ChatGPT 拓展资料:ChatGPT 和预训练模型实战课 继续阅读
ChatGPT 拓展资料:ChatGPT 和预训练模型实战课

查询到最新的12条
ChatGPT 拓展资料:ChatGPT 和预训练模型实战课 继续阅读
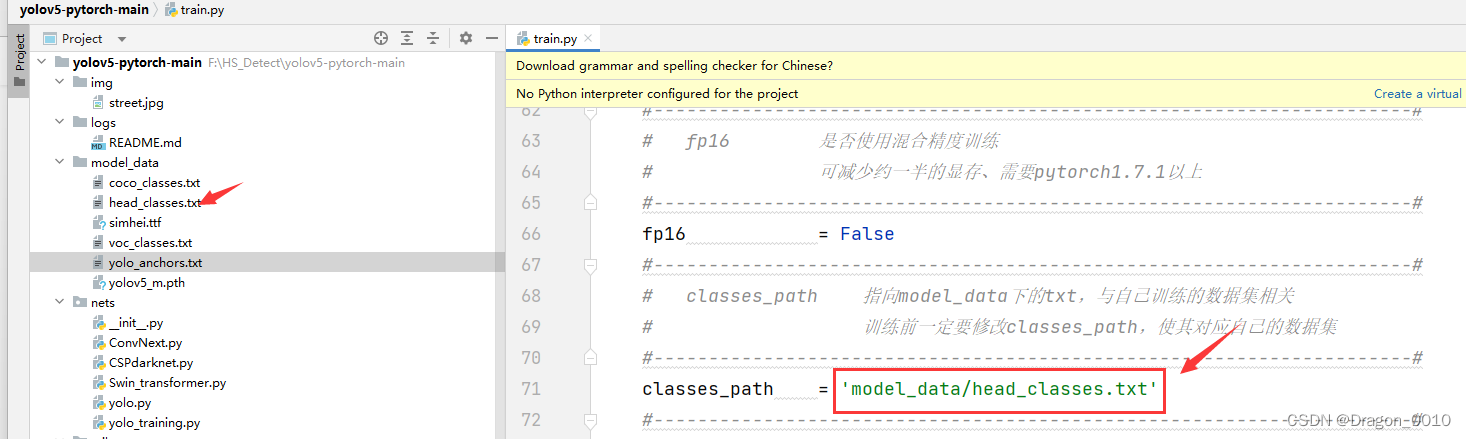
1.源码下载链接 1.yolov5原模型以及权重文件 链接:https://pan.baidu.com/s/1XlvHIxlzJEqp2wlRx5Fb1w 提取码:xtkj 2.训练自己数据集的完整代码 链接:https://pan.baidu.com/s/1xdnah8ZLoT7E1YDm-RiGzQ 提取码:9261 2.训练过程 1.修改class_path为自己数据集的分类结果 2.修改权重文件的路径 继续阅读

