文章目录
- 🐣 一、发展历程
- 🔴 1、基本概念
- 🟠 2、演化过程
- 🐤 二、模型训练机制
🐣 一、发展历程
🔴 1、基本概念
ChatGPT是一个采用基于GPT-3.5(Generative Pre-trained Transformer 3.5)架构开发的大型语言模型,与InstructGPT模型是姊妹模型(sibling model),使用了RLHF(Reinforcement Learning from Human Feedback,人类反馈强化学习)技术来更好地让语言模型与人类指令保持一致。
而GPT(Generative Pre-Trained Transformer)是一系列基于Transformer的深度学习语言模型,利用机器学习算法来分析和理解文本输入的含义,然后根据该输入生成响应。该模型在大量文本数据上进行训练,使其能够学习自然语言的模式和结构。
🟠 2、演化过程
-
🦐 GPT-1发布:
2018年6月,OpenAl 在题为《Improving Language Understanding by Generative Pre-Training》的论文中提出了第一个GPT 模型GPT-1。从这篇论文中得出的关键结论是,Transformer 架构与无监督预训练的结合产生了可喜的结果。GPT-1 以无监督预训练+有监督微调的方式,针对特定任务进行训练,实现了 “强大的自然语言理解”。 -
🦞 GPT-2发布:
2019年2月,OpenAI发表了第二篇论文《Language Models are Unsupervised Multitask Learners》,其中介绍了由GPT-1演变的GPT-2。尽管GPT-2 大了一个数量级,但它们在其他方面非常相似。两者之间只有一个区别:GPT-2 可以完成多任务处理。OpenAI成功地证明了半监督语言模型可以在“无需特定任务训练”的情况下,在多项任务上表现出色。该模型在零样本任务转移设置中取得了显著效果。 -
🦑 GPT-3发布:
2020年5月,OpenAI发表《Language Models are Few-Shot Learners》,呈现GPT-3。GPT-3 比GPT-2 大100 倍,它拥有1750 亿个参数。然而,它与其他GPT 并没有本质不同,基本原则大体一致。尽管GPT 模型之间的相似性很高,但GPT-3 的性能仍超出了所有可能的预期。 -
🦀 GPT-3.5 & ChatGPT发布:
2022年11月底,OpenAI进行了两次更新。11月29日,OpenAI发布了一个命名为“text-davinci-003”(文本-达芬奇-003”,通常称为GPT3.5)的新模式。11月30日,发布了它的第二个新功能:“对话”模式。它以对话方式进行交互,既能够做到回答问题,也能承认错误、质疑不正确的前提以及拒绝不恰当的请求。ChatGPT由效果更强大的GPT-3.5系列模型提供支持,可以用更接近人类的思考方式参与用户的查询过程。
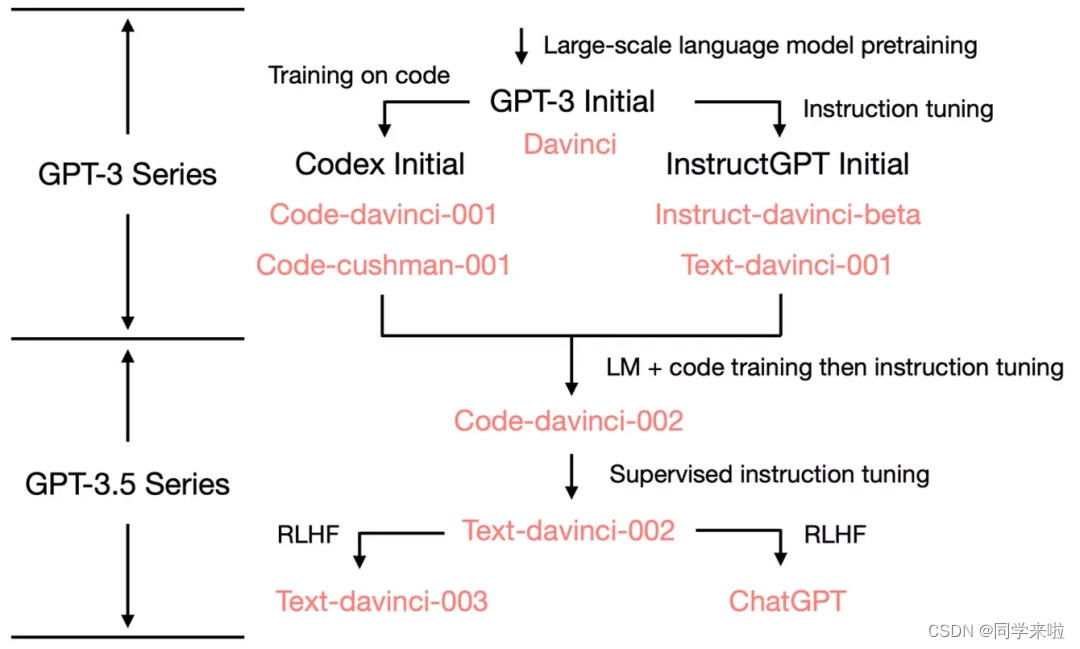
🐤 二、模型训练机制
-
第1️⃣步:使用有监督的微调训练初始模型:人类训练师之间提供对话,其中一个扮演用户,另一个扮演ChatGPT中的Al助手。为了创建强化学习的奖励模型,需要收集比较数据,并使用收集到的数据调整GPT-3.5模型;
-
第2️⃣步:模型会根据提示生成多个输出,训练师将ChatGPT编写的回复与人类的回答进行比较,并对它们的质量进行排名,以帮助强化机器的类人对话风格。奖励模型将自动执行最后一个训练阶段,使用排名后的数据训练;
-
第3️⃣步:在最后一步使用近端策略优化进一步调整,这是OpenAl广泛使用的强化学习技术。
本文链接:https://my.lmcjl.com/post/8416.html
4 评论