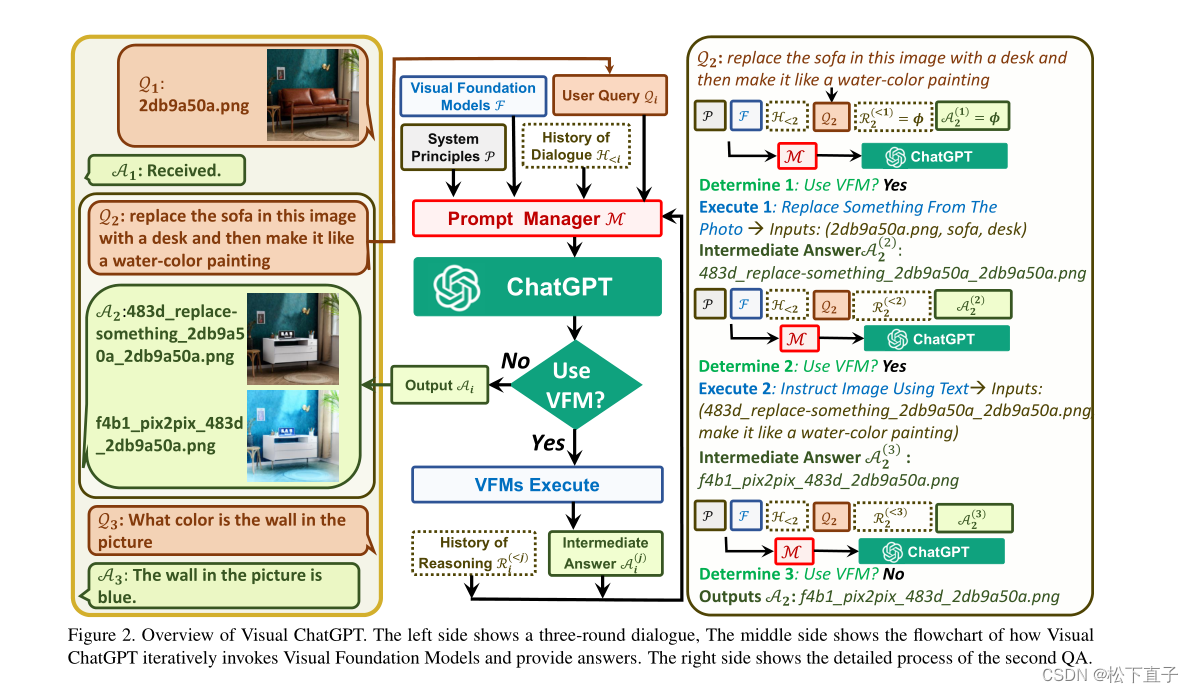
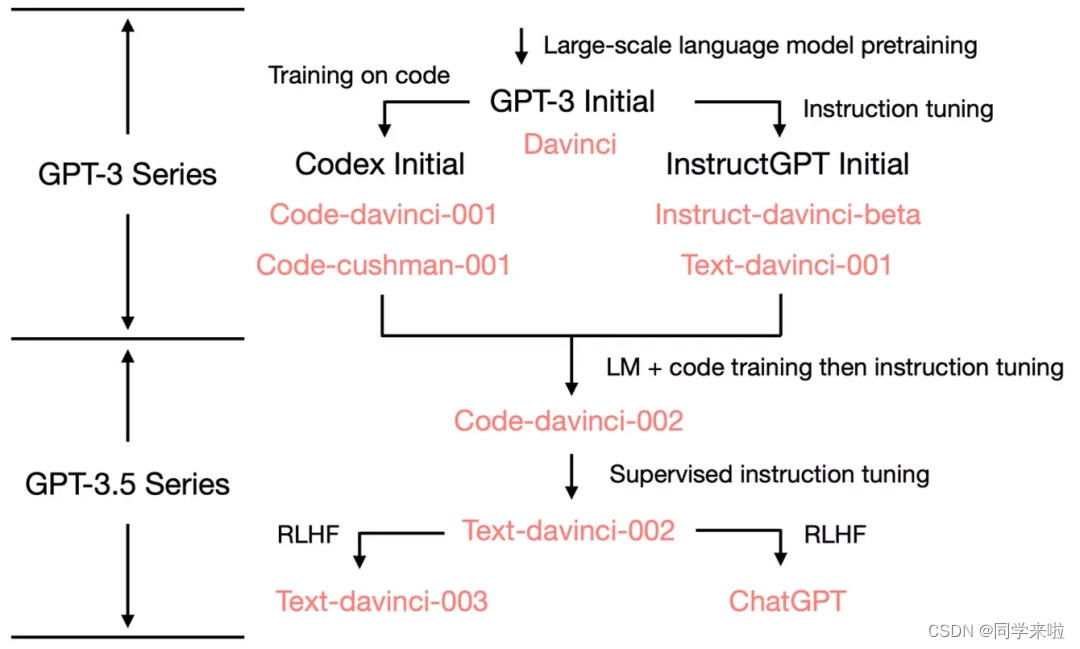
文章目录1.RLHF方法2.ChatGPT中的RLHF方法2.1 微调模型GPT-32.2 训练奖励模型2.3 利用强化学习进一步微调语言模型3.效果4.面临挑战5.参考 InstructGPT语言模型,是一个比 GPT-3 更善于遵循用户意图,同时使用通过我们的对齐研究开发的技术使它们更真实、毒性更小。InstructGPT 模型循环迭代的过程当中,加入了人类反馈进行训练。 比如下面的例子:几句话向6岁的孩子解析登月 可以看 继续阅读
ChatGPT背后的模型