Chinchilla:训练计算利用率最优的大语言模型 《Training Compute-Optimal Large Language Models》 论文地址:https://arxiv.org/pdf/2203.15556.pdf 一、简介 近期出现了一些列的大语言模型(Large Language Models, LLM),最大的稠密语言模型已经超过了500B的参数。这些大的自回归transformers已经在各个任务上展现 继续阅读
什么是冥想? 有不少人问过我这个问题,到底什么是冥想,我们为什么要练习冥想? 当你打开百度搜索,或是找资料查询,你看到的答案也各不相同! 有的会说,冥想是专注力的训练;也有的人说,是对呼吸的控制;还会说是内心的训练;也还会有答案说,冥想是自我的修行方法······ 但是,对我来说:如果冥想能够用语言表达,并且能给冥想定义,其实冥想本身就没有了意义! 因为一旦你给冥想定义,就会把冥想做为一个标准,甚至会通过这个标准进行评判,会有了条框的限制 继续阅读
在ChatGPT的训练过程中,使用了Docker等容器技术来支持实现训练过程中不同组件之间的隔离,并且使部署和运行更加快速和可靠。 Docker是一种开源的容器化平台,可以创建、部署和运行应用程序的容器。使用Docker技术,可以先将训练任务需要的环境和软件组件打包到容器镜像中,然后在不同的系统和环境中使用该容器镜像,使系统间的组件隔离,降低不同组件之间产生干扰和冲突的概率,保证训练 继续阅读
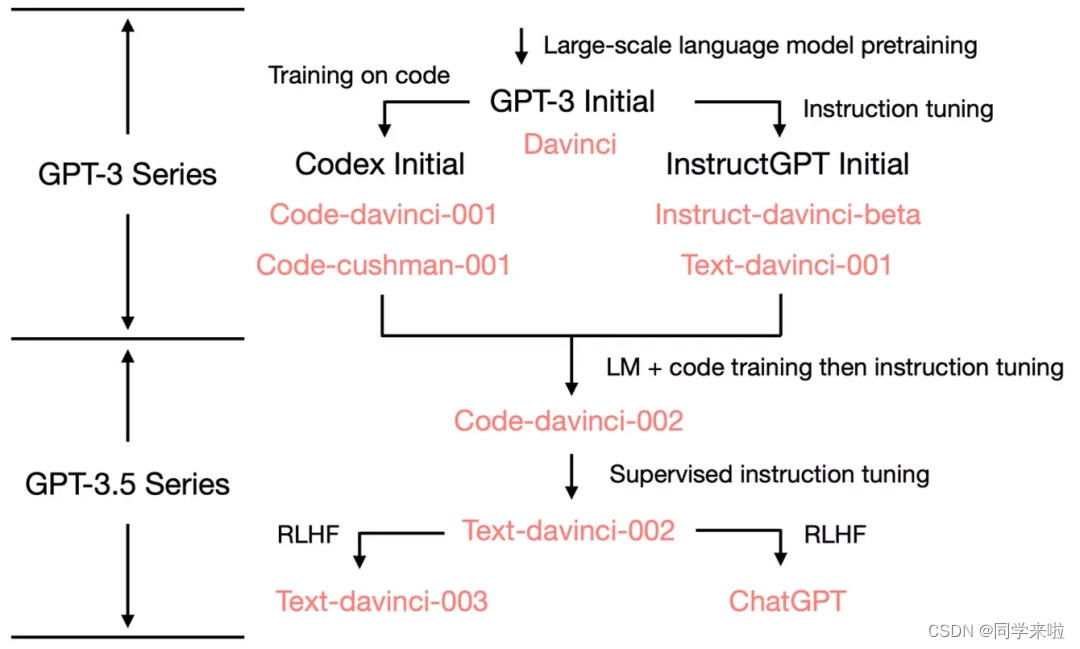
文章目录🐣 一、发展历程🔴 1、基本概念🟠 2、演化过程🐤 二、模型训练机制 🐣 一、发展历程 🔴 1、基本概念 ChatGPT是一个采用基于GPT-3.5(Generative Pre-trained Transformer 3.5)架构开发的大型语言模型,与InstructGPT模型是姊妹模型(sibling model&#x 继续阅读

健身是现在社会热议的话题之一,也是很多的白领选择的方式,一方面白领们忙于工作,但是身体是最重要的,健身的想法和理念也逐渐深入人心,让大家都想拥有个健康完美的体型以及强壮的身体素质。但是面对健身房众多的健身器材,很多人感到迷茫和不知所措,不知道该如何选择,那么现在小编就来告诉你如何计划健身房减肥计划吧。 一、动感单车 专业的健身教练告诉完美,一般建议新会员在体能训练半个月至一个月时,身体机能提升之后再进行这个项目的训练,动感单车的优势 继续阅读

前言近期,ChatGPT成为了全网热议的话题。ChatGPT是一种基于大规模语言模型技术(LLM, large language model)实现的人机对话工具。但是,如果我们想要训练自己的大规模语言模型,有哪些公开的资源可以提供帮助呢?在这个github项目中,人民大学的老师同学们从模型参数(Checkpoints)、语料和代码库三个方面,为 继续阅读
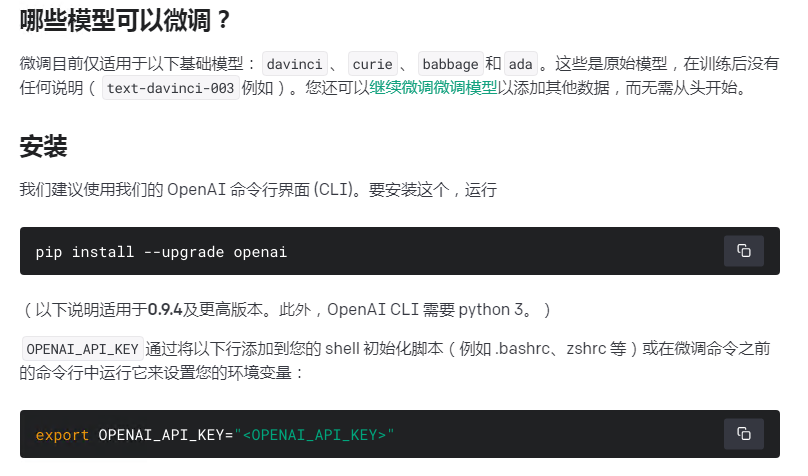
打开VSCode 新建一个工作目录 使用pip install --upgrade openai 配置环境变量: OPENAI_API_KEY=<你的open ai key> windows配置:(需要重启) setx OPENAI_API_KEY "你的open ai key" 准备训练数据集文件: 格式如下: 放到工作目录下比如A.jsonl 使用命令格式化数据: 继续阅读
"ChatGPT3.5" 不是一个官方的、标准的模型版本。可能它是某个团队或个人开发的模型,如果您能提供更多的上下文和信息,我会很高兴为您提供更准确的答案。 通常来说,GPT-3是目前最为先进的通用自然语言处理模型之一,它训练的过程需要大量的计算资源和时间。因此,一般会选择使用云计算平台来进行训练任务。 作为一个通用的模型, GPT-3 被广泛部署在多个云计算平台上,包括&#x 继续阅读

