编程书籍推荐:神经网络与深度学习:基于TensorFlow框架和Python技术实现,由电子工业出版社2019-04-01月出版,本书发行作者信息: 包子阳 著此次为第1次发行, 国际标准书号为:9787121362019,品牌为电子工业出版社, 这本书采用平装开本为16开,附件信息:未知,纸张采为胶版纸,全书共有196页字数28万 0000字,值得推荐的Python Book。此书内容摘要Python、TensorFlow、神经网络和深度学习因人工智能的流行而成为当下I 继续阅读
Search Results for: 白话深度学习与Tensorflow
查询到最新的12条
深度学习入门 基于Python的理论与实现
推荐编程书籍:深度学习入门 基于Python的理论与实现,由人民邮电出版社2018-07-01月出版发行,本书编译以及作者信息 为:斋藤康毅 著,陆宇杰 译,此次为第1次发行, 国际标准书号为:9787115485588,品牌为人民邮电出版社, 这本书采用平装开本为大32开,纸张采为胶版纸,全书共有285页字数万字,是本Python 编程相关非常不错的书。此书内容摘要 本书是深度学习真正意义上的入门书,深入浅出地剖析了深度学习的原理和相关技术。书中使用Python3 继续阅读
【ChatGPT】大模型深度学习系统科学的视角——“大模型”深度学习是结构与组合的艺术 Deep learni
大模型深度学习:系统科学的视角 目录 大模型深度学习:系统科学的视角 1,系统科学 2,大模型-深度神经 继续阅读
最新基于MATLAB 2023a的机器学习、深度学习实践应用
MATLAB 2023版的深度学习工具箱,提供了完整的工具链,使您能够在一个集成的环境中进行深度学习的建模、训练和部署。与Python相比,MATLAB的语法简洁、易于上手,无需繁琐的配置和安装,能够更快地实现深度学习的任务。 MATLAB的深度学习工具箱提供了丰富的函数和算法,涵盖了从数据预处理到模型训练的全过程。可以轻松地导入和处理大规模数据集,利用批量导入和Datastore类函数高效地进行 继续阅读
深入理解深度学习——BERT(Bidirectional Encoder Representations fr

分类目录:《深入理解深度学习》总目录 BERT是由堆叠的Transformer Encoder层组成核心网络,辅以词编码和位置编码而成的。BERT的网络形态与GPT非常相似。简化版本的ELMo、GPT和BERT的网络结构如下图所示。图中的“Trm”表示Transformer Block,即基于Transformer的特征提取器。 ELMo使用自左向右编码和自右向左编码的两个LSTM网络,分别以 P ( w i ∣ w 1 , w 继续阅读
「多层感知机」手把手带你0基础学懂弄通多层感知机思路【深度学习】附源码及解析
「多层感知机」手把手带你0基础学懂弄通多层感知机【深度学习】附源码及解析 文章目录「多层感知机」手把手带你0基础学懂弄通多层感知机【深度学习】附源码及解析前言一、多层感知机是什么?二、预备知识1.模型组成(划重点)2、Fashion-MNIST数据集三、数据集预处理1、明确问题2、下载数据集四、多层感知机的简洁实现1、导入必要的库2、网络搭建3、确定批量大小、学习率、迭代次数4、确定损失函数5、确定优化器6、确定加载数据集方法7、实现8、 继续阅读
【深度学习】5-2 与学习相关的技巧 - 权重的初始值

在神经网络的学习中,权重的初始值特别重要。实际上,设定什么样的权重初始值,经常关系到神经网络的学习能否成功。本节将介绍权重初始值的推荐值,并通过实验确认神经网络的学习是否会快速进行。 可以将权重初始值设为0吗 后面我们会介绍抑制过拟合、提高泛化能力的技巧 —— 权值衰减。 权值衰减就是一种以减小权重参数的值为目的进行学习的方法。 如果想减小权重的值,一开始就将初始值设为较小的值才是正途。实际上在这之前的权重初始值都是像0. 继续阅读
ChatGPT协助配置环境(深度学习降尺度库dl4ds的安装)
最近在研究利用深度学习对气象数据进行降尺度的方法,偶然发现这一篇论文及其提及到的规范化降尺度库,便安装以供实验。GitHub - carlos-gg/dl4ds: Deep Learning for empirical DownScaling. Python package with state-of-the-art and novel deep learning algorithms for empirical/statistical downscaling of 继续阅读
【深度学习】5-5 与学习相关的技巧 - 超参数的验证
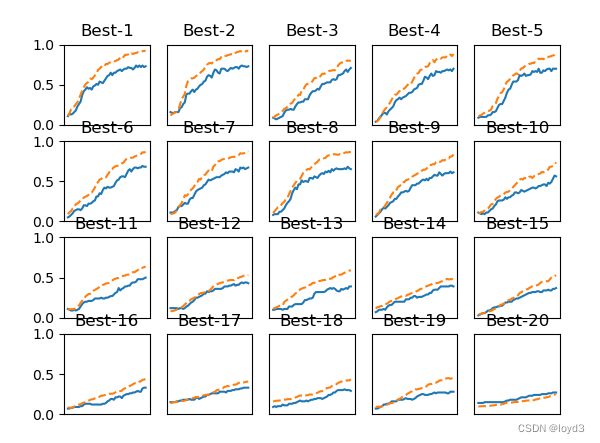
超参数指的是,比如各层的神经元数量、batch大小、参数更新时的学习率或权值衰减等。如果这些超参数没有设置合适的值,模型的性能就会很差。 那么如何能够高效地寻找超参数的值的方法 验证数据 之前我们使用的数据集分成了训练数据和测试数据,训练数据用于学习测试数据用于评估泛化能力。 下面要对超参数设置各种各样的值以进行验证。这里要注意的是不能使用测试数据评估超参数的性能。这一点非常重要,但也容易被忽视。为什么不能使用测试数据评估超参数的性能&# 继续阅读
中科院张家俊:ChatGPT中的提示与指令学习

