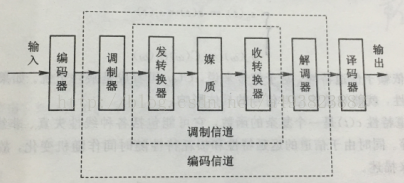
一、信道的定义与调制信道的数学模型 1.信道的定义与分类 信道(Channel)是指以传输媒质为基础的信号通道。根据新到的定义,如果信道仅是指信号的传输媒质,这种信道称为狭义信道;如果这种信道不仅是传输媒质,而且包括通信系统中的转换装置,这种信道称为广义信道。 狭义信道按照传输媒质的特性可分为有线信道和无线信道。有线信道包括对称电缆、同轴电缆及光纤等。无线信道包括地波传播、短波电离层反射、超短 继续阅读
瑞利、莱斯与Nakagami-m信道衰落模型