爬取目标站点分析 本次采集的目标站点为:https://www.zaih.com/falcon/mentors,目标数据为在行高手数据。 本次数据保存到 MySQL 数据库中,基于目标数据,设计表结构如下所示。 对比表结构,可以直接将 scrapy 中的 items.py 文件编写完毕。 class ZaihangItem(scrapy.Item): # define the fields for your item he 继续阅读
python实战项目scrapy管道学习爬取在行高手数据
查询到最新的12条
爬取目标站点分析 本次采集的目标站点为:https://www.zaih.com/falcon/mentors,目标数据为在行高手数据。 本次数据保存到 MySQL 数据库中,基于目标数据,设计表结构如下所示。 对比表结构,可以直接将 scrapy 中的 items.py 文件编写完毕。 class ZaihangItem(scrapy.Item): # define the fields for your item he 继续阅读
目录 拆解 scrapy.Spider scrapy.Spider 属性值 scrapy.Spider 实例方法与类方法 爬取优设网 Field 字段的两个参数: 拆解 scrapy.Spider 本次采集的目标站点为:优设网 每次创建一个 spider 文件之后,都会默认生成如下代码: 继续阅读
编程书籍推荐:解析Python网络爬虫:核心技术、Scrapy框架、分布式爬虫,由中国铁道出版社2018-08-01月出版,本书发行作者信息: 黑马程序员 著此次为第1次发行, 国际标准书号为:9787113246785,品牌为中国铁道出版社, 这本书采用平装开本为16开,附件信息:未知,纸张采为胶版纸,全书共有272页字数万 字,值得推荐的Python Book。此书内容摘要 网络爬虫是一种按照一定的规则,自动请求万维网网站并提取网络数据的程序或脚本,它可以代替人 继续阅读
如何在项目中学习 前言编程思维react上手通用业务逻辑与解决方案jwt登录认证注册避免重复注册加密存储图片优化 非预期问题排查与经验积累组件非预期更新文件写入不全axios会删除get请求头中的Content-Type数据类型一致很重要 代码段优化如果某个配置想要获取外部参数,用函数大多数情况下更新和添加逻辑可复用尽可能让常量有统一入口请求retry批量处理应该是单接口的批量而不是请求的批量充分利用异步能力,不需要await的就不要await保证函数独立性&# 继续阅读
互联网赚钱极其简单 悟透了其中最质朴的底层逻辑 赚钱就像喝水吃饭一样成为你的本能 比如市面上出一个项目,我立马去百度,去知乎,去淘宝,去京东,去用微信搜一搜,去哔哩哔哩(b站)去这些地方干嘛! 抓取全部资料进行分析! 如果此项目有门槛,那么我会付费拜师,抓取师傅资料!如果门槛更高,我会批量拜师,批量抓取师傅资料! 同时我会借助搜索技能,加无数个同行,加有成功结果的同行进行学习! 在互联网上项目从来不重要,如果你悟透了我 继续阅读