中国科学院自动化研究所研究员张家俊以ChatGPT中的提示与指令学习为题,从ChatGPT简要技术回顾、迈向通用性的提示学习、从提示学习到指令学习、相关探索与学习等角度和在场听众展开技术分享。大模型主要有两个方向,一个是“预训练+参数微调”,就是大模型有了之后针对下游任务进行微调,然后得到一个面向下游任务的大的模型,二是“预训练+提示学习”,预训练之后不变,用提示学习激发大模型来 继续阅读
【人工智能】ChatGPT 技术架构与相关技术栈清单

ChatGPT 技术架构 ChatGPT是一种基于自然语言处理的神经网络模型,它使用了大量的未标注文本数据进行训练,并通过预测文本中下一个词的方式来自我监督。 文章目录 ChatGPT 技术架构自监督预训练模块预训练模型深度学习Transformer模型生成式模型微调模块注意力机制多头自注意力机制基于人类反馈的强化学习与PPO机制残差连接长短时记忆网络(LSTM)词嵌入(Embedding)多层感知器(MLP)梯度下降优化算法自注意力机制序列到序列模型 继续阅读
AI人工智能概念(机器学习,深度学习,强化学习)
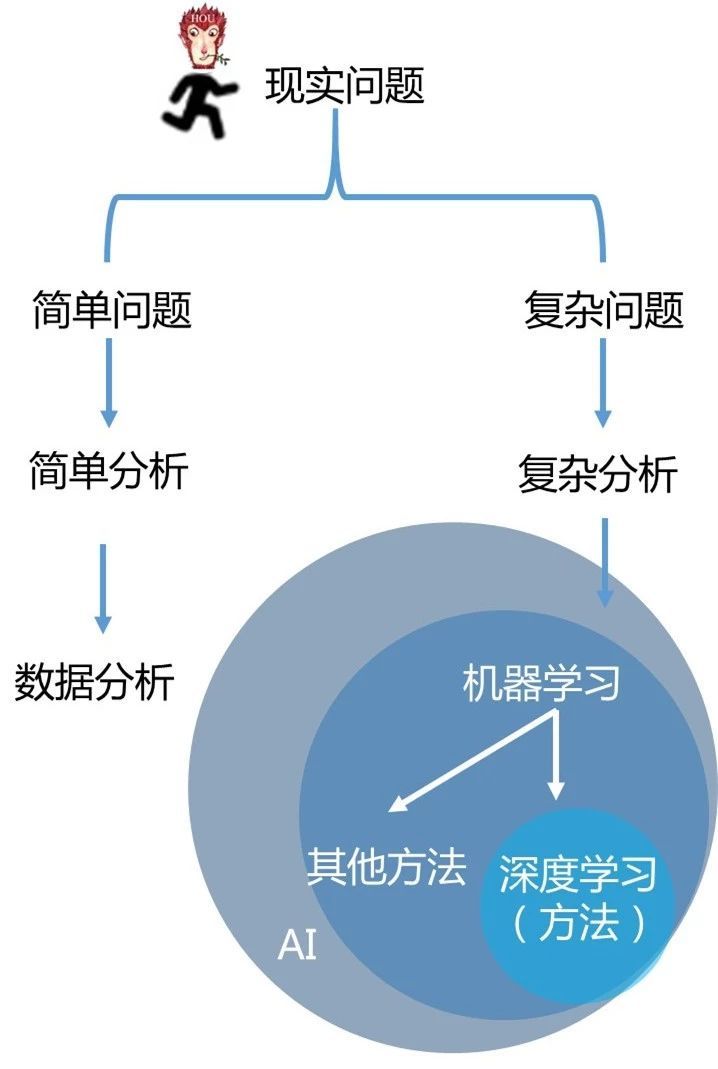
我们常常听到人工智能,机器学习,深度学习,神经网络,强化学习,图像识别,语音识别,自然语言处理等等诸多人工智能领域的词汇,今天我们就来梳理一下每个名词的概念以及他们的关系: 人工智能首先使用来解决问题的: 人工智能: 人工智能可以分为很多领域,如:自然语言理解,图像识别,语音识别 继续阅读