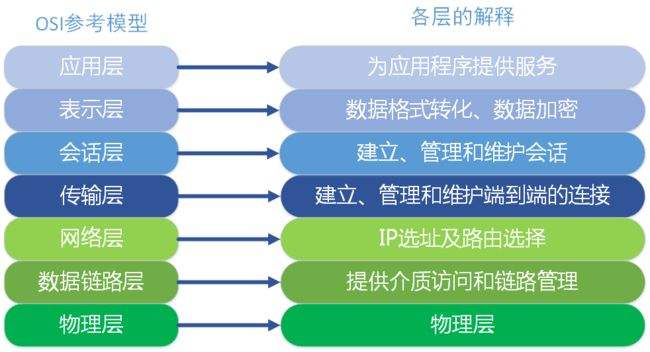
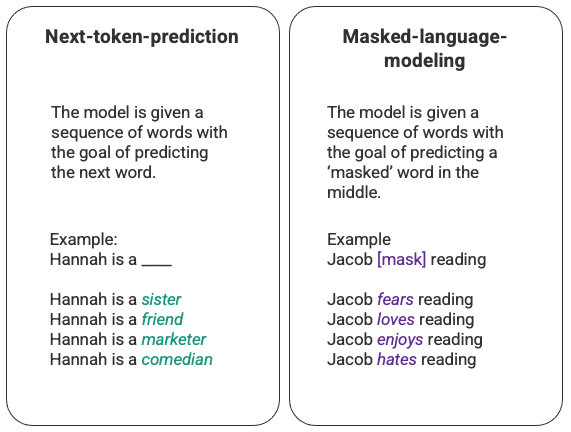
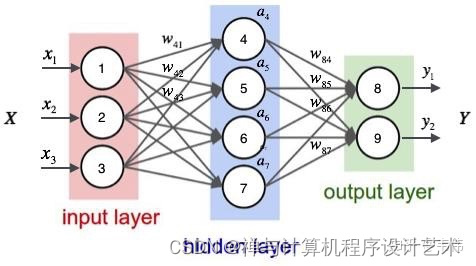
前言 ChatGPT基本信息&原理 ChatGPT基本信息 研发公司:OpenAI 创立年份:2015年 创立人:马斯克、Sam Altman及其他投资者 目标:造福全人类的AI技术 GPT(Generative Pre-trained Transformer):生成式预训练语言模型 GPT作用:问答,生成文章等 模型发展史 参数量(单位:亿) 预训练数据量( 继续阅读
人工智能大模型之ChatGPT原理解析