对于NLP领域,本人也是门外汉,就是最近了看到的博文,记录自己的一些体会。
ChatGPT简介
ChatGPT的全称是"Conversational Generative Pre-training Transformer",中文翻译为"对话生成式预训练转换器"。是一种基于自然语言处理的人工智能模型,由OpenAI团队开发,它是一种基于深度学习的语言模型,专门用于对话系统中,旨在使机器人能够自然地与人类进行对话。
ChatGPT的核心技术是GPT(Generative Pre-trained Transformer)模型,这是一种预先训练的自然语言处理模型,它是通过大规模文本数据集的预训练来学习自然语言的语法、语义和上下文关系,从而使得在新的任务中微调时,能够更加高效准确地进行文本生成、摘要、问答等自然语言处理任务。
大白话解释一下就是ChatGPT是在原有预先训练的大模型的基础上,进行一些“微微”的调整就得到了现在强大的能力。
那具体这个大模型有多大,就得提一下GPT系列,也就是生成式预训练模型。现在GPT系列已经到了GPT-3,GPT-4也在路上了,可以看看这个大模型的参数量。
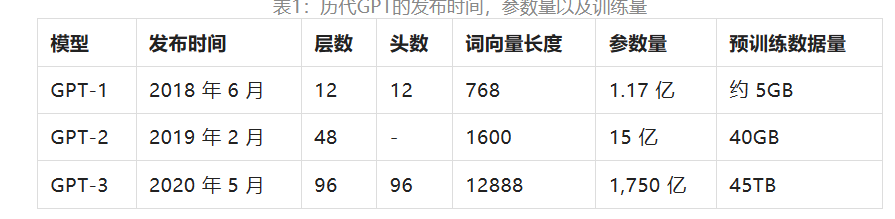
1750亿参数,45TB数据,懂行的不懂行的都能感受到这个大模型是真不小。
那这么多参数,那么多数据,这个大模型岂不是很好了。当然是有不足的,预训练模型自诞生之始,一个备受诟病的问题就是预训练模型的偏见性。因为预训练模型都是通过海量数据在超大参数量级的模型上训练出来的,对比完全由人工规则控制的专家系统来说,预训练模型就像一个黑盒子。没有人能够保证预训练模型不会生成一些包含种族歧视,性别歧视等危险内容,因为它的几十GB甚至几十TB的训练数据里几乎肯定包含类似的训练样本。
换句话说,大数据时代网络上说啥的都有,各种言论都能看到。这些数据也有来自网上收集的,所以大模型很可能看到过这些危险言论,当你问它相关问题的时候,它作为机器可不会“三思而后说”。如果真正要和人们进行多轮交互,什么该说什么不该说就需要好好掂量了。
所以ChatGPT优化的目标有以下三个:
有用的(Helpful),总不能问个问题说出来的都是废话,一点干货都没有
可信的(Honest),不能一本正经的胡说八道
无害的(Harmless),不能有太多危险发言
ChatGPT的优化策略
一句话总结就是:从人类反馈中进行强化学习,先上个图(图为InstructGPT,算法和ChatGPT一致)
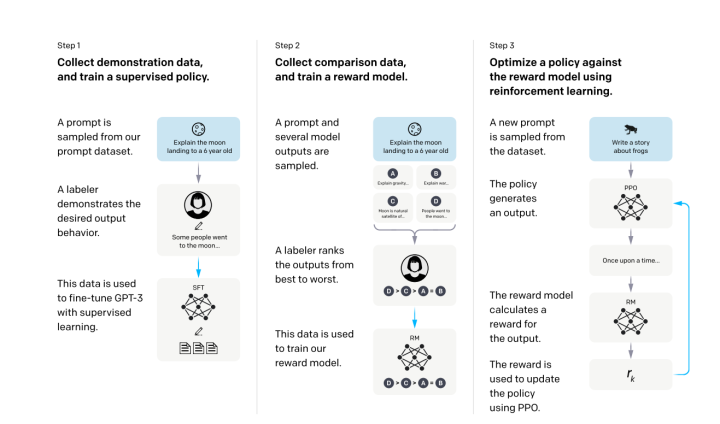
大白话版本:
Step 1就是人工标注信息,比如我要给别人解释谁是高启强,那我就找个看过《狂飙》的人,写一段话介绍高启强是如何熟读孙子兵法,然后一步一步做大做强……然后告诉上面提到的那个GPT-3这个大模型,这样模型就认识了高启强。这个新模型就叫SFT
Step 2 就是如果所有的东西都要人工来进行标注提示,那人工成本太大了,那就换一个方式,给刚才微调的模型SFT输入问题得到一些输出答案,人工对这些答案按好坏进行排序重新训练一个奖励模型。毕竟做排序题肯定比做主观题要快(懂的都懂)
比如你问模型:谁是高启强?模型给出你4个回答:A.鱼贩 B.警察 C.好男人 D.黑社会大哥 假设进行人工排序就是D>A=C>B。也就是告诉模型,他是黑社会大哥的概率比较大,以后再见到他你就认为他是黑社会大哥。
这个奖励模型就是说你给我你的问题,你再给我你的输出,然后模型就给他一个分数,这个分数要满足我的人工排序
Step3就是继续去调整前面的SFT模型,使得它生成的答案能够尽量得到一个比较高的分数。就是每次我让SFT生成一个答案,然后丢到第二步里的奖励模型打个分数,然后根据这个分数进行调整,使得它生成的答案分数更高,比如第一次SFT说高启强是警察,因为警察这个答案的分数很低,就像你告诉模型这个答案不对,这样不停的迭代直到模型告诉你高启强是黑社会大哥
第三步使用了强化学习,强化学习简单来说就是试错。举个例子,当我们在玩一款游戏时,我们需要做出一系列的决策才能获得游戏的最高得分。在这个过程中,我们会通过不断的试错来学习什么样的决策能够获得更高的得分。这个过程就类似于强化学习中的智能体与环境进行交互,在每个状态下选择一个动作,从环境中获取一个奖励,然后更新其策略以获得更大的奖励。
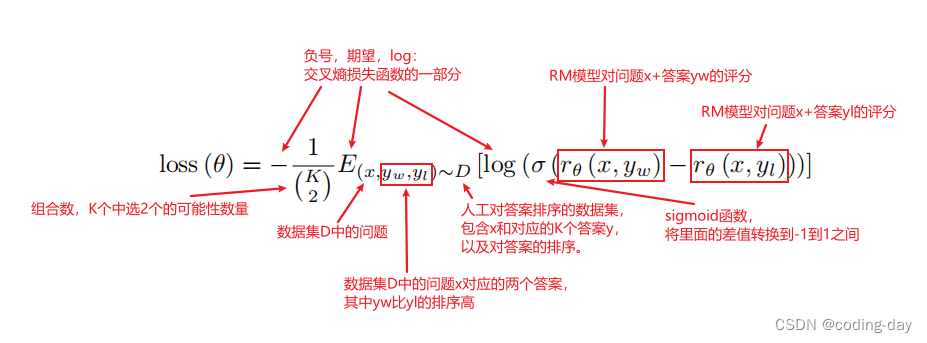
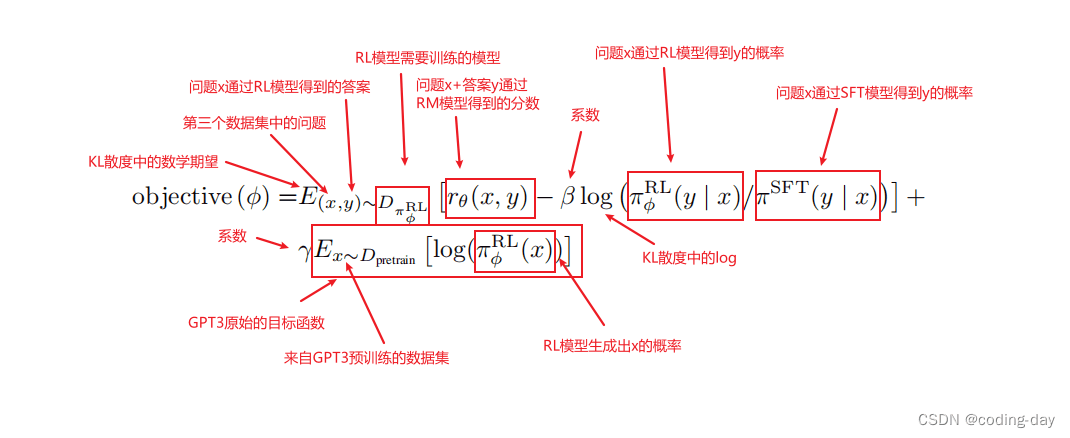
高级版本(涉及到公式和专业术语,可跳过):这是今天在CSDN上看到的一篇文章,讲得挺好,链接放上,顺带复制两张公式图,膜拜大佬
奖励模型损失函数:
强化学习目标函数:
总结
其实我个人觉得ChatGPT之所以那么强大可以归结于两句话:
1、大力出奇迹:1750亿的参数量巨大,并且GPT-3本身就具有非常强的泛化能力和生成能力,基于此基础上的ChatGPT“起跑线”就很高。
2、多点人工,多点智能:在对模型进行调整的过程中用到了使用了相应的人工标注作为指导,相当于有了“老师”,相比于原始的GPT简单依靠无标注的数据效果自然会好一些。
当然,ChatGPT也有不足,有时候ChatGPT会给出一些荒谬的输出,虽然ChatGPT使用了人类反馈,但限于人力资源有限。影响模型效果最大的还是有监督的语言模型任务,人类只是起到了纠正作用。所以很有可能受限于纠正数据的有限,或是有监督任务的误导(只考虑模型的输出,没考虑人类想要什么),导致它生成内容的不真实。就像一个学生,虽然有老师对他指导,但也不能确定学生可以学会所有知识点。
本文链接:https://my.lmcjl.com/post/10817.html
4 评论