文章目录
- 前言
- 一、ChatGPT是什么?
- 二、ChatGPT的前身InstructGPT论文解读
- 论文下载地址:
- 主要内容:
- 模型训练
- 数据类型
- 结果
- 效果示例
- 总结
前言
现在大火的ChatGPT功能十分强大,不仅可以回答用户问题,编写故事,甚至还可以写代码。ChatGPT跟OpenAI之前发表的InstructGPT使用的模型方法比较类似,只是训练的数据不同,为了探索ChatGPT的原理,笔者找来2022年3月发表的InstructGPT的论文,做了简要的介绍。
一、ChatGPT是什么?
ChatGPT,美国OpenAI 研发的聊天机器人程序 ,于2022年11月30日发布 。ChatGPT是人工智能技术驱动的自然语言处理工具,它能够通过学习和理解人类的语言来进行对话,还能根据聊天的上下文进行互动,真正像人类一样来聊天交流,甚至能完成撰写邮件、视频脚本、文案、翻译、代码,写论文等任务。
二、ChatGPT的前身InstructGPT论文解读
论文下载地址:
https://arxiv.org/abs/2203.02155
主要内容:
这篇文章的主要内容是大型语言模型并不能很好的遵循用户的意图,这些模型生成的内容可能对用户毫无帮助,与用户的期待并不一致。为了解决这个问题,InstructGPT使用引入了人类反馈来训练模型,虽然模型仍然有一些小的错误,但是这种方法给大型语言模型输出结果与人类期望一致提供了未来的研究方向。ChatGPT也是在InstructGPT模型的基础上开发出来的。
模型训练
训练模型主要有三个步骤,论文的配图做了非常详细的说明:
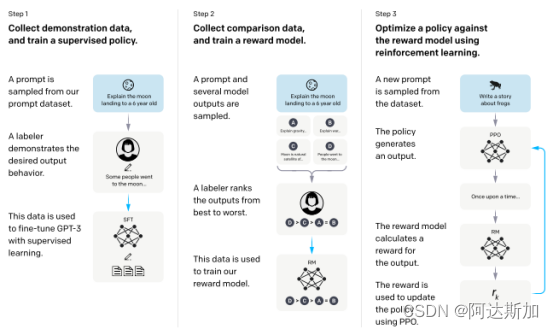
- 步骤1:supervised fine-tuning (SFT)
OpenAI雇佣的数据标注员人工生成问题和答案,通过监督学习使用这个数据来对预先训练好的GPT-3模型进行微调。 - 步骤2:reward model (RM) training
使用不同的模型生成不同的结果,打分员手工对不同的回答打分,然后使用这些数据训练一个激励模型来预测人类更喜欢的结果。 - 步骤3:reinforcement learning via proximal policy optimization (PPO)
将激励模型作为标准,对已生成的模型使用PPO算法进行微调,生成最佳策略。
数据类型
数据的类型主要有三类:
- Plain:标记员随机想出一个任务,确保任务的多样性。
- Few-shot:标记员想出一个指示,并且提供配套的多个查询语句和响应
- User-based:与OpenAI的待开发应用列表里相关的任务
结果
论文主要使用了API分布和公开的NLP数据集两个维度来评价这个模型。
- 1.API分布下的结果

在1.3B,6B和175B的体量数据下,InstructGPT对应的模型PPO-ptx表现均优于其他模型,最受评分员的喜爱。
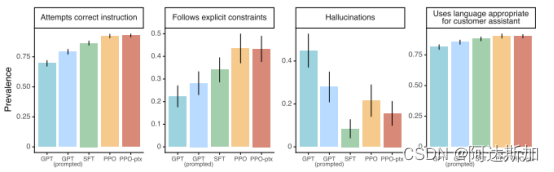

在更细的不同任务类型下和Likert score的打分也是如此。 - 2.NLP数据集上的结果
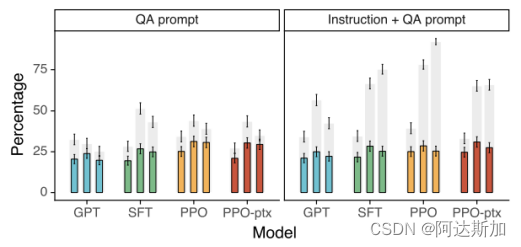
图中的TruthfulQA dataset结果中灰色的柱形代表了诚实度,InstructGPT在诚实度上比GPT-3有所提高。
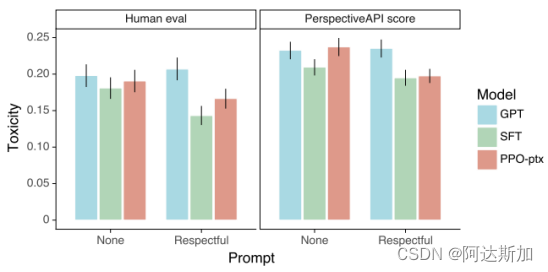
InstructGPT在有毒性测试上相比GPT-3略有提高,但是在偏见上没有提高。
效果示例
经过微调的模型效果非常好,下面贴几张论文中GPT-3和InstructGPT的回答对比示例:

可以处理不同的语言,也可以处理代码数据。


总结
从这篇文章中我们可以看到,预先生成的模型在经过人工反馈训练之后,效果已经比较好了,ChatGPT正是在之前的基础之上,才发展出了惊人的成果。
本文链接:https://my.lmcjl.com/post/10078.html
4 评论