Python编程从入门到精通 项目开发视频学习版,由人民邮电出版社在2018-11-01月出版发行,本书编译以及作者信息为: 叶维忠 著,这是第1次发行, 国际标准书号为:9787115478801,品牌为异步图书, 这本书采用平装开本为16开,纸张采为胶版纸,全书共有429页,字数万字,值得推荐。 此书内容摘要 本书循序渐进、由浅入深地详细讲解了Python语言开发技术,并通过具体实例演练了各个知识点的具体使用流程。全书共23章,其中第1~2章是基础知识部分,讲解 继续阅读

文章目录前言一、chatgpt是什么?二、用例三、项目展示总结 前言 随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,博主挖掘了一个 chatgpt + 飞书 的一个开源项目,可直接部署学习使用。 一、chatgpt是什么? ChatGPT是OpenAI开发的一个大型预训练语言模型。是一种基于神经语言处理技术来生成聊天机器人的语料库, 继续阅读
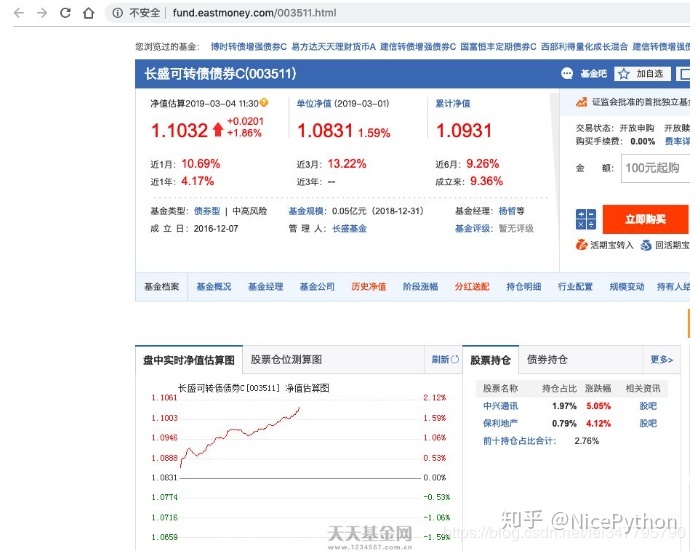
接口分析爬数据需要先思考从哪里爬?经过一番搜索和考虑,我发现天天基金网的数据既比较全,又十分容易爬取,所以就从它入手了。首先,随便点开一支基金,我们可以看到域名就是该基金的代码,十分方便,其次下面有生成的净值图。 基金详情打开chrome的开发者调试,选择Network,然后刷新一下,很快我们就能发现我们想要的东西了。可以看到,这 继续阅读
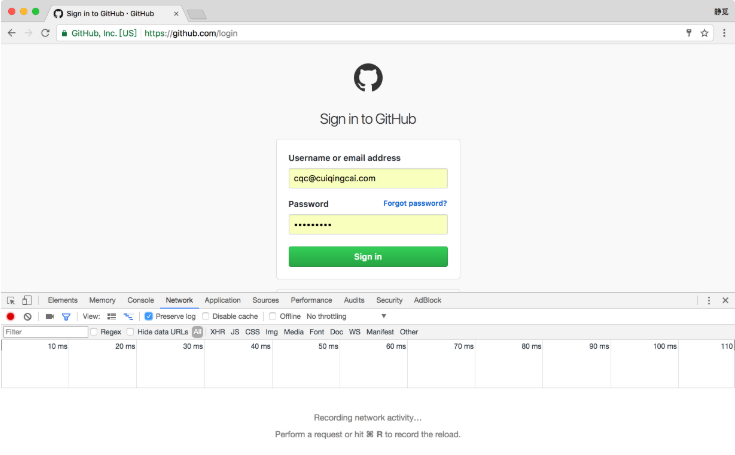
我们先以一个最简单的实例来了解模拟登录后页面的抓取过程,其原理在于模拟登录后 Cookies 的维护。 1. 本节目标 本节将讲解以 GitHub 为例来实现模拟登录的过程,同时爬取登录后才可以访问的页面信息,如好友动态、个人信息等内容。 我们应该都听说过 GitHub,如果在我们在 Github 上关注了某些人,在登录之后就会看到他们最近的动态信息,比如他们最近收藏了哪个 Repository,创建了哪个组织,推送了哪些代码。但是退出登录之后,我们就无 继续阅读
前几天学校一个老师在做微博的舆情分析找我帮她搞一个用关键字爬取微博的爬虫,再加上最近很多读者问志斌微博爬虫的问题,今天志斌来跟大家分享一下。 一、分析页面 我们此次选择的是从移动端来对微博进行爬取。移动端的反爬就是信息校验反爬虫的cookie反爬虫,所以我们首先要登陆获取cookie。 登陆过后我们就可以获取到自己的cookie了,然后我们来观察用户是如何搜索微博内容的。 平时我们都是在这个地方输入关键字,来进行搜索微博。 继续阅读
作为一个初级程序员,想要通过兼职接单赚钱,离不开项目练手。但不得不说,初级程序员想要通过接私活获取收入还是相对比较困难的,如果对接私活比较感兴趣的朋友,可以参考这条路径: 在GitHub上学习大佬的项目 程序员在工作中的环境是比较闭塞的,一般来说接触的产品和框架有限,而想要去接项目,则需要有丰富的大量的经验,且能迅速且准确地实现需求商所需要的各项功能。 继续阅读

知识点介绍 本次爬取用到的知识点有: 1. selenium 2. pymysql 3 pyquery 实现步骤 1. 分析目标网站 1. 打开某宝首页, 输入"男装"后点击"搜索", 则跳转到"男装"的搜索界面. 2. 空白处"右击"再点击"检查"审查网页元素, 点击"Network&quo 继续阅读