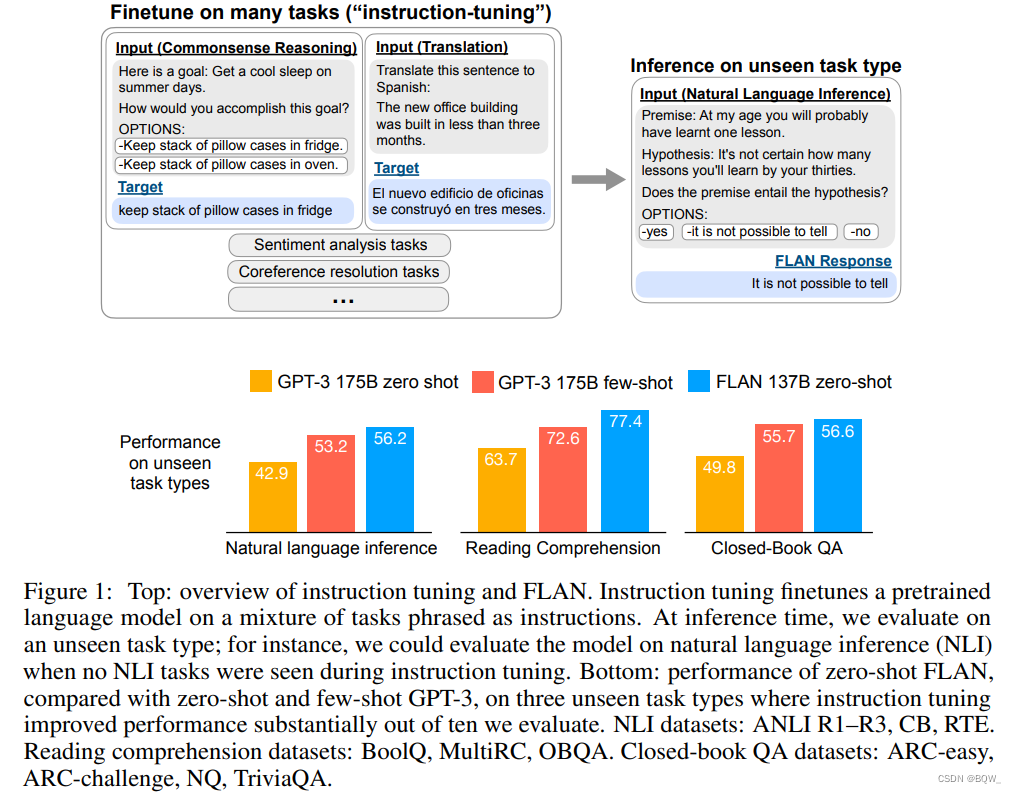
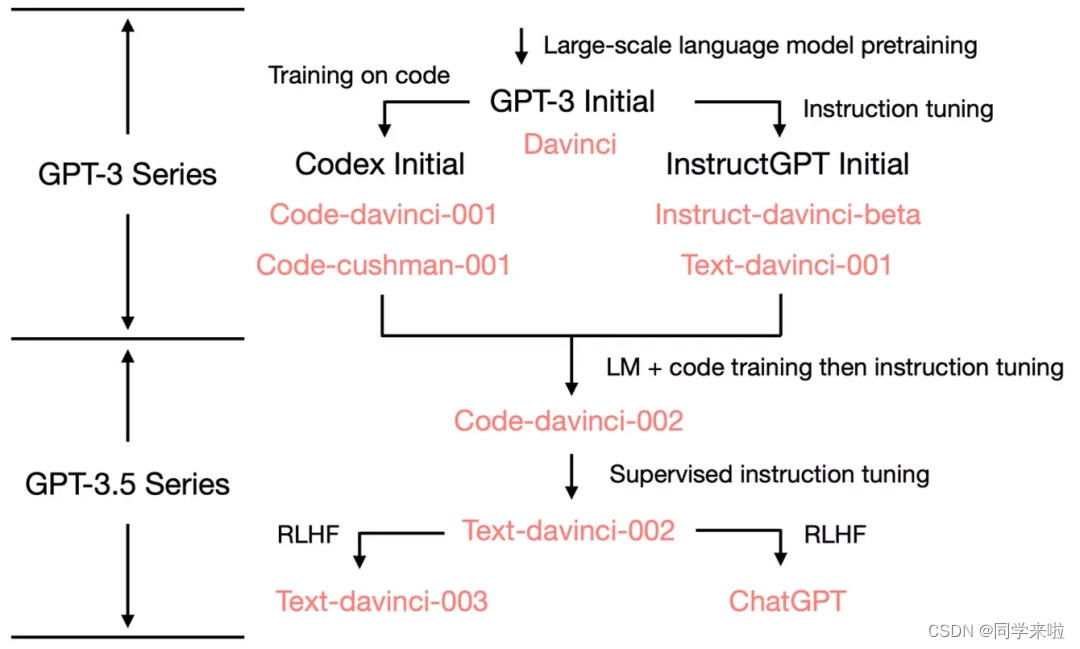
简介 随着数据科学领域的深入发展,大型语言模型—这种能够处理和生成复杂自然语言的精密人工智能系统—逐渐引发了更大的关注。 LLMs是自然语言处理(NLP)中最令人瞩目的突破之一。这些模型有潜力彻底改变从客服到科学研究等各种行业,但是人们对其能力和局限性的理解尚未全面。 LLMs依赖海量的文本数据进行训练,从而能够生成极其准确的预测和回应。像GPT-3和T5这样的LLMs在诸如语言翻译、问答、以及摘要等多个NLP任务中已经 继续阅读
深入解析大型语言模型:从训练到部署大模型