制该网站的代理IP并发数,太多会搞垮对方网站的对吧,要蹲号子的呢。这里我需要维护一个代理IP代理池,而且这些IP肯定不是一直都很稳定的,但是又不能取一个就丢一个,这样太浪费资源。所以我会将这些IP缓存起来,进行按需提取,采用LRU 继续阅读