本文尝试用现在最火的chatGPT在工作中提高生产力。 具体背景如下:在训练模型过程中,为了避免资源抢占,我指定了其他的gpu来提高模型训练效率,但是发现训练的时候模型正常,但是在模型预测的时候一直报错,尝试gpu=1,2,3都报错。gpu=0,或者是不设置都不会出错。 预测的时候具体报错内容如下: XGBoostError: b' 继续阅读
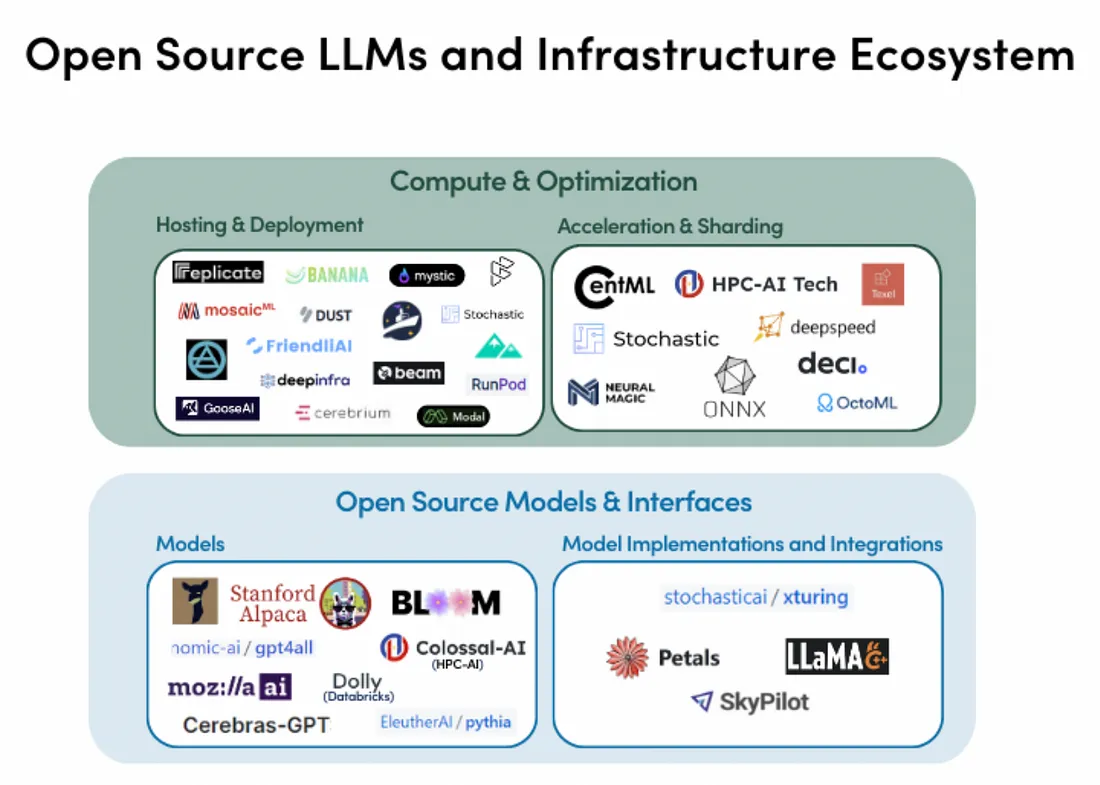
简介 随着数据科学领域的深入发展,大型语言模型—这种能够处理和生成复杂自然语言的精密人工智能系统—逐渐引发了更大的关注。 LLMs是自然语言处理(NLP)中最令人瞩目的突破之一。这些模型有潜力彻底改变从客服到科学研究等各种行业,但是人们对其能力和局限性的理解尚未全面。 LLMs依赖海量的文本数据进行训练,从而能够生成极其准确的预测和回应。像GPT-3和T5这样的LLMs在诸如语言翻译、问答、以及摘要等多个NLP任务中已经 继续